初めまして!エージェンシー事業でアプリケーションエンジニアをしている22年新卒入社の内原です。
今回は、私が所属するチームのシステム(AWS ECS/Fargate)にWorkload Identityを導入してGCPのさまざまなサービスへサービスアカウントキーを利用せずにアクセスする方法について紹介と思います。
背景
私の所属するチームでは、ECSタスクスケージューリング機能を利用して毎日、定期実行を行っているシステムがあります。
正確には、整形済み広告データをデータマートとしてBigQueryで管理しており、それらのデータをTableau(BIツール)で既に提供しているデータにHyper APIを利用して追記する処理を行っています。
※今回は、AWSのサービスからGCPサービスへの認証にWorkload Identityを導入した記事になるため、TableauのHyper APIやTableauへの認証については割愛させていただきます。
 実際のシステムの基本的な処理の流れは、以下のようになっています。
実際のシステムの基本的な処理の流れは、以下のようになっています。
- ECSタスクからBigQueryにあるデータマートのViewへアクセス
- Cloud APIを利用しデータマート(View)のデータをGCSへエクスポート
- エクスポートされたデータをFargateのコンテナへダウンロード
- ダウンロードしたデータを元に抽出ファイルを作成し、Tableauへパブリッシュ
これらの処理において、ECSからBigQueryとGCSへのアクセスが必要となります。当然AWSサービスからGCPサービスへのアクセスとなるため、認証を通す必要があります(もちろんTableauへも)。
課題
今までは、ECSからGCPへのアクセスはサービスアカウントキーをAWS Systems Manager(SSM)のパラメータストアで管理し、ECSのタスク定義時にサービスアカウントキーを環境変数にセットしていました。しかし、キーはサービスアカウントから払い出された認証情報であり、漏洩リスクや管理の煩雑さがあるため利用を避けたいです。
そこで、Workload Identity連携を用いることでサービスアカウントキーを利用することなく、AWSなどのクラウドサービスからGCPサービスを利用することができます。
Workload Identityとは
オンプレミス、AWS、Azureなどで実行するワークロードで外部IDプロバイダ(IdP)と連携し、サービスアカウントキーを使用せずにGoogle Cloudリソースを呼び出すことができます。ワークロードはセキュリティトークンサービス(STS)エンドポイントを呼び出し、IdPから取得した認証トークンをGCPアクセストークンと交換します。このアクセストークンを用いてサービスアカウントになりすまし、GCPリソースにアクセスするサービスアカウントの権限を持つことになります。引用元:Workload Identity 連携の構成
基礎編: Workload Identityの導入方法
本題のWorkload Identityの導入について説明していきます。Workload Identityを導入する際に、AWS・GCPでそれぞれ設定が必要となります。また、前提としてサービスアカウントキー、IAMユーザーは作成してあるものとします。
設定の流れ
- AWS: (必要に応じて)ECSタスクロール・ECSタスク実行ロールにアタッチするためのIAMロールを作成
- GCP: Workload Identity PoolとWorkload Identity Providerの作成
- GCP: Workload Identity Poolの権限を借用するための権限とGCPサービスを利用するために必要な権限を付与
- GCP: 認証構成ファイルを取得
- AWS: 認証構成ファイルのパスを環境変数にセットし、アプリケーションを実行
1. IAMロールの作成
ECSタスクロール・タスク実行ロールにアタッチするためのIAMロールを作成します。今回はaccess2bqというIAMロールを作成しました。別サービスからECSへアクセスする必要がないため、デフォルトで作成されているIAMロールecsTaskExecutionRoleと同じ信頼関係を設定しています。必要な方は適宜信頼関係を結んでください。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "Statement1", "Effect": "Allow", "Principal": { "Service": "ecs-tasks.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
また、IAMロールに付与するポリシーは以下の5つを付与しました。
- CloudWatchFullAccess
- CloudWatchLogsFullAccess
- AmazonECS_FullAccess
- AmazonSSMReadOnlyAccess
ポリシーもecsTaskExecutionRoleと同じポリシーを与えています。お使いの環境に合わせて設定してください。
2. Workload Identity PoolとProviderの作成
Workload Identity Poolとproviderの管理に権限が必要となります。プロジェクトまたはユーザーに対してIAMロールを付与してください。
- PoolとProviderを表示する: IAM Workload Identityプール閲覧者
- Poolとプロバイダを表示、作成、更新、削除する: IAM Workload Identityプール管理者 引用:必要なロール
Poolの作成
Google Cloudコンソールで、Workload Identity プールページに移動しPoolを作成します。
[メニュー] → [IAMと管理] → [Workload Identity連携] → [プールを作成]
今回は検証としてBigQueryへのアクセスを行うため、bq-poolと名付けます。
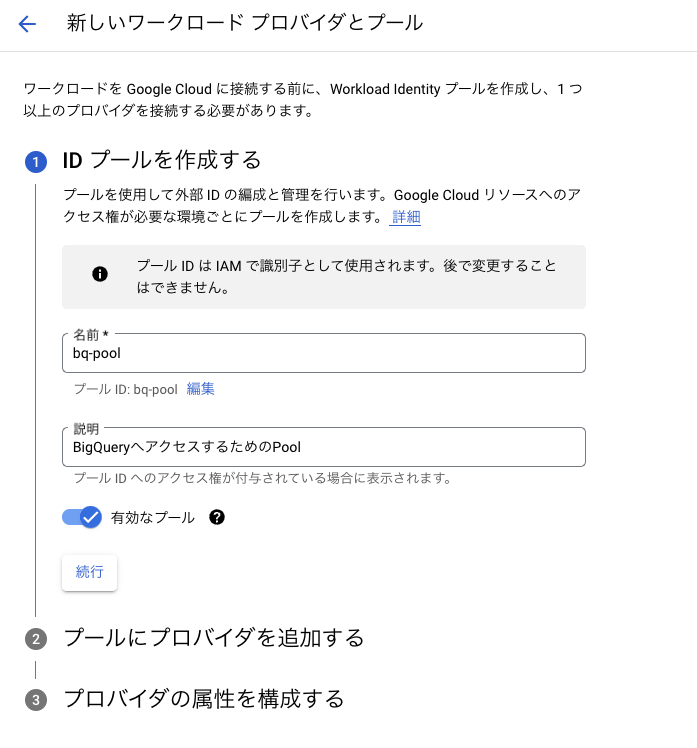
Providerの作成
「続行」を押し、bq-poolにプロバイダーを追加します。
それぞれの項目の設定を行います。
- プロバイダの選択: AWS
- プロバイダの詳細: aws-provider (お好きなように命名してください)
- AWSアカウントID: ご自身が利用されているAWSアカウントID
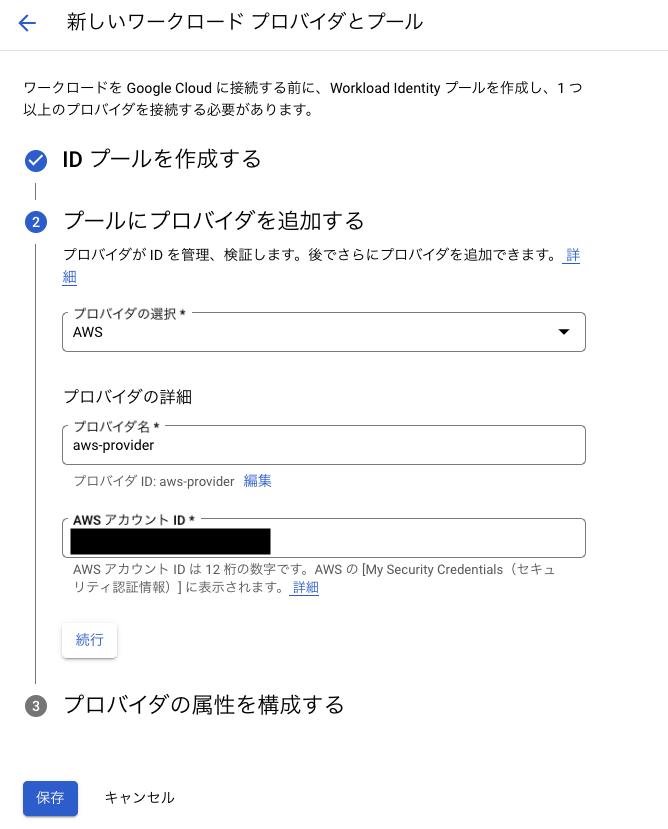
上記3つの項目を入力し、「続行」をクリックすると次は属性のマッピングの設定になります。
Workload Identity連携では、アクセストークンを発行してもらいサービスアカウントとしてリソースの操作を認可してもらいます。そのため、認証情報を外部IDにマッピングする属性マッピングを定義することで認可されたことの証明に利用します。
属性のマッピングでは、デフォルトで既に大まかに分けて2種類の属性が設定されていると思います。
| 属性 | ユースケース |
|---|---|
| google.subject | 必須の設定。一意のユーザーにアクセス権を付与したい |
| attribute.XXX | 特定の属性を持つ全てのIDにアクセス権を付与したい |
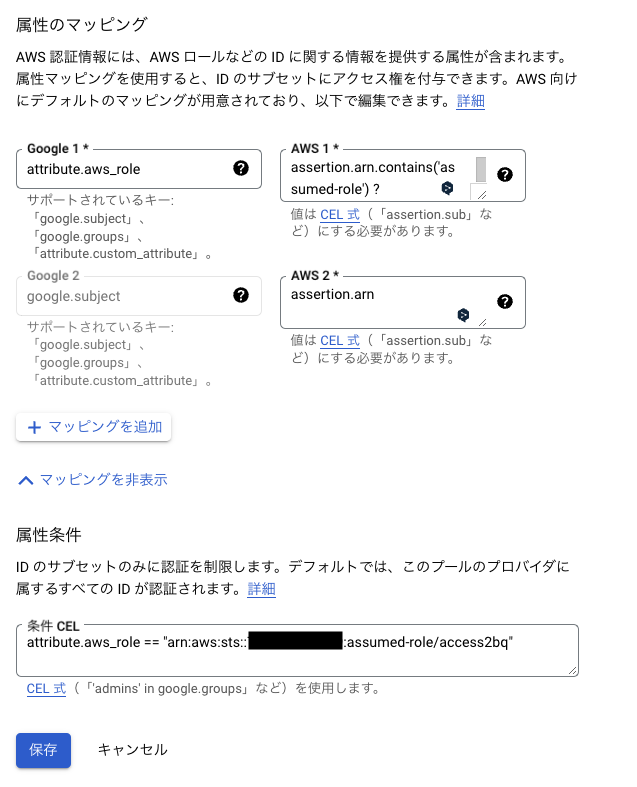
外部IDプロバイダから発行された認証情報には、1つ以上の属性が含まれます。Workload Identity連携では、これらの属性をアサーション属性とし、assertion.XXXで参照できます。
アサーション属性では、さまざまなフィールドがありますが、今回利用するassertion.arnはAWS ARNが含まれます。
google.subject=assertion.arn
attribute.aws_role=assertion.arn.contains('assumed-role') ? assertion.arn.extract('{account_arn}assumed-role/') + 'assumed-role/' + assertion.arn.extract('assumed-role/{role_name}/') : assertion.arn
そこで、上記のようなマッピングにより、AWS側が提示するクレデンシャル情報に含まれるarnをどのような形でattribute.aws_roleまたはgoogle.subjectに格納するのかを示しています。
この設定により、Workload Identity側でIAMロールレベルで借用権限を制限できます。
「保存」をクリックし、PoolとProviderの作成は完了となります。

3. Workload Identityとサービスアカウントの連携
次に、先ほど作成したbq-poolとサービスアカウントと信頼関係を結びます。
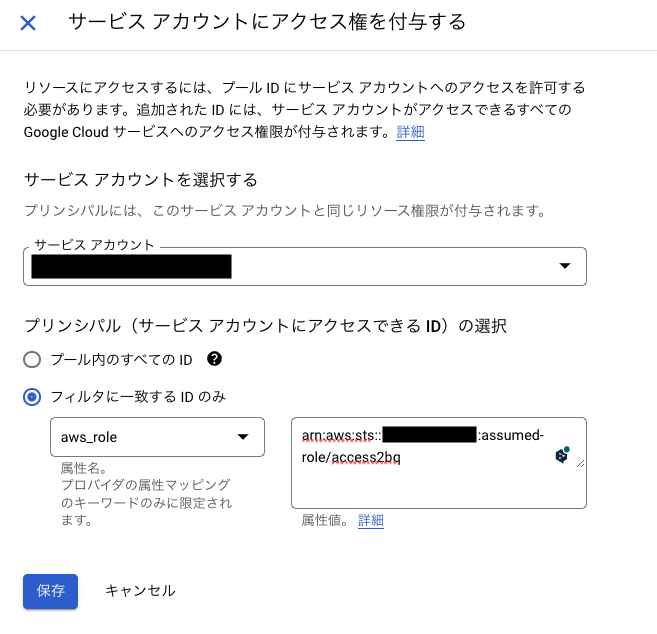
コンソール画面からbq-poolを選択し、プールの詳細へ移動し、「アクセスを許可」からサービスアカウントにアクセス件を付与するための画面が出てきます。
「サービスアカウントを選択する」で利用したいサービスアカウントを選択し、「保存」することでPoolとサービスアカウントで信頼関係を結ぶことができました。
Poolからアクセスを許可したサービスアカウントにはGCPのリソースを操作する権限をあらかじめ与えておいてください。今回は検証としてBigQueryへのアクセスのため、BigQuery実行するための権限を与えています。

4. 認証構成ファイルの取得
Poolからサービスアカウントへアクセス許可の設定を行なった際に構成ファイルがダウンロードできます。作成したaws-providerを指定してダウンロードします。
このjsonファイルがこれまで使用していたサービスアカウントキーのクレデンシャルファイルの代わりになります。
ファイルの中身は機密情報が含まれていないため、サービスアカウントキーよりも管理を厳密にする必要がありません。(念の為サービスアカウント名だけ隠しております)
{ "type": "external_account", "audience": "//iam.googleapis.com/projects/123456789012/locations/global/workloadIdentityPools/bq-pool/providers/aws-provider", "subject_token_type": "urn:ietf:params:aws:token-type:aws4_request", "service_account_impersonation_url": "https://iamcredentials.googleapis.com/v1/projects/-/serviceAccounts/XXXXXXX@XXXXXX.iam.gserviceaccount.com:generateAccessToken", "token_url": "https://sts.googleapis.com/v1/token", "credential_source": { "environment_id": "aws1", "region_url": "http://169.254.169.254/latest/meta-data/placement/availability-zone", "url": "http://169.254.169.254/latest/meta-data/iam/security-credentials", "regional_cred_verification_url": "https://sts.{region}.amazonaws.com?Action=GetCallerIdentity&Version=2011-06-15" } }
5. 認証構成ファイルを利用してECSでアプリケーションを実行
実際に認証構成ファイルを用いてECSからGCPのBigQueryへアクセスしSQLを叩いてみます。
今まではサービスアカウントキーを環境変数GOOGLE_APPLICATION_CREDENTIALSにファイルパスを指定していました。このファイルパスの向き先を認証構成ファイルへ向くようにします。
EC2のインスタンスでは、環境変数に認証構成ファイルパスをセットするだけで認証が通りますが、ECSではこのままではアクセスできません。なぜなら、EC2インスタンスとECSタスクロールでクレデンシャルを取得するためのメタデータURLが異なるからです。
- EC2インスタンス:
http://169.254.169.254/latest/meta-data/iam/security-credentials - ECSタスクロール:
http://169.254.170.2$AWS_CONTAINER_CREDENTIALS_RELATIVE_URI
そのため、ECSタスクロールのクレデンシャルを取得して環境変数にセットする必要があります。下記のようにあらかじめリクエストを送りクレデンシャルを入手後、環境変数にセットします。
import os import requests from google.cloud import bigquery # 認証構成ファイルのパスを環境変数に入れる。ソースコードの外から入れても良い os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '<認証構成ファイルパス>' url_path = os.environ.get('AWS_CONTAINER_CREDENTIALS_RELATIVE_URI') url = urljoin('http://169.254.170.2', url_path) res = requests.get(url, timeout=3).json() os.environ['AWS_ACCESS_KEY_ID'] = res['AccessKeyId'] os.environ['AWS_SECRET_ACCESS_KEY'] = res['SecretAccessKey'] os.environ['AWS_SESSION_TOKEN'] = res['Token']
では、実際に簡単なSQLを叩くアプリケーションを実装し、ECSで実行しました。 今回はFargateで実行するため、実行結果をCloudWatchなどに吐き出すようにすることでBigQueryのテーブル内のデータが表示されていることが確認できると思います。
import os import requests from google.cloud import bigquery from urllib.parse import urljoin # 認証構成ファイルのパスを環境変数に入れる。ソースコードの外から入れても良い os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '<認証構成ファイルパス>' # ECSタスクロールのクレデンシャルを環境変数に入れている url_path = os.environ.get('AWS_CONTAINER_CREDENTIALS_RELATIVE_URI') url = urljoin('http://169.254.170.2', url_path) res = requests.get(url, timeout=3).json() os.environ['AWS_ACCESS_KEY_ID'] = res['AccessKeyId'] os.environ['AWS_SECRET_ACCESS_KEY'] = res['SecretAccessKey'] os.environ['AWS_SESSION_TOKEN'] = res['Token'] # Cloud Identity連携が設定されているプロジェクトIDを指定する project_id = '<プロジェクト名>' bqclient = bigquery.Client(project=project_id) dryrun = False sql = """ SELECT * FROM `<DATASET>.<TABLE>` LIMIT 10 """ job_config = bigquery.QueryJobConfig(dry_run=dryrun) query_job = bqclient.query(sql, job_config) assert query_job.errors is None, f'errors: {query_job.errors}' # debug print(f"Bytes processed: {query_job.total_bytes_processed} B") # 先頭5行分のみ出力 df = query_job.result().to_dataframe() print(df.head())
応用編: Workload Identity連携におけるアクセス制限について
Workload Identityではアクセス制限の設定が可能となります。AWSだとIAMロールレベルでの指定が可能だったり、CI/CDからのアクセスではリポジトリレベルでの制限を課すことができます。制限をかける手法は以下の2つです。
- 属性マッピングと条件
- サービスアカウントの紐付け時の条件
方法1: 属性マッピングと条件
属性マッピングと条件はProviderの作成時または作成後にProviderの編集にて設定することができます。属性マッピングでattribute.aws_roleにAWSから提示されるクレデンシャル情報のarnをマッピングした形式でセットしています。そのため、属性条件にどのIAMロールからのアクセスを許可するのかを属性条件に明記します。
デフォルトの属性マッピングの設定なら、下記のように属性条件の条件CELに記述します。
attribute.aws_role == "arn:aws:sts::{AWS_ACCOUNT_ID}:assumed-role/{IAM_ROLE}"
方法2: サービスアカウントの紐付け時の条件
他の方法としてサービスアカウントとPoolの信頼関係を結ぶ際に同様に条件の設定が可能となります。コンソール画面からWorkload Identity Pool一覧から、Poolを選択し、「アクセス許可」をクリック。プリンシパルの選択で、「フィルターに一致するIDのみ」を選び、下記の値をセットします。
- 属性名:
aws_role - 属性値:
arn:aws:sts::{AWS_ACCOUNT_ID}:assumed-role/{IAM_ROLE}
検証: 別のIAMロール(タスクロール)を設定してアクセスしてみる
タスクロールの指定を始めに作成したaccess2bqというIAMロールのみ認証が通るように設定しました。そこで、ECSタスク定義において、タスクロール・タスク実行ロールをデフォルトで用意されているecsTaskExecutionroleに置き換えて先ほどのアプリケーションを実行をしてみます。

すると、以下のようなエラーが発生し認証エラーによってアプリケーションがこけたことがわかると思います。
google.auth.exceptions.OauthError: ('Error code unauthorized_client: The given credential is rejected by the attribute condition.', '
{
"error": "unauthorized_client",
"error_description": "The given credential is rejected by the attribute condition."
}
')
検証からシステムの導入へ
今回の検証を経て、私たちが運用しているシステムへWorkload Identityを導入していきました。まだ全てのシステムに適用できているわけではありませんが、実際にWorkload Identityを導入して稼働しているシステムがいくつかあります。サービスアカウントキーの利用をシステムから切り離しつつ、セキュリティ向上にも繋がっていると実感できています。
今後の展開としましてはECSだけではなくCI/CDといったワークフロー、そして他のAWSサービス(EC2やLambdaなど)にも取り入れていきたいと考えています。
まとめ
さて、今回はWorkload Identity連携を利用してECSからサービスアカウントキーを使うことなくGCPサービスへアクセスする方法について紹介させていただきました。
業務でWorkload Identity連携の導入のきっかけは、学生時代に「OAuth徹底入門 セキュアな認可システムを適用するための原則と実践 」 を読んだことがきっかけでした。書籍では認証・認可の話がメインですがその中で「クレデンシャルで認証してAPIやリソースへアクセスするのは危ないのでアクセストークンが存在。どのリソースをどこまで権限与えるのかの役割をアクセストークンが果たしている」という内容がすごく印象的でした。
そこから、アプリケーションの認証周りやセキュリティについて少しずつ興味を持ち、私たちが運用しているシステムの課題に率先してWorkload Identityを導入する機会を得られました。
私にとっては新しい試みでとても大変でしたが、システムが改善されていく様や検証によって得た学びをチームに共有して新たな選択肢の一つとして採用されたことは新卒エンジニアとしてとても嬉しい限りでした。
読んでいただいた方に少しでも手助けになれば幸いです。