こんにちは、インフラの天津です。今日は 複数アカウントの AWS Security Hub 検出結果の可視化についてお話したいと思います。
- 前提
- モチベーション
- AWS Security Hub とは
- 構想
- ツール・サービスの選定
- 構築
- 導入後について
- 余談
- 終わりに
前提
今回の記事は東京リージョン(ap-northeast-1)のみを対象としています。
モチベーション
私は現在、部署やチームの 目標 OKR にも掲げている AWS のセキュリティ関連の取り組みを実施しています。
セキュリティ関連の取り組みを始めた当初、まず現状把握する必要がありました。 チェックツールとして AWS では AWS Security Hub を使用したセキュリティチェックが一般的です。 それを使用して Organizations 配下の複数の AWS アカウントでセキュリティチェックを実施することを考えましたが、結果表示にいくつか問題がありました。
- 時系列推移が表示されない
- 検出結果に対してアカウント ID は表示されるが、アカウント名が表示されない
- AWS 利用者は複数の AWS アカウントに属しているが、各 AWS アカウントでは複数の AWS アカウントを横断的に表示できない
- 表示するためには Security Hub のマスターアカウントへの権限付与が必要になるが、管理上避けたいと考えた
これらを解決するために検出結果データのエクスポートと可視化を別途考える必要がありました。
AWS Security Hub とは
そもそも AWS Security Hub とは何か?ですが、AWS が提供するセキュリティチェックサービスです。 AWS Config とともに使用し、セキュリティチェック、アラートの集約、自動修復などが実行できる大変便利なサービスです。 複数の AWS アカウントに対して管理アカウントで統合して管理することも可能です。
AWS Security Hub(統合されたセキュリティ & コンプライアンスセンター)| AWS
構想
当初の構想ですが、下記の通り粗く考えていました。
- 検出結果データのエクスポート
- エクスポートしたデータを何らかのデータベース(または相当のもの)に格納
- データベースに格納したものを何らかのツールで可視化
図にしてみると下記のような感じです。

これらをどのように設計・構築していったかを書いていきます。
ツール・サービスの選定
検出結果データのエクスポートについて
検出結果データをエクスポートする方法について調べたところ、下記のサンプルがサクッと見つかったので使用することにしました。
GitHub - aws-samples/aws-security-hub-findings-export
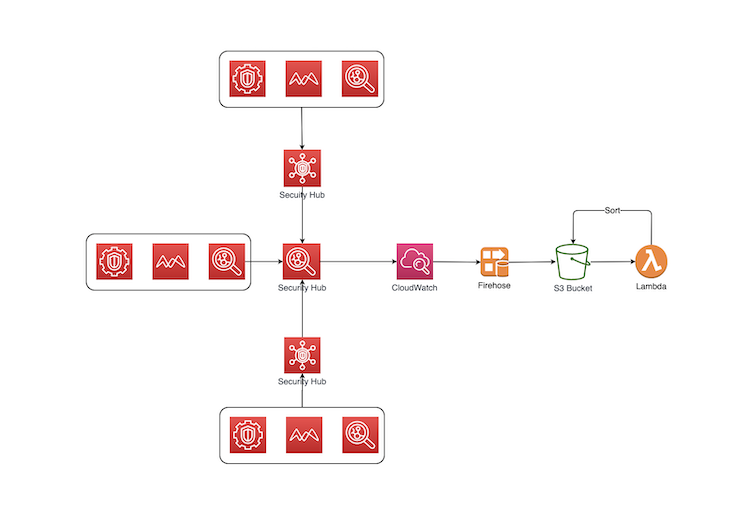
この CloudFormation は Amazon EventBridge、Amazon Kinesis Data Firehose、Amazon S3、AWS Lambda のリソースを作成します。
作成されたリソースは下記のように動作します。
- Amazon EventBridge で AWS Security Hub の検出結果データを取得し Amazon Kinesis Data Firehose に送信
- Amazon Kinesis Data Firehose が Amazon S3 に格納
- Amazon S3 への格納をトリガーに Lambda 起動
- AWS Lambda が格納データをアカウント、リージョン、発生日付で整理し Amazon S3 に最終的に格納
README から引用した構成図は下記のとおりです。
可視化用データベース(またはクエリサービス)と可視化ツールについて
次に考えるのは可視化用データベース(またはクエリサービス)です。選択肢としては下記がありました。
- Athena
- BigQuery
- その他 DB
今回はこの中で BigQuery を選択しています。というのも、弊社では Gsuite を導入済みで、Google DataPortal(DataStudio) が使用可能であること、BigQuery との組み合わせの知見があることが主な理由です。
S3 にデータを格納しているため Athena を使用するのが一般的ではあると思いますが、選定しなかった理由は、Google DataPortal(DataStudio) で Athena 用のコネクタが提供されていなかったのが理由です。(コミュニティで開発された Athena 用コネクタは存在しますが、知見がなかったこともあり使用していません。)
また、Athena を 使用する場合は QuickSight の使用が考えられますが、こちらは知見がなく採用していません。
構築
全体像
選定したツール群での構成は下記になります。変換スクリプトはこれまでの説明に出てきませんが必要になりました。(必要になった理由は後述します)

検出結果データエクスポート
前述した通り、AWS 提供の CloudFormation を使用しエクスポートしました
検出結果データの S3 -> GCS への転送と BigQuery へのインポート
BigQuery へのインポートは GCS から行います。テーブルはデータの再取り込みがやりやすいよう日付分割でのテーブル作成としました。
最終的には下記の bash スクリプトにて取り込みを実施しました。 実行に必要な権限は下記の通り設定しています。
- AWS
AmazonS3ReadOnlyAccessポリシー
- GCP
resourcemanager.projects.getbigquery.datasets.getbigquery.jobs.createbigquery.tables.createbigquery.tables.updatebigquery.tables.updateDatastorage.buckets.getstorage.objects.createstorage.objects.deletestorage.objects.get
#!/usr/bin/env bash set -eu YEAR=${1:0:4} MONTH=${1:4:2} DAY=${1:6:2} BUCKET_NAME="securityhub-findings-export-securityhublogbucket-xxxxxx" AWS_PROFILE_NAME="xxxx" # S3から取得 export AWS_PROFILE=${AWS_PROFILE_NAME} export AWS_DEFAULT_PROFILE=${AWS_PROFILE_NAME} aws s3 cp --no-progress --recursive s3://${BUCKET_NAME}/ ./data/ --exclude "*" --include "AWSLogs/*/*/*/${YEAR}/${MONTH}/${DAY}/*.json" # BigQuery への Load のため、 JSON のキーに含まれる英数字以外の文字をアンダースコアに変換 # 変換後に BigQuery への Load に必要なブロックのみ取り出し1ファイルに出力 cat data/AWSLogs/*/*/*/"${YEAR}/${MONTH}/${DAY}/"*.json | ./conv.py | \ jq -rc '.detail.findings[]' > "./data/bq_data_${YEAR}${MONTH}${DAY}.json" # GCPセットアップ GCP_KEY_FILE=./auth.json GCP_SVC_ACCOUNT=$(cat ${GCP_KEY_FILE} | jq -r '.client_email') GCP_PROJECT_ID=$(cat ${GCP_KEY_FILE} | jq -r '.project_id') gcloud auth activate-service-account "${GCP_SVC_ACCOUNT}" --key-file "${GCP_KEY_FILE}" --project "${GCP_PROJECT_ID}" # GCSに転送 gsutil -q -m -o "GSUtil:parallel_process_count=1" cp -r "./data/bq_data_${YEAR}${MONTH}${DAY}.json" "gs://securityhub-export-data/${YEAR}/${MONTH}/${DAY}/" # bq コマンドの初回メッセージを出力済みにしておく bq ls > /dev/null 2>&1 # BQ取り込み bq load --replace -q --ignore_unknown_values --noautodetect --source_format=NEWLINE_DELIMITED_JSON \ "Project.Dataset.all_data_${YEAR}${MONTH}${DAY}" \ "gs://securityhub-export-data/${YEAR}/${MONTH}/${DAY}/bq_data_${YEAR}${MONTH}${DAY}.json"\ ./schema.json
Security Hub の検出結果データは下記のような JSON データです。必要なのは detail.findings[] の中身です。jq コマンドでその部分だけを取得してインポートすることにしましたが、2点ほど苦労した点があるので紹介しておきます。
- Security Hub からエクスポートしたデータには BigQuery のカラム名に使用できない文字(以下禁則文字)が使用されている
- 自動判別でインポートした際に INTEGER 型のカラムに STRING 型のデータが入ってくることがありインポートエラーが発生する
{ "version": "0", "id": "xxxx-xxxx-xxxx-xxxx-xxxx", "detail-type": "Security Hub Findings - Imported", "source": "aws.securityhub", "account": "xxxx", "time": "yyyy-mm-dd:hh:mm", "region": "xx-xxxx-1", "resources": [ "arn:aws:securityhub:xx-xx-1::product/aws/securityhub/arn:aws:securityhub:xx-xx-1:xxxx:subscription/aws-foundational-security-best-practices/v/1.0.0/xxx/finding/xxxx-xxxx-xxxx-xxxx-xxxx" ], "detail": { "findings": [ <中略> ] } }
Security Hub からエクスポートしたデータには BigQuery のカラム名に使用できない文字(以下禁則文字)が使用されている件
BigQuery のカラム名には、英数字とアンダースコア以外(ハイフンやスラッシュ、シャープなど)が使用できませんが、 Security Hub の検出結果データの Key には禁則文字が含まれています。
例えば下記のような key が存在しエラーとなっていました。
- detail.findings.ProductFields.RelatedAWSResources:0/name
- detail.findings.Resources.Awslogs-stream-prefix
そのため、下記 Python スクリプトを作成し、禁則文字を全てアンダースコアに変換したのちに BigQuery に取り込むこととしました。 不可逆な変換にはなりますが、今回の目的には影響しないためこのようにしています。
#!/usr/bin/env python3 """ AWS SecurityHub の Findings データを BigQuery が取り込める状態のデータに変換するツール """ import json import sys import argparse import re import ndjson def convert(data, func=lambda x: x): """ AWS SecurityHub の Findings データを BigQuery が Load できる内容に変換する。 変換処理は引数に与えられる関数に委譲する 本関数では data を再帰でたどり dict のキー値に対して変換関数を適用する。 """ if isinstance(data, dict): obj = {} for key, value in data.items(): obj[func(key)] = convert(value, func) return obj if isinstance(data, list): obj = [] for item in data: obj.append(convert(item, func)) return obj return data def to_snakecase(key_str: str): """ 英数字以外をアンダースコアに変換する AWS SecurityHub の検知データの JSON キーにはBigQueryの列名として使用できない記号が含まれているため変換が必要 AWS SecurityHub の検知データの仕様とサンプルは下記を参照 - https://docs.aws.amazon.com/securityhub/latest/userguide/securityhub-findings-format.html # noqa: E501 """ # 事前コンパイルで速度向上がなかったためそのまま記載 return re.sub('[\W]', '_', key_str) # noqa: W605 def main(): """ main """ # 引数処理 parser = argparse.ArgumentParser(description='Parse command line options.') parser.add_argument( '-i', '--input-file', type=argparse.FileType('r'), default=sys.stdin, help='file path to convert. file format must be ndjson', ) parser.add_argument( '-o', '--output-file', type=argparse.FileType('w'), default=sys.stdout, help='file path to output. format of the output file is ndjson', ) args = parser.parse_args() # ファイル内容または標準入力から AWS SecurityHub Findings データ(ndjson)を読み出し、 # BigQuery が Load 可能なデータに変換し出力する(フォーマットはndjson) file_data = args.input_file.readlines() for line in file_data: json_obj = json.loads(line) converted = convert(json_obj, to_snakecase) writer = ndjson.writer(args.output_file) writer.writerow(converted) if __name__ == "__main__": main()
自動判別で生成されたスキーマでインポートした際に INTEGER 型のカラムに STRING 型のデータが入ってくることがありインポートエラーが発生する件
次に苦労したのは自動判別で生成したスキーマとインポートするデータ型の一部不一致でした。 具体的には検出結果データ内の Security Group リソース詳細データの protocol が該当します。
Security Group の protocol は -1(Any を示す) または "tcp", "udp", "icmp"が入ってくる可能性があります。 一方で BigQuery での自動判別でのスキーマ生成はデータの先頭から 500 レコードを見て判別しています。 (参考: スキーマの自動検出の使用 | BigQuery | Google Cloud)
今回はデータの先頭 500 行に -1 のデータが多数を占めており、INTEGER としてスキーマ生成された後に STRING データが来ていたため発生していました。
この項目が STRING としてスキーマを指定できていれば問題ないため、下記対応を取りました。
- 自動判別でインポートする。エラー無視のオプションを付けておき、インポートを完走させる。
- 生成したスキーマを bq コマンドで取り出し、手動で当該項目を STRING に変更
- 変更したスキーマファイルを使用しインポートする
bq コマンドでのスキーマ取得は下記のコマンドで実施しています。
bq show --format=prettyjson --schema securityhub.data_YYYYMMDD > schema.json
AWS アカウントデータの S3 -> GCS への転送と BigQuery へのインポート
こちらは下記の通りスクリプトで実行します。
AWS の権限は AWSOrganizationsReadOnlyAccess ポリシーが必要なため追加付与します。
#!/usr/bin/env bash set -eu AWS_PROFILE_NAME="xxxxxx" # リスト取得 export AWS_PROFILE=${AWS_PROFILE_NAME} export AWS_DEFAULT_PROFILE=${AWS_PROFILE_NAME} aws organizations list-accounts | jq -rc '.Accounts[]|{"Id": .Id, "Name": .Name}' > account_list.json # GCPセットアップ GCP_KEY_FILE=./auth.json GCP_SVC_ACCOUNT=$(cat ${GCP_KEY_FILE} | jq -r '.client_email') GCP_PROJECT_ID=$(cat ${GCP_KEY_FILE} | jq -r '.project_id') gcloud auth activate-service-account "${GCP_SVC_ACCOUNT}" --key-file "${GCP_KEY_FILE}" --project "${GCP_PROJECT_ID}" # GCSに転送 gsutil -q -m -o "GSUtil:parallel_process_count=1" cp account_list.json gs://securityhub-export-data/ # bq コマンドの初回メッセージを出力済みにしておく bq ls > /dev/null 2>&1 # BQ取り込み bq load --autodetect --replace --source_format=NEWLINE_DELIMITED_JSON Dataset.account_list gs://securityhub-export-data/account_list.json
インポート処理の自動化
前述のインポート処理ですが、手動で毎日実行するには骨が折れますので定期実行を自動で行えるようにします。 弊社では GitLab を使用しているため GitLab-CI のスケジュールジョブにて1日一回実行させるように設定しました。
他にも ECS のバッチジョブや Lambda での逐次実行なども考えられますが、今回は知見のある上記の方法を選択しています。
View の作成と Google DataPortal(DataStudio) での可視化
BigQuery にインポートされたデータを使用しての可視化ですが、可視化しやすいように下記の View を作成しました。
ポイントは下記です。
- ※1: Details は分解して BigQuery に格納しており可視化の際に扱いにくいため、JSON 文字列に再度戻している。
- ※2: Resources は ARRAY のため UNNEST でフラット化している。
- ※3: セキュリティチェック基準名はマネジメントコンソール上では CIS, AWS 基礎 Security ベストプラクティス、PCI-DSS の 3 つ見えるが、内部では異なる種類の場合があるためまとめるように CASE 文を使用している。
WITH s1 AS ( SELECT DISTINCT DATE(d.LastObservedAt) LastObservedAtYMD, d.AwsAccountId, a.Name, d.Description, d.GeneratorId, R.Type, d.Compliance.Status AS ComplianceStatus, d.Title, d.Remediation.Recommendation.Text AS RecommendationText, d.Remediation.Recommendation.Url AS RecommendationUrl, d.ProductFields.aws_securityhub_annotation AS SecurityhubAnnotation, TO_JSON_STRING(R.Details, TRUE) AS ResourceDetails, -- ※1 d.FindingProviderFields.Severity.Label AS SeverityLabel, d.FindingProviderFields.Severity.Normalized AS SeverityNomalized FROM `Project.Dataset.all_data_*` AS d, `Project.Dataset.account_list` AS a, UNNEST(Resources) AS R -- ※2 WHERE AwsAccountId = a.Id AND Compliance.Status = "FAILED" AND RecordState = "ACTIVE" AND Workflow.Status NOT IN ("SUPPRESSED") AND ProductName = "Security Hub" ORDER BY AwsAccountId, FindingProviderFields.Severity.Normalized, Title ) SELECT -- Checkする基準名を出しておく。 CASE -- ※3 WHEN REGEXP_CONTAINS(GeneratorId,".*cis.*") THEN 'cis' WHEN REGEXP_CONTAINS(GeneratorId,"^pci-dss/.*") THEN 'pci-dss' WHEN REGEXP_CONTAINS(GeneratorId,"^aws-foundational-security-best-practices.*") THEN 'aws-foundational-security-best-practices' ELSE NULL END AS CheckType, * FROM s1 ORDER BY Name, CheckType, SeverityNomalized, Type, GeneratorId
作成した view を使用し可視化したダッシュボードが下記になります(モザイク多めなので分かりづらいかもしれませんが) アカウント・セキュリティレベル・チェック項目などをフィルタとしていますので任意の絞り込みで確認できるようになっています
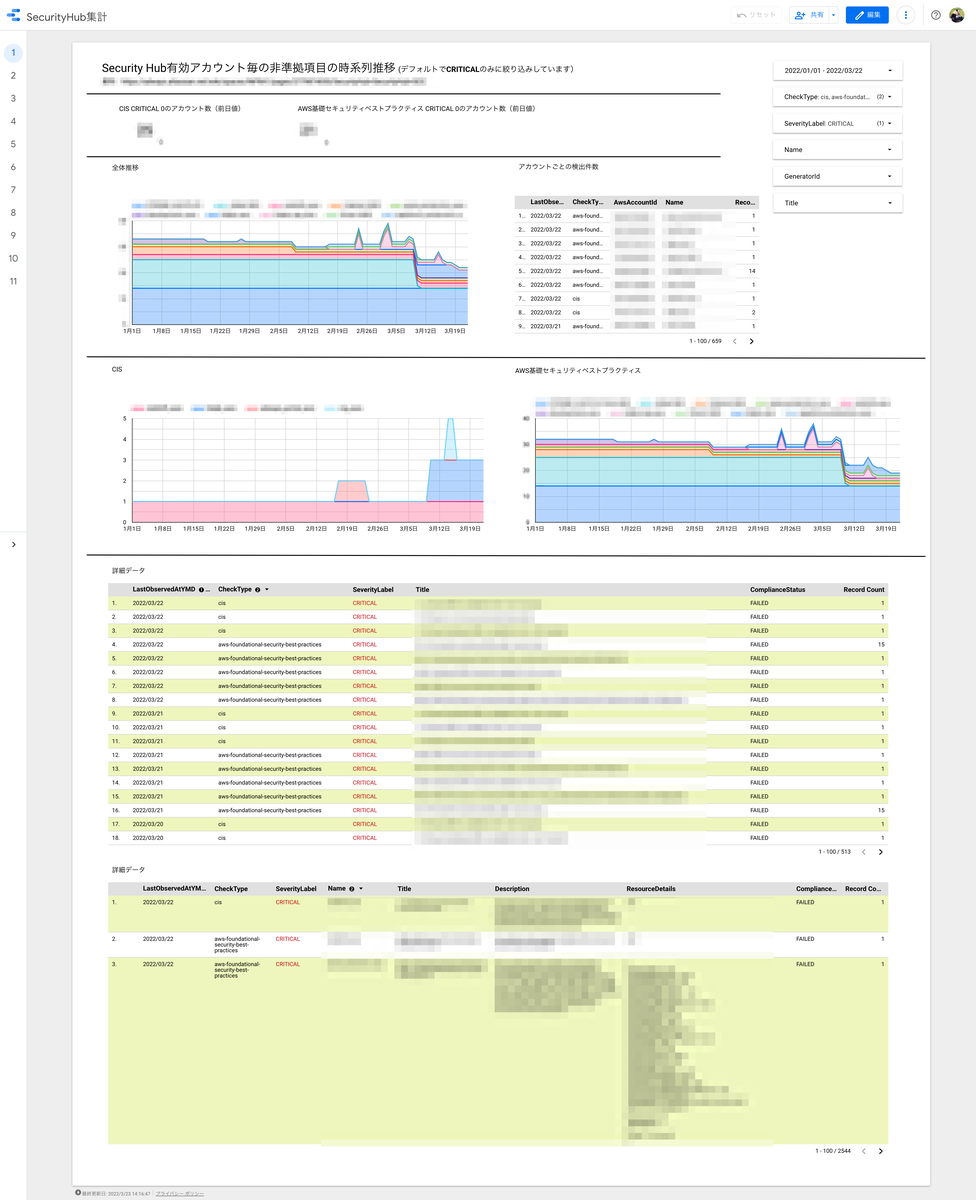
導入後について
ダッシュボードを作成し社内の利用者に公開したところ、下記のようなフィードバックを頂きました
- 自身の管理している AWS アカウントでのセキュリティチェック状況の把握が可能になった
- 複数の AWS アカウントの状況が確認しやすい
- 時系列で表現されているため検出結果の推移がわかり、目標管理での指標や進捗管理に使えそう
- 検出結果の詳細も表示されているためどこのリソースが NG なのか確認できる
- ログインや権限申請等が必要なく、リンク共有のみで確認できる(GSuite は弊社認証基盤にて SSO 連携しているため)
管理者としても Security Hub の管理画面では AWS アカウント名を ID から調べつつ確認していたものが、即座に把握できるようになり便利になりました。また、各アカウントの対応状況など推移も含めて見ることができ、良いものができたと自負しています。
すでにセキュリティ対策が進んでいることは先のダッシュボードのスクリーンショットでもおわかりいただけるかと思いますが、今後もダッシュボードを活用しつつ、さらにセキュリティ対策を進めていきたいと考えています。
余談
今回の方法の活用シーンとして低料金での現状把握があります。 一時的に Security Hub と Config を有効化し検出結果データをエクスポートした後に Security Hub と Config を無効化すれば低料金で現状把握が可能になります。 継続的に有効化するには料金が気になる、という方はこういった活用も可能ですのでお試しください。
終わりに
今回は複数 AWS アカウントの AWS Security Hub 検出結果を時系列で見れるよう可視化してみました。
今回は BigQuery + DataPortal を選択しましたが、おそらく Athena + QuickSight でも可能とは思います。 ただ、おそらくですが今回実施した禁則文字の変換などは Athena でも同様に実施する必要はあると思います。(AWS さんの CloudFormation で Athena への取り込みまでやってくれていると非常にありがたいので期待したいところです)
また、変換とデータベースへのインポート部分は改善の余地があると考えています。今回はバッチ形式で行っていますが、Lambda 等で実施することでほぼリアルタイムの検出結果で更新できると思いますので今後時間を見つけて改善を行っていこうと思っています。
そして、前提にも書きましたが現在は東京リージョンのみ対象としているため、今後マルチリージョンへの対応も実施していきたいことの1つです。
今回の記事が AWS 管理者の方や複数アカウントでの Security Hub をお使いの方の一助になれば幸いです。
最後までお読みいただきありがとうございました。