こんにちは。広告事業本部でアプリケーションエンジニアをしている24卒の茅野(ちの)です。 社会人生活一年目はさまざまなことを経験することができ、あっという間に一年が過ぎました。
私は現在、MediaAnalyzerシリーズ(以下MA)の開発を行っております。 MediaAnalyzerシリーズは、広告の配信結果の分析や最適化を行うために開発されました。 詳しくはこちらのリリースをご覧ください。
本記事では、S3にあるAmazon QuickSightのログを定期的にBigQueryに転送する方法について紹介していきます。
背景
MAではあまり活用できていない人に対し、なぜあまり使っていないのか、具体的にどのような点が使いにくいのかというところをヒアリングし、どうしたらより活用してもらえるのかを考え、改善していくために利用頻度を把握する必要があります。 それだけでなく、MAは毎日適切に使用するためのスキルを習得する難易度が高いため、利用頻度が低いユーザーに対してディレクターやリードの運用者がレクチャーを行うことで、より適切な広告運用ができるようにしたいという狙いもあります。 そのため、MAではそれぞれのユーザーの利用状況を収集し、グラフ化することで利用頻度を把握しています。 この際、MAではTableauを採用していたため、アクセスログもTableauを用いてグラフ化していました。
しかしながら、Google検索広告向けのMA(以下MAG WEB)のみTableauではなく、Amazon QuickSight(以下QuickSight)を使用していました。 QuickSightはAWSのサービスの1つであるため、QuickSightのログを取るには、CloudTrailを用いてS3に出力し、BIツールに出力する場合はAthenaを経由するのが一般的です。 ただし、AthenaのデータをTableauから利用する場合、IAMキーを発行する必要がありますが、アドウェイズでは90日ごとにIAMキーをローテーションしなければいけないというセキュリティルールがあります。 それに対してBigQueryの場合はOAuthでログインすることによりTableauから利用できるようになり、アクセスキーなどを発行する必要がなくよりセキュアなため、S3にあるデータをBigQueryに転送することになりました。
採用した方法
BigQueryへの転送
今回は以下の手順でBigQueryへの転送を行いました。
- CloudTrailを用いてQuickSightのログをS3に出力する
- AthenaでS3にあるログを読み込む
- LambdaからAthenaでクエリを実行し、必要なデータのみを抽出し、結果をS3に保存する
- Google CloudのStorage Transfer Serviceを用いてS3からGCSに転送
- Workflowsを用いてGCSに転送したログをBigQueryにインポート
この手順をまとめたアーキテクチャ図が以下の通りです。
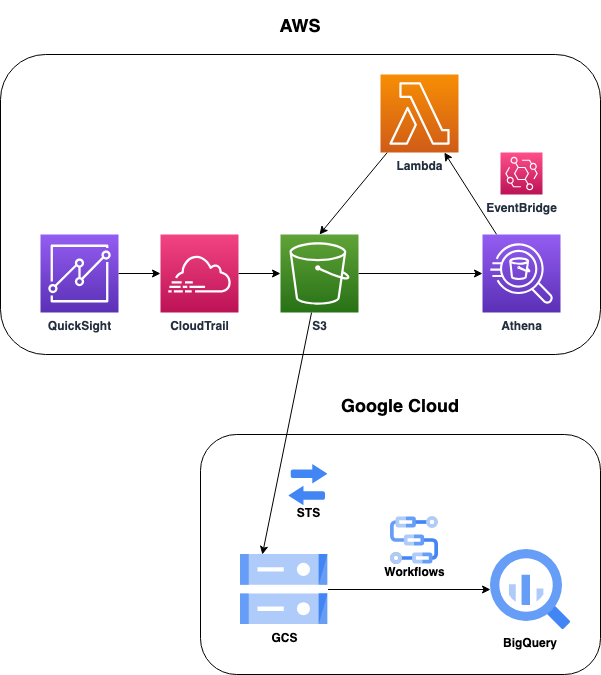
こちらの方法ではCloudTrailで出力したログを直接GCSに転送するのではなく、一度Athenaに読み込み、Lambdaでクエリを実行しています。 一見すると無駄なことをしているように見えますが、以下のようなメリットがあります。
- 料金を抑えることができる
CloudTrailが出力するログにはログイン情報やUAなどさまざまな情報が含まれています。 目的によってはこれらの情報も必要になりますが、今回はアクセスしたユーザー、リソース、日時など一部の限られた情報のみが必要でした。 そのため必要な情報のみを抽出し、転送する容量を減らすことで、転送料金やストレージ料金を削減することができます。
- 実装や引数をシンプルにすることができる
ログファイルは多数のファイルに分割されており、作業中に試行錯誤していたところ、レート上限に引っかかってしまいました。 一日に1回転送する程度ではログファイルを直接GCSに転送してもレート上限に引っかかることはないと思いますが、今後のメンテナンスのしやすさなども考慮して1つのファイルにまとめる方法を採用しました。
さらに、Workflowsを用いてBigQueryにインポートする際にログファイルのパスを指定する必要があるのですが、ワイルドカードが1つしか使えません。 そのため、リージョンごとかつ日付ごとに分割されている場合、インポートするリージョン、日付を列挙する必要があり、実装や引数の指定が煩雑になることがありますが、1つのファイルにまとめることでこれらの問題も解消できるというメリットがあります。
アクセス回数のカウント
前述した通り、今回アクセスログを取る目的の1つとして、利用頻度を把握するというものがありました。 MAではさまざまな粒度で広告配信の結果を確認することができ、それぞれの粒度でタブが分かれています。 そのため、利用頻度を正しく把握するためには、単にMAへのアクセス回数を記録するのではなく、それぞれの粒度をしっかりとチェックできているか、つまりタブを切り替えているかを記録する必要がありました。
しかしながらタブを切り替えた際に出る粒度のログはなく、一番近い粒度がそのタブの表示内容に合わせて実行されるクエリのログでした。 こちらはタブを切り替えたタイミングと一致しているものの、タブによって表示内容が異なるため、一度に出力されるログの数もばらつきがありました。 そのためこの粒度では正しく利用頻度を把握することはできませんでした。
そこで、一度タブを切り替えるとクエリを実行したログが連続して出ることに着目し、BigQuery上で秒単位で連続するログを1回のタブ切り替えとしてカウントするビューを作成することで解決しました。
採用しなかった方法
S3から直接BigQueryにインポートする方法
Google CloudにはBigQuery Data Transfer Serviceというものがあります。Amazon S3 転送 | BigQuery | Google Cloud この機能を使うことで、定期的にS3にあるファイルを読み込み、直接BigQueryにインポートすることができます。 こちらの方法が最もシンプルにできると思いますが、この機能を使うためにはアクセスキーを発行する必要があります。 これも前述したようにアクセスキーを使わない方法の方が望ましいため、今回はこの方法は採用しませんでした。
CloudTrailが出力したファイルを直接GCSに転送する
前述した通り、CloudTrailが出力するログには不要な情報が含まれている上、多数のファイルに分割されています。 これを転送しようとすると無駄な料金がかかってしまったり、実装が複雑になりメンテナンスコストが増えてしまったりします。 そのため今回はこの方法は採用しませんでした。
今後の課題
前述した通り、現在は連続したクエリを実行した際のログを1回のタブの切り替えとしてカウントしています。 しかしながらこれには欠点があり、短時間でタブを切り替えた場合、次のログが一秒以内に出てしまい、正確にカウントできません。 これは仕様として仕方ないことになっていますが、より良い判別方法やログの出し方など他に良い方法があれば改善したいと考えています。
また、Lambdaの実行、GCSへの転送、BigQueryへのインポートのタスクはそれぞれ決められた時間に定期実行するようになっています。 そのため前のタスクが失敗しても次のタスクが実行されてしまいます。 そこでファイルの転送をトリガーにするなどし、前のタスクが成功した時のみ実行することによって、無駄な実行を防げるようにしたいと考えています。
最後に
S3にあるファイルをBigQueryに転送する方法に関する情報はありましたが、大量のファイルを定期的に転送する方法に関する情報はあまりなかったため、どのようにやるのが一番いいのかについては悩みました。 また、CloudTrailで出力されるQuickSightのログについての情報もあまりなく、実際のログを見ながらどのようになっているのかを調査するのは大変な部分もありました。 しかし色々な人に相談しながら試行錯誤し、最終的にはきちんと転送することができました。 同じようにS3からBigQueryに転送したい方や、QuickSightのログを分析したい方の参考になれば幸いです。