こんにちは、広告事業本部でクライアントの受発注システムを担当しているリードアプリケーションエンジニアの花田です。
前回の「[ちりつもは正義!3プロダクトのAWS環境を見直すことで、年間数百万円のコスト削減]」の記事で、ジョブインスタンスを別のAWSサービスに置き換えると明言していたので置き換えてきました。
- はじめに
- SQSのお供はどっち? Lambda vs Fargate
- 1. Railsの修正
- 2. SQSの追加
- 3. Lambdaの追加
- 4. SQS + Lambdaのエラー通知をより堅牢に
- 5. リトライ方法
- コストをどのぐらい削減できそうなの?
- 結局コスパ悪いのでは?
- 最後に
はじめに
現在ジョブはEC2インスタンス上でRails + Sidekiq + Redisの構成で運用しています。
EC2は1台だけで稼働しており、そのインスタンスはリザーブドインスタンスとして購入済みのためコストは比較的安価です。
コストが安価な状況で5つあるジョブすべてを移行し、エンジニアの工数を一定程度かけるのはコストパフォーマンス的に見てあまり効率的ではないのでは?と思ったりもします。
しかし新たな価値を見出すため、今回はジョブインスタンスを別のAWSサービスに移行する方法を紹介します。
SQSのお供はどっち? Lambda vs Fargate
これまでメッセージキューイングにはRedisを利用していましたがAWSの別のサービスに移行することになったため、今回はSQSを採用することにしました。
SQSを採用するにあたり、どのAWSサービスと組み合わせるのが最適かを判断するためLambdaとFargateの比較をしました。
| 項目 | Lambda + SQS | Fargate + SQS |
|---|---|---|
| 仕組み | - SQSでジョブをキューイングしLambda関数が処理 | - SQSでジョブをキューイングしFargateタスクとして実行 |
| メリット | - サーバーレス - 従量課金 - 高速スケーリング - 高可用性 |
- サーバーレス - より大きなコンテナイメージの利用可 - lambdaより長時間実行可 - 高可用性 - 高スケーラブル |
| デメリット | - 最大15分の実行時間制限がある - コールドスタートで実行時間が遅くなることがある - 複雑な処理に不向き |
- 設定が複雑でコード管理量も増える - Lambdaより高コストの可能性あり - スケールはLambdaより遅い |
| 用途 | - 短時間の処理に適しており即時性が求められる小規模なタスクやイベント駆動型の処理に最適 - 高いスケーラビリティで多数のリクエストを効率的に処理できる |
- 長時間の処理や複雑な処理に適しており時間制限なく実行可能 - 複雑な処理やバッチ処理など多段階やリソース集約型のタスクに向いている - 高いスケーラビリティを持ちつつコンテナ化されたアプリケーションを動かすため柔軟な環境構築が可能 |
Lambdaは最大実行時間が15分と短いため処理が重いものには適していません。
一方、Fargateは時間制限がなく細かな設定もできるため複雑なジョブ処理には向いていますが、その分料金も高くなります。
私たちが管理しているサービスは処理が単純で実行時間も短いため、コストや運用の観点からLambdaを採用することに決めました。
1. Railsの修正
RailsでSQSを設定できるGemをインストールしよう
Active JobとAWS SQSを連携させるため、以下のGemをGemfileに記載してインストールします。
gem 'aws-sdk-rails'
SQSを設定してみよう
RailsでSQSを利用できるように設定する場合、config/application.rbに次のように記述します。
config.active_job.queue_adapter = :amazon_sqs config.active_job.queue_name_prefix = Rails.env
これによりキューの名前に環境(developmentやproductionなど)のプレフィックスが自動的に付加されます。
ジョブをエンキューするためのクラスを作成してみよう
app/jobs/update_test_job.rbに次のようなジョブクラスを作成します。
# frozen_string_literal: true class UpdateTestJob < ApplicationJob queue_as :update_test def perform; end end
このときqueue_name_prefixを設定しているため、ジョブを呼び出すときは環境名(例:developmentやproduction)とジョブ名が組み合わさったキュー名になります。
具体的には env_ジョブ名 の形式でキューにエンキューされるため、環境ごとに異なるキューに振り分けられ管理しやすくなります。
ジョブとSQSの紐づけ設定を行おう
config/aws_sqs_active_job.ymlに環境ごとのSQSキューのURLを定義します。
queues: development_update_test: 'https://sqs.ap-northeast-1.amazonaws.com/12345678/development_update_test' staging_update_test: 'https://sqs.ap-northeast-1.amazonaws.com/12345678/staging_update_test' production_update_test: 'https://sqs.ap-northeast-1.amazonaws.com/12345678/production_update_test'
この設定によりRailsの環境に応じて適切なSQSのURLが呼び出されるようになります。
2. SQSの追加
SQSを作成してみよう
SQSはジョブ単位で作成し1つのジョブに対して、通常のキューとデッドレターキュー(DLQ)) の2つ作成します。
- 通常のキュー:正常に処理されるメッセージ用
- デッドレターキュー(DLQ):エラーが発生したメッセージが確実に記録されるキュー
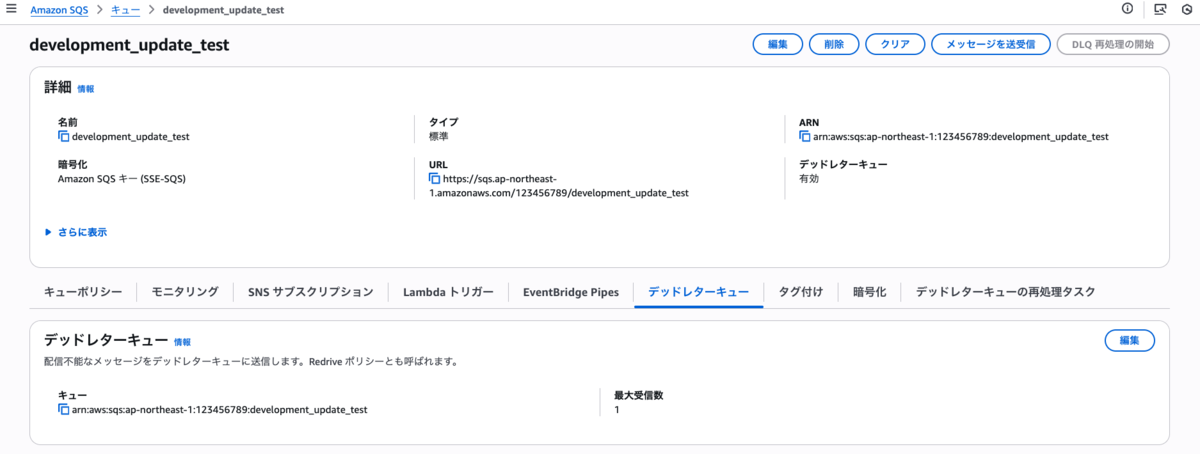
通常キューにデッドレターキューを紐づけており、「可視性タイムアウト」は3分に設定しています。
可視性タイムアウトとは、SQSキューにメッセージを受信(ReceiveMessage)したときに、そのメッセージを 見えなくする時間 の設定です。
具体的にはメッセージを受信した後、一定時間はLambdaから見えなくなります。
これにより同じメッセージを複数のLambdaが同時に処理しないように制御できます。
またデッドレターキューの最大受信数を 1 にしています。
こうすることでLambdaでエラーが発生した場合、すぐにデッドレターキューにキューがたまります。
補足 : なぜ可視性タイムアウトを3分に設定?
「AWS公式 Lambda で使用するキューの設定」によると、Lambdaのタイムアウト時間の少なくとも6倍を可視性タイムアウトに設定することが推奨されています。
関数がレコードの各バッチを処理する時間を確保するには、ソースキューの可視性タイムアウトを、関数の設定タイムアウトの少なくとも 6 倍に設定します。追加の時間は、関数が前のバッチの処理中にスロットリングされた場合に、Lambda が再試行することを可能にします。
例:
Lambdaのタイムアウトを30秒に設定する場合、
SQSの可視性タイムアウトを 6倍の3分(180秒) に設定します。
これによりLambdaが処理中にスロットリングされた場合でも再試行やデッドレターキューに確実にメッセージが記録されるようになります。
3. Lambdaの追加
Lambdaにコードを書こう
例として外部サービスへ情報を更新し、その結果をSlackに通知する処理を作成します。
export const handler = async (event) => { try { // ここに外部サービスへデータを更新する処理を記載 // 例:API呼び出しやデータベース更新など // ・ // ・ // ・ // 正常終了を返す return { statusCode: 200, body: JSON.stringify('record updated successfully.') }; } catch (error) { // エラー発生時にSlackにエラー通知を送る await slackWebClient.sendError(event, error); // Lambdaに処理失敗を通知し、エラーをスロー throw error; } }
外部サービスへのデータ更新でエラーが発生した場合にSlack通知するようにしています。
Lambdaの設定を変更してみよう
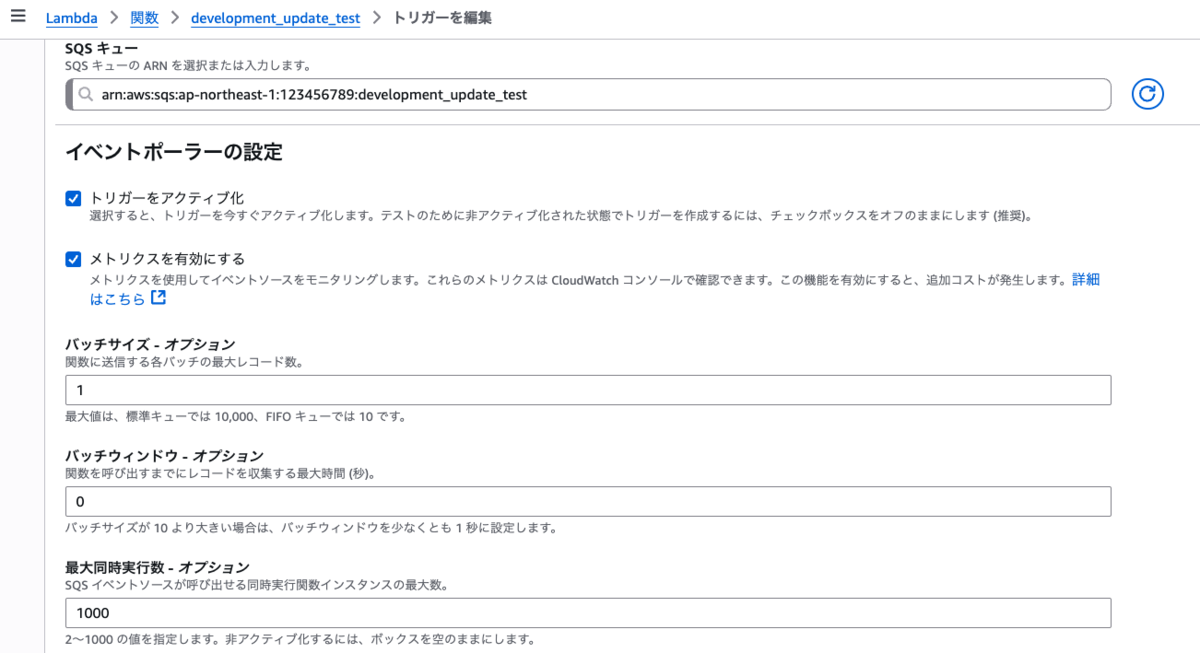
バッチサイズの数値を 1 に設定しています。
バッチサイズを1に設定すると、Lambdaは1回の呼び出しでSQSキューから1つのメッセージだけを処理します。
バッチサイズが2以上だった場合Lambdaは1回の呼び出しに複数のキューを取得されるため、Lambda側で複数対応する処理にしておかないと意図しない動作やエラーになる可能性があるので注意が必要です。
補足 : SQS + Lambdaの「非同期呼び出し」は関係ない!
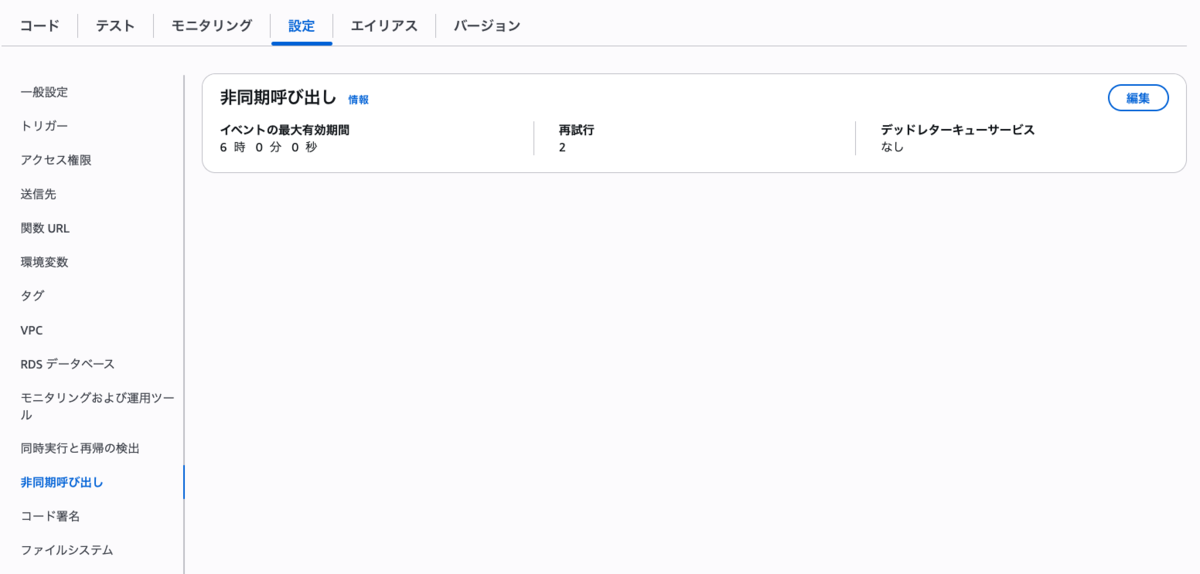
Lambdaにも 再試行 回数が設定できますが、SQSと組み合わせた際は呼び出し方が違うため反映されません。
「Lambda での再試行動作について」に記載されている通り、SQS + Lambdaの場合は イベントソースマッピング のシナリオとなるため非同期呼び出しの設定には対応していません。
4. SQS + Lambdaのエラー通知をより堅牢に
Lambda自体のエラーはどうする?
Lambdaコード上にSlack通知処理を記載しましたが、もしもLambdaと通信できないなどLambda自体がエラーになる場合はエラー通知が届きません。
そこでLambda自体のエラーを検知し、Slack通知を自動で行うために、Amazon Q Developer(旧:AWS Chatbot) を設定しています。
これによりLambdaのエラーが発生した際にChatbot経由でSlackに通知されます。
SQSデッドレターキューのメトリクスに対してCloudWatch Alarmを作成してみよう
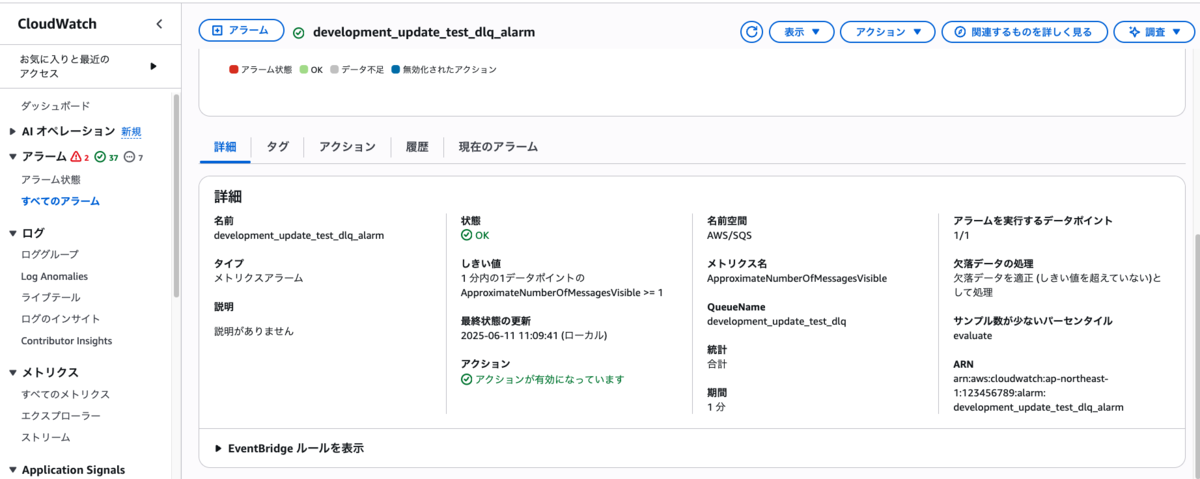
CloudWatch アラーム設定内容
| 項目 | 内容 |
|---|---|
| メトリクス名 | ApproximateNumberOfMessagesVisible |
| 統計 | 合計 |
| 期間 | 1分(60秒) |
| しきい値の種類 | 静的 |
| アラーム条件 | 以上 |
| しきい値の定義 | 1 |
| 欠落データの処理 | 欠損データの適正(しきい値を超えていない)として処理 |
CloudWatchメトリクスの「ApproximateNumberOfMessagesVisible」を利用するとデッドレターキューに入っているメッセージの数を確認できます。
デッドレターキューにキューが入る=エラーが発生した とみなされるのでCloudWatch Alarmが検知し通知をトリガーします。
CloudWatch AlarmはSNSを通してAmazon Q Developer(旧:AWS Chatbot)と連携しているため、Slackに通知される仕組みになっています。
また 欠損データの適正(しきい値を超えていない)として処理 として設定しているため、デッドレターキューにキューがなくなった場合は正常状態と判断され、成功通知がSlackに送信されます。
5. リトライ方法
SQSのデッドレターキューでリトライしてみよう
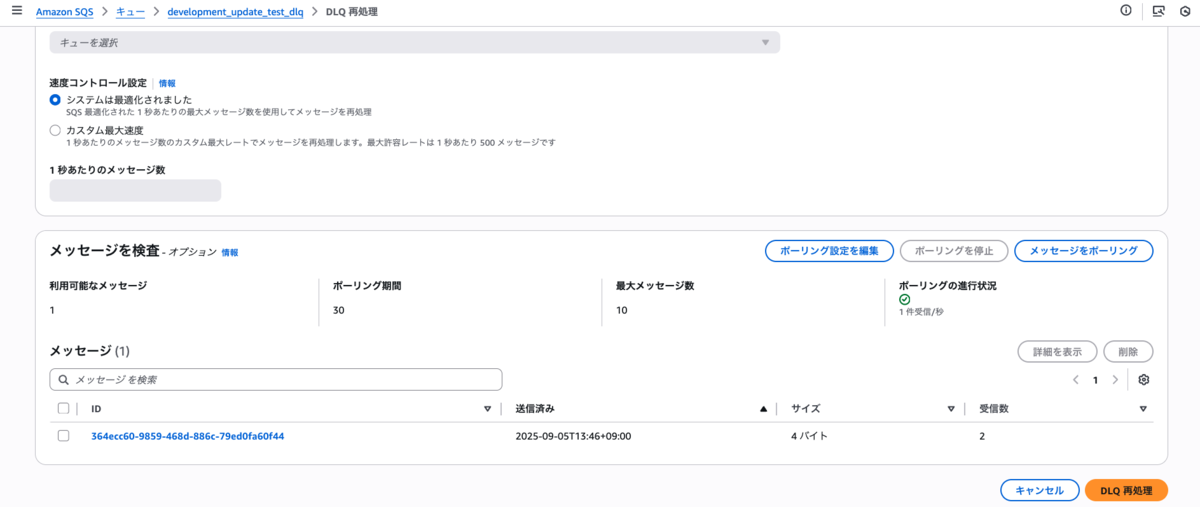
Lambdaで処理中にエラーが発生すると、そのメッセージはSQSのデッドレターキューに格納されます。
このデッドレターキューから DLQ再処理 を行うことができます。
具体的にはDLQ再処理画面にアクセスしてDLQ再処理ボタンを押すとデッドレターキューにあるキューが再実行されます。
またリトライする際に該当メッセージを選択するとリクエストした内容が詳細に表示されるため、何をリトライするかが一目でわかりやすく確認できる仕組みになっています。
コストをどのぐらい削減できそうなの?
stagingとproductionのジョブをLambdaに移行することで月に約$26削減できる見込みです。
んー、なんとも微妙な金額ですね。
結局コスパ悪いのでは?
ジョブの移行には影響範囲の調査や開発やテストなど一定程度の工数をかけましたが、その結果月に約26ドルのコスト削減が実現しました。
この金額だけを見ると、あまり大きな成果とは言えないかもしれません。
しかし金額面だけでなく個人的には サーバーレス化による新たな価値 も大きいと感じています。
例えば、OSをAmazon Linux 2からAmazon Linux 2023に移行する場合、Webサーバーだけでなくジョブに影響が出るかどうかの調査が必要で範囲も広くて大変でした。
しかし今後OSを変更する場合はウェブインスタンスとバッチインスタンスだけを考えれば良くなるため、調査や修正の工数が格段に少なくて済むようになります。
この考え方はOSだけでなくRailsのアップグレードなどでも同じで、エンジニアの運用負荷を軽減できるメリットがあります。
最後に
今回はジョブインスタンスをLambdaに移行することでコスト削減を実現しました。
またサーバーレス化によって新たな価値や運用の効率化も見出せたと感じています。
次のステップとしてバッチ処理用のインスタンスも別のAWSサービスに移行し、さらなるコスト削減や運用の効率化を目指したいと考えています。