1 ヶ月ぶりに記事の場へ帰ってきました菊池です。
今回は前回の記事「データ基盤をサーバーレスで構築したので概要を紹介」で紹介したシステムで Workflows をどのように使っているのか、概要を紹介したいと思います。よろしくお願いいたします。ちなみに結構満足して使ってます。
Workflows そのものについては書いていないので、Workflows について知りたい方は以下の記事や公式ドキュメント等を参照してください。
とはいえ、自分の言葉で Workflows を簡単に紹介すると、YAML でワークフローを記述してサーバーレスで動かすサービスです。イメージ的には GitHub Actions でワークフローの YAML を書いて動かしているのに近い感じがしています。Workflows から Google Cloud の各種サービスを コネクタ を使って動かしたり、標準ライブラリ の http を使って外部 API を呼び出したりすることができます。
また、順次・選択・繰り返しを記述できたり、外部から引数を受け取れたり、ワークフローをサブワークフローに分割して記述できたりします。以下の Syntax cheat sheet でなんとなく雰囲気を感じていただけるかもしれません。
Google Cloud Workflows や AWS Step Functions を見ると「クラウド時代のバッチ処理は YAML や JSON で記述するのか」という印象持ちますよね。僕だけでしょうか。
処理の概要
前回紹介したサーバーレスデータ基盤では大きく分けて、以下の二つのワークフローで構成されています。
- データ収集ワークフロー
- データインポートワークフロー
それでは、それぞれの詳細について紹介していきましょう。
データ収集ワークフロー
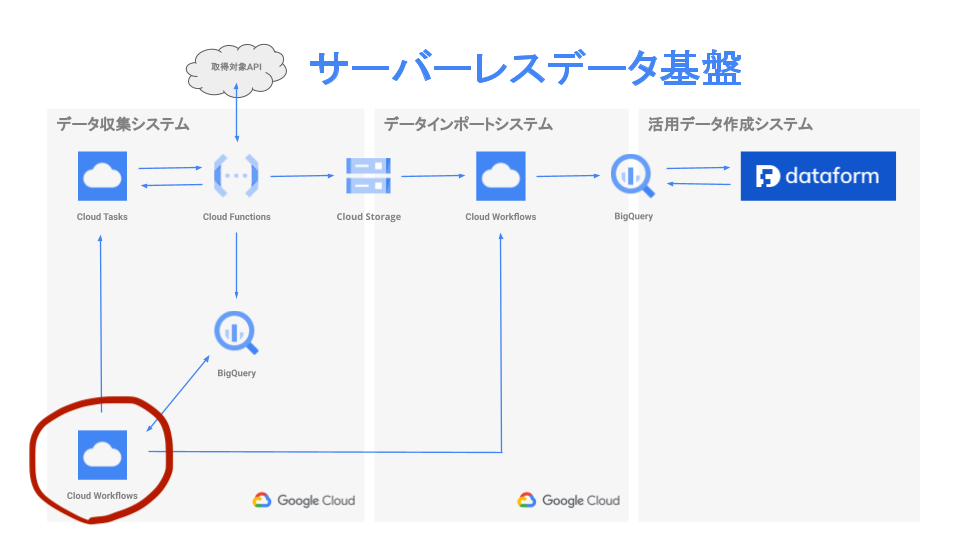
このワークフローは取得対象 API から必要なデータを収集して Cloud Storage に保存する処理を担当しています。実際はもう少し込み入った処理もありますが、おおまかな処理の概要は以下の通りです。
- 初期設定
- Cloud Tasks に全てのデータ取得処理の始祖となるタスクを登録
- BigQuery のデータ取得状況テーブルを定期的に確認して、全ての実行待ち Cloud Tasks が無くなるまで待つポーリングループ
- 後述する「データインポートワークフロー」を実行
- 後処理
概要の 2. にある始祖となるタスクが呼び出す Cloud Functions は、まず取得対象 API から親データのリストを取得します。次に取得した親データのリストから、それぞれの子データを取得する後続のタスクを Cloud Tasks に登録します。文字だけだとわかりにくいかもしれませんが Cloud Tasks を経由して再帰的に自分自身の Cloud Functions を呼び出すような実装になっています。
概要の 3. にある BigQuery のデータ取得状況テーブルには、全てのデータ取得タスクの実行状態が Cloud Functions から以下の内容でストリーミングインサートされています。
- Cloud Tasks へのタスク登録
- Cloud Functions のタスク実行開始
- Cloud Functions のタスク実行(正常|異常)終了
ワークフローから、この「タスク登録数」と「タスク実行終了数」の数を確認するポーリングループで、全てのデータ取得処理が完了したかチェックしています。
データインポートワークフロー
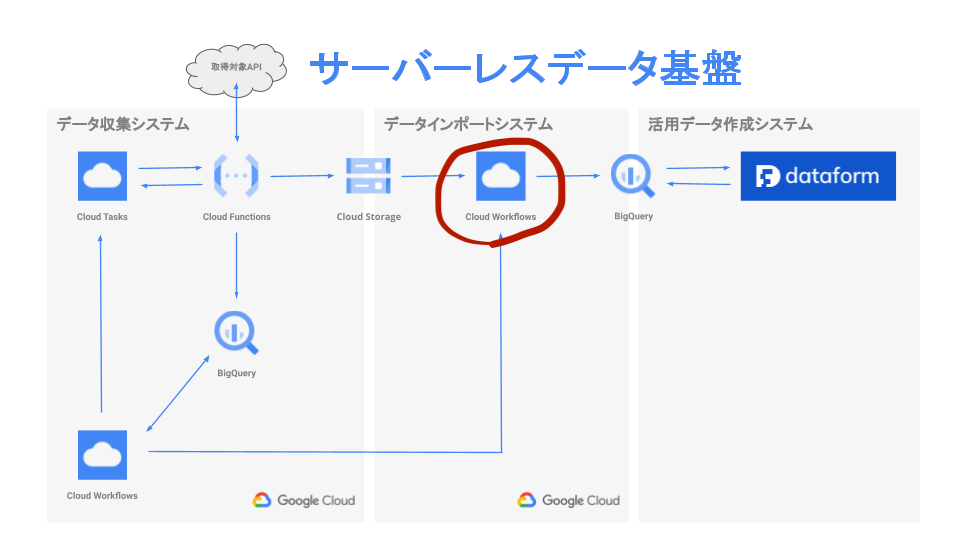
このワークフローはデータ収集システムが Cloud Storage に格納した、JSON や CSV ファイルを BigQuery にインポートする処理を担当しています。おおまかな処理の概要は以下の通りです。
- 初期設定
- Cloud Storage のパス毎に BigQuery のテーブルにデータをインポート
概要の 2. の部分は googleapis.bigquery.v2.jobs.insert を使って実装しています。schema の mode に RECORD や REPEATED を指定することで、JSON のオブジェクトや配列も、そのまま BigQuery にインポートすることができます。
気に入っているところ
使ってみての感想で、まずは気に入っているところは以下の通りです。
- とても安価
- デプロイが早い
- 最長実行時間 1 年
料金はほんとに安くて、これはもうほとんど無料じゃないの? というぐらいに安く使わせてもらっています。
また、デプロイコマンドを実行してすぐに実行できるぐらいにデプロイが早いです。これが Cloud Functions だとデプロイを開始してから実行できるまで数分待つ感じですが、Workflows はデプロイがあっという間に完了するので、すぐに動作確認することができます。サクサクです。
Cloud Functions にしても Cloud Run にしても、サーバーレスで時間のかかる処理を動かそうとすると、実行時間の制限があってどうしたものかとなりますよね。Workflows は実行時間の制限を最長 1 年まで設定できるので余裕です。
ちょっと気になったところ
基本的には満足している Workflows ですが、ooh! そうなのかとなったポイントをいくつか紹介しておきます。
- メモリー制限厳しめ
- インポート時にキャストしたくなる
- ときどき BigQuery への QUERY が失敗した
クラウドサービスを順番に起動するワークフローとして使っている分には、メモリー制限が問題になることはありませんでした。
しかしながら、データインポートワークフローでスキーマに大量のフィールドを設定したところ、実行時にメモリー制限によってエラーが発生し実行が中断することがありました。このため、スキーマ定義を分割して複数のインポート先テーブルを設定することでエラーを回避しています。
これに関しては、構築時のメモリー制限は 64KB でかなり厳しめでしたが、最近 256KB まで制限が緩和されたので今ならエラーにならないかもしれません。
同じくデータインポートワークフローですが、取得した JSON データの不備で同じ項目なのにファイルによって文字列だったり数値だったりする場合が稀にあります。困ったもんです。スキーマ定義で文字列と型指定すると数値が来た場合にエラーとなり、数値と型指定すると文字列で来た場合にエラーとなり。この程度だったら、インポート時に文字列にキャストできたらどんなに楽だろうと思った。
データ取得状況をチェックするために googleapis.bigquery.v2.jobs.query を使って BigQuery のデータ取得状況テーブルを参照していますが、時々稀に値が返らない場面に遭遇しました。このため、値が返ってこない場合は一定時間待って再実行するようなクエリーのリトライ処理を Workflows で実装しています。自分の使い方に問題があるのかも。
感想
YAML でワークフローを記述するのってどんな感じなのかな? と使う前は思っていましたが、使ってみるとそこまで抵抗感はありませんでした。定義で済むなら楽だなと思えてきます。
ひょっとしたらデータ取得システムの Cloud Functions 部分も Workflows で書けちゃうのでは!? なんて興味本位で書いて動かしてみたりもしましたが、あっさりメモリー不足で撃沈したので「そういう用途じゃないのね」ととてもよく理解できました笑
クラウドサービスのワークフローに Workflows いいと思います。
今回の記事は以上となります。それではみなさんごきげんよう。菊池でした。