こんにちは、天津です。
今回はAWS Glue(Python)からBigQueryへのアクセスおよびデータ転送についてご紹介します。
モチベーション
当社にはAWSにてS3およびAWS Glue、その他データストアを使用して構築されたデータ分析用の環境があります。
今後、その環境をBigQueryへ移行することが検討されていたため、その一環でAWS GlueからBigQueryへアクセスする方法を検証してみました。
AWS S3からBigQueryへのデータ転送手法について
そもそもAWS S3からBigQueryへデータを転送するには複数の方法があります。
- Spark用BigQueryコネクタの使用
- BigQuery APIへの直接アクセス
- CData社のBigQueryコネクタ(JDBC)の使用
- EC2などからgcloud SDK、bqコマンドなどを利用
- S3からGCSへBigquery Transfer Serviceを利用して転送し、GCSからBigQueryにロード
今回は既存AWS Glue Jobのスクリプト(python)を活かしつつ、コストを掛けない手法として Spark用BigQueryコネクタの使用 を選択・検証しました。
Spark用BigQueryコネクタの検証
情報源など
下記のドキュメントを参考にしています。
BigQuery コネクタを Spark と使用する | Dataproc ドキュメント | Google Cloud
また、Spark用BigQueryコネクタはデータ転送時にGCSを経由させるため、下記を参照にGCS用コネクタも利用します。
Cloud Storage コネクタのインストール | Dataproc ドキュメント | Google Cloud
いずれもGCP内で使用する場合のドキュメントであり、今回はAWSから使用するため認証関連については追加する必要があります。
実装
続いて実装について記載します。
スクリプト
早速ですが、スクリプトです。python 3.7.8で記述しています。
今回はAWS GlueからBigQueryへ接続することを検証したいので、データもBigQueryから取得し、別テーブルを作成します。
取得するデータはpublic datasetのcovid-19, 日本のものを使用します
SQL workspace – BigQuery – Google Cloud Platform
""" glue to bigquery """ # pylint: disable=unused-import,unused-wildcard-import,wildcard-import import sys from pyspark.context import SparkContext from pyspark.sql import SparkSession from awsglue.transforms import * from awsglue.utils import getResolvedOptions from awsglue.context import GlueContext from awsglue.dynamicframe import DynamicFrame from awsglue.job import Job # パラメータ設定 BQ_CREDENTIAL_FILE = "auth.json" TEMPORARY_GCS_BUCKET = "amatsu-test" BQ_PROJECT_FROM = "bigquery-public-data" BQ_DATASET_FROM = "covid19_public_forecasts" BQ_TABLE_FROM = "japan_prefecture_28d" BQ_PROJECT = "amatsu-verification" BQ_DATASET = "amatsu_test" BQ_TABLE = "japan_prefecture_28d" # 初期設定 args = getResolvedOptions(sys.argv, ['JOB_NAME']) sparkContext = SparkContext() glueContext = GlueContext(sparkContext) glueJob = Job(glueContext) glueJob.init(args['JOB_NAME'], args) # SparkSessionの作成 sparkSession = glueContext.spark_session spark = SparkSession.builder.appName('Query Results').getOrCreate() # BQコネクタでまずデータをload BQ_FULL_PATH_FROM = ".".join( [BQ_PROJECT_FROM, BQ_DATASET_FROM, BQ_TABLE_FROM]) df = spark.read.format("bigquery")\ .option("project", BQ_PROJECT)\ .option("parentProject", BQ_PROJECT)\ .option("credentialsFile", BQ_CREDENTIAL_FILE)\ .load(BQ_FULL_PATH_FROM) # GCSの設定 # pylint: disable=protected-access spark._jsc.hadoopConfiguration().set( 'fs.AbstractFileSystem.gs.impl', 'com.google.cloud.hadoop.fs.gcs.GoogleHadoopFS') spark._jsc.hadoopConfiguration().set( 'fs.gs.impl', 'com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem') spark._jsc.hadoopConfiguration().set('fs.gs.project.id', BQ_PROJECT) spark._jsc.hadoopConfiguration().set('fs.gs.auth.service.account.enable', 'true') spark._jsc.hadoopConfiguration().set( 'google.cloud.auth.service.account.json.keyfile', BQ_CREDENTIAL_FILE) # BQへ送信(GCSからロード) BQ_FULL_PATH_TO = ".".join( [BQ_PROJECT, BQ_DATASET, BQ_TABLE]) df.write.format("bigquery")\ .option("project", BQ_PROJECT)\ .option("parentProject", BQ_PROJECT)\ .option("credentialsFile", BQ_CREDENTIAL_FILE)\ .option("temporaryGcsBucket", TEMPORARY_GCS_BUCKET)\ .mode("overwrite")\ .save(BQ_FULL_PATH_TO) glueJob.commit()
特に難しいところはありませんが、GCSを使用するためSparkSessionにGCS関連の設定と認証ファイルを与えている点がポイントです。
なお、認証情報の設定方法については下記を参考にさせていただきました。ありがとうございます。
【Spark】pysparkからS3に接続する - Qiita
動作確認
では実際に動作確認してみますが、まずは事前準備から。
事前準備(コネクタ)
事前に2点のコネクタをライブラリとしてDLします。
今回の検証時には下記を使用しました。
- BigQueryコネクタ
- GCSコネクタ
上記についてのポイント
- BigQueryコネクタは依存関係込みのものを使用する
spark-bigquery-with-dependencies_2.11-0.16.1.jarのように-with-dependenciesがファイル名に付与されているものを使用する- 上記以外の場合、実行時に依存関係が解決できずエラーとなる
- GCSコネクタも同様に依存関係解決済みのものを使用する
事前準備(GCPのクレデンシャルの取得)
GCPにてサービスアカウントのクレデンシャルjsonファイルを取得します(auth.json)。
また、サービスアカウントにはBigQuery管理者、GCS管理者の権限を付与しています。
事前準備(実行環境)
また、動作確認には当社の渡瀬がAWS Glue の開発エンドポイントがそこそこお高いのでローカル開発環境を用意しました で紹介されている Dockerfile を元に作成した aws-glue-libs入のdocker image を使用していきます。
docker-compose.ymlを準備します。
--- version: '3.4' services: app: image: ywatase/awsgluelibs:centos7 tty: true stdin_open: true volumes: - ./:/app:cached
この準備でディレクトリ内は下記のような形になります。
glue_to_bq ├── docker-compose.yml ├── glue_to_bq.py ├── auth.json ├── gcs-connector-hadoop2-latest.jar └── spark-bigquery-with-dependencies_2.11-0.16.1.jar
実行
事前準備ができたのでdocker-composeを実行しコンテナ内に入ります。
$ docker-compose up -d app $ docker-compose exec app bash
実行してみましょう。
$ cd /app $ /aws-glue-libs/bin/gluesparksubmit --jars ./gcs-connector-hadoop2-latest.jar,spark-bigquery-with-dependencies_2.11-0.16.1.jar glue_to_bq.py --JOB_NAME glue_to_bq
ログは割愛しますが、エラーなく動作しました。
ではBigQueryを確認してみます。
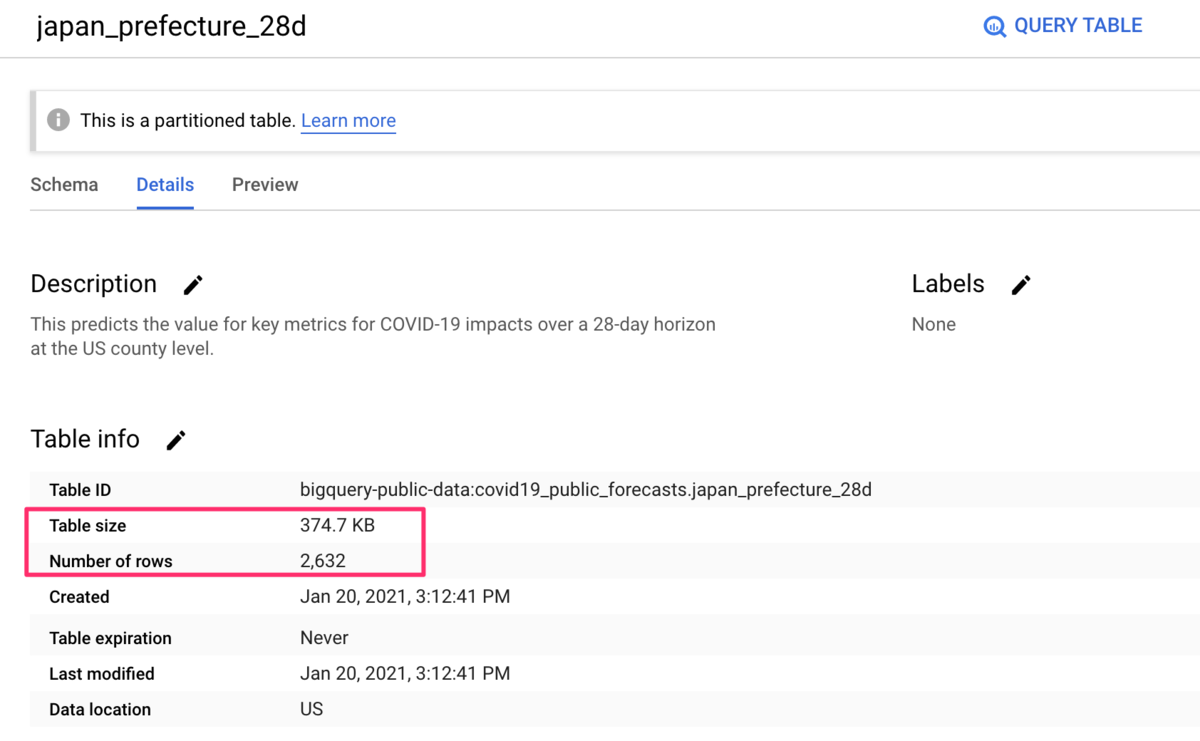
送信元
送信先
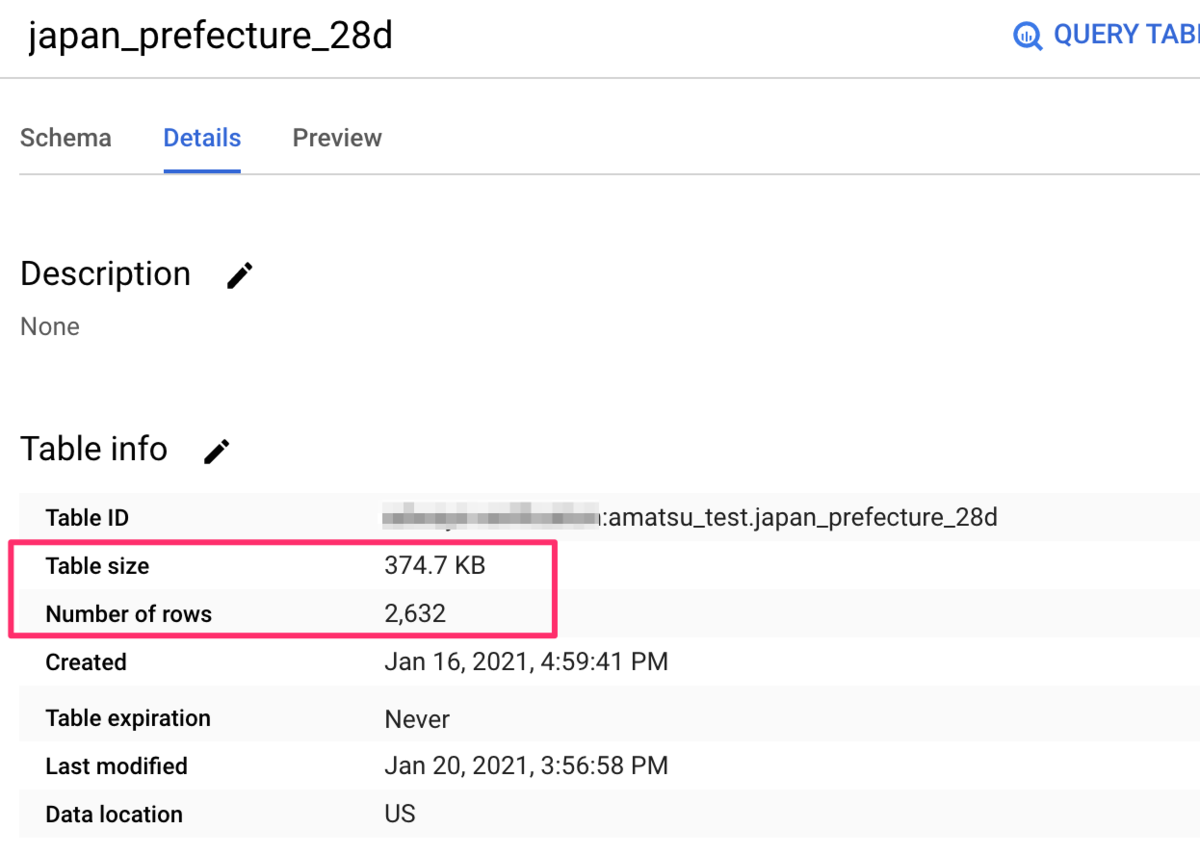
送信先のテーブルが作成され、送信元と送信先で件数が一致しているようです。
動作確認はバッチリです。
AWS Glueでのjob作成
AWS Glueにjob作成し動作を確認します。
動作確認方法などは割愛しますが、登録時のポイントは下記のとおりです。
- GCP認証ファイルはS3に配置し、
参照されるファイルパスにて指定する(s3://xxxxx/auth.json 形式) - コネクタもS3に配置し、
依存JARSパスにて指定する(s3://xxxxx/xxxx.jar 形式) - 複数指定はカンマ区切りで指定
まとめ
AWS GlueからBigQueryへのアクセスは情報が断片的にしか存在せず、たどり着くのが厄介でしたが動作することは確認できました。
今回の検証ではデータをBigQueryから取得していますが、もちろんS3から取得し変換してBigQueryへ送信することも可能です。
少しニッチな情報でしたが参考になれば幸いです。
最後までお読みいただきありがとうございました。