こんにちは、20新卒で入社した上森です。
早いもので入社してからもう2年半あまりが経ってしまいました。
そろそろ引越しして広い部屋でインテリアを凝りたいなと思ってます。
さて、今回はタイトルの通り、Workload Identity連携を使ったLambdaをTerraformで構築した話を紹介させていただきます。
また、LambdaをTypeScriptで書いたりしてるので、TypeScriptで書いたLambdaをTerraformでデプロイしたい!と思っている方にも見ていただけたら嬉しいです。
システムの構成や選定理由について
概要
今回構築したシステムは、AWSからGCPにアクセスしてデータを取得し、RDSに入れ込むという社内向けのAPIです。
ざっくり今回使用したサービス群は以下の通りです。
- API周り
- Lambda
- API Gateway
- 認証周り
- Workload Identity
- IaCツール
- Terraform
構成図
今回構築したシステムは以下のような構成になっています。
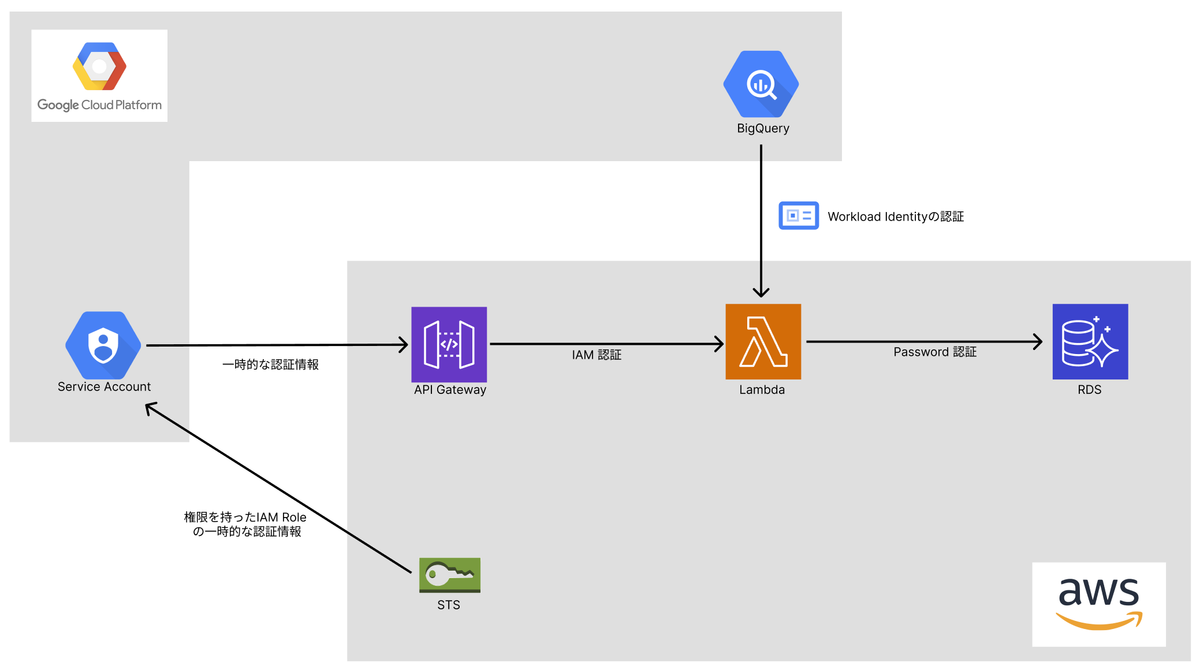
基本的な処理の流れは、以下のようになっています
- GCPのサービスアカウントからAWS STSを利用して、AWS IAM Roleの一時認証情報を取得する
- 取得した認証情報を使ってAPI Gateway経由でLambda関数を実行する
- LambdaでWorkload Identityを利用してGCP BigQueryからデータを取得してAWS RDSにデータを入れ込む
Lambdaを選んだ理由
今回、APIを作成するにあたってLambdaを利用しました。
Lambdaを採用することとなった決め手は、以下の点です。
- 一般的な構成なので、ググったときに情報が多い。
- 他プロダクトにも知見が溜まっている。
- API Gatewayと組み合わせることで、IAMなどによるアクセス制限が容易である。
Lambda以外の候補としてはApp Runnerなどがありました。
採用しなかった理由としては、以下の通りです。
- アクセス制限をかけるのが難しい(App Runnerの前段にCloudFrontを立てWAFを紐付けることはできそう)
- Lambdaに比べると情報が少ない
また、Lambdaの開発言語にTypeScriptを選んだ理由としては、自分のチームの技術スタック的に合っていたからです。
IaCツールとしてTerraformを選んだ理由
IaCツールとしてはTerraformを利用しました。
Terraformを採用することとなった決め手は、以下の点です。
- 既にプロダクトで運用しているので知見がある。
- API GatewayやIAM周りのAWSリソースも作成する必要があるなら一緒に管理した方が良い。
Terraform以外のIaCツールの候補としては、CloudFormationやCDK、あとはLambda専用のデプロイツールであるlambrollなどがありました。
それらを採用しなかった理由としては、以下の通りです。
- ツール自体の学習コストが高いので、工数がかかってしまいスケジュール面で問題があった
- Lambdaのみ管理が分かれてしまうことになるので、運用・保守面でデメリットがある
TypeScriptで書かれたLambda関数をTerraformでデプロイする方法
ディレクトリ構成は以下の通りです。
. ├── hoge_fucntion │ ├── dist │ ├── layers │ │ └── nodejs │ ├── src │ │ ├── entity │ │ │ └── Hoge.ts │ │ ├── data-source.ts │ │ └── index.ts │ ├── .gitignore │ ├── .prettierrc │ ├── package.json │ ├── tsconfig.json │ └── yarn.lock ├── .terraform.lock.hcl ├── api_gateway.tf ├── iam_role.tf ├── lambda.tf ├── route53.tf ├── main.tf ├── version.tf └── provider.tf
terraform applyした時のLambda関数のデプロイ処理の流れは以下の通りです。
hoge_function/src/以下のtsファイルをトランスパイルしてhoge_function/dist/以下にjsファイルを作成するhoge_function/dist/以下にあるjsファイルをZIP圧縮するhoge_function/layers/nodejs/以下でLambda関数で使用するパッケージをインストールするhoge_function/layers/以下にあるパッケージをZIP圧縮する- 2と4で作成したZIPファイルを指定してLambda関数をデプロイする
トランスパイルとZIP圧縮については工夫が必要なので、実際に書いたコードをもとに以下で説明していきます。
トランスパイル
トランスパイルの処理はnull_resourceで実行しています。
resource "null_resource" "lambda_hoge_build" { triggers = { always_run = timestamp() } provisioner "local-exec" { command = <<-EOF rm -rf ${path.module}/hoge_function/dist/index.js && \ cd ${path.module}/hoge_function && \ yarn install --no-lockfile --mutex network && \ yarn tsc -p tsconfig.json EOF } }
triggersのパラメータの更新タイミングで実行するかどうか指定できますが、今回はalways_run = timestamp()で絶対に毎回実行されるようにしています。
ZIP圧縮
ZIP圧縮の処理はarchive_fileで実行しています。
data "archive_file" "lambda_hoge" { type = "zip" source_dir = "${path.module}/hoge_function/dist" output_path = "${path.module}/hoge_function.zip" depends_on = [null_resource.lambda_hoge_build] }
depends_onでトランスパイルの処理を指定して順序制御をしないと、トランスパイルの処理より前に実行される可能性があり、エラーが起きるので注意です。
Lambda LayerにアップロードするZIPファイルもnull_resourceとarchive_fileを使用して同様に作成します。
Workload Identity連携について
今回、LambdaからGCPのBigQueryにアクセスする方法としてWorkload Identityを利用しました。
GCPのサービスアカウントキーをLambda関数の環境変数や、AWS Systems Managerのパラメータストアに置いておいて、GCPにアクセスする方法もあるのですが、キーの管理をしたくなかったのでWorkload Identityを利用してGCPにアクセスできるようにしました。
キーの管理が不要になることによって以下のようなメリットがありました。
- キーの漏洩リスクがなくなる
- キーのローテーションが必要なくなる
Workload Identityの設定方法
Workload Identity連携を使用してLambdaからGCPにアクセスできるようにするためには、GCP側とAWS側のそれぞれで準備が必要になります。
GCP側の準備
1. プールを作成する
まず、GCPのコンソールから「Workload Identity連携」を選択し、「プールを作成」から作成します。 プールの名前などは好きなものを付けてください。
2. プロバイダを追加する
同じくコンソールの「プロバイダを追加」から先ほど作成したプールを選択して作成してください。
その際に「プロバイダの選択」は「AWS」を選択してください。
名前は好きなもので大丈夫ですが、「AWSアカウントID」には連携先のAWSアカウントIDを入力しましょう。
ここの設定で各種条件(IAMロール名など)によるフィルタ設定ができますが、今回はアカウントID全体に対して許可しました。
3. サービスアカウントの紐付け
作成したプールの詳細画面の「アクセスを許可」から紐付けたいサービスアカウントを選択してください。
プリンシパルの選択は「プール内のすべてのID」を選択しました。
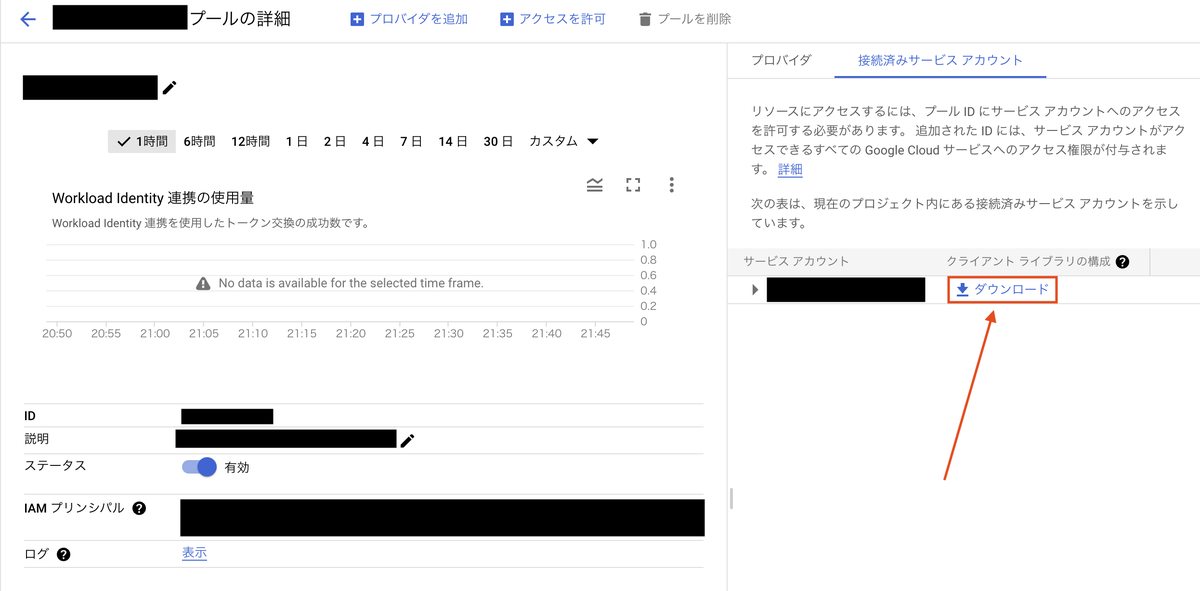
4. JSONファイルをDLする
AWS側でWorkload Identity連携するためにJSONファイルをDLする必要があります。
コンソールではダウンロード元が分かりにくいので注意です。
これでGCP側の準備は完了です。
AWS Lambda側の準備
1. 先ほどDLしたJSONファイルをLambda関数から呼び出せるようにする
今回はAWS Systems ManagerのパラメータストアにJSONファイルの中身を置いておき、関数内から取得するようにしました。
LambdaのアップロードパッケージにJSONファイルを含め、環境変数にファイルのパスを設定しておき、関数内で取得するのも良さそうです。
2. コーディング
下に書いているのはあくまでイメージですが、以下のようなコードで簡単にBigQueryにアクセスすることができます。
import { BigQuery } from "@google-cloud/bigquery"; import { SSMClient, GetParameterCommand } from "@aws-sdk/client-ssm"; import { APIGatewayEvent } from "aws-lambda"; // 環境変数から値を取得 const gcpCredentialsParameter = process.env.GCP_CREDENTIALS_PARAMETER; export const handler = async (event: APIGatewayEvent) => { // Systems Manager パラメータストアから値を取得 const client = new SSMClient({ region: "ap-northeast-1" }); const gcpCredentialsCommand = new GetParameterCommand({ Name: gcpCredentialsParameter, WithDecryption: true, }); const gcpCredentialsJson = await client.send(gcpCredentialsCommand); // BigQueryクライアントの初期化 const projectId = "GCPのプロジェクト名"; const bigquery = new BigQuery({ projectId: projectId, credentials: JSON.parse(gcpCredentialsJson), }); // 実際のクエリ部分 const query = `SELECT hoge-column FROM hoge-project.hoge-dataset.hoge-table`; const result = await bigquery.query({ query: query, useLegacySql: false, }); console.log(result); return { statusCode: 200, headers: { "Content-Type": "application/json", }, body: "success", }; };
これでLambda側の準備は完了です。
あとは好きなようにBigQueryから取得してきたデータを加工したり、RDSに入れ込む処理を書いたりしてみてください!
苦労したところ
Terraformによるデプロイでたくさん詰まりました。
あとは、今回記事では触れていませんがBiqQueryからデータを取得する処理を実装する過程で試行錯誤したり。
トランスパイルやyarn installが失敗したり、実行順序の制御がうまくいかなかったり。
とにかく初めてのことばかりだったので色々模索しながらやってました。
まとめ
さて、今回はWorkload Identity連携を使ったLambdaをTerraformで構築した話を紹介させていただきました。
慣れないことばかりで大変でしたが学ぶものはとても多かったので有意義な経験ができました。
読んでいただいた人に少しでも助けになれば幸いです。
それでは!