どうも〜、お久しぶりです。
エージェンシー事業のエンジニアチームでユニットマネージャーをしていますぬまちゃんです!
エンジニアブログを書くのは新卒以来なので、4年ほどぶりってところです。
あの頃はエンジニアリングメインでしたが、今はマネジメント業務も行うようになり、「成長したなあ」「あっという間だったなあ」と感じる今日この頃です。
マネージャーとして奮起しているぬまちゃんが久しぶりに新しいことに挑戦したので、そのことを伝えていこうと思います。
背景
昨今、自分が所属している部署ではGCPのBigQueryにデータを集め、いろんなデータと組み合わせたり、ビジュアライズしたりとデータ活用が盛んに行われています。
自分のチームにもその波がやってきた訳なのですが、担当サービスはAWS上に構築されていて、DBもAurora MySQLを使っています。
なので、GCPのBigQueryにデータを集めるにはなんらかの方法で送信してあげないといけませんでした。
そこで白羽の矢が立ったのはGCPのDatastreamというサービスでした。
やったこと
準備編
まず最初に、Datastreamのレプリケーション方法には3つ種類があります。
超かいつまんで説明すると、
| IP許可リスト | フォワードSSHトンネル | VPCピアリング |
|---|---|---|
| DatastreamからDBへアクセスできるようにDatastreamのパブリックIPアドレスを許可して、接続する方法。 | 踏み台サーバーを用意してDatastreamからのアクセスを許可し、踏み台サーバーからDBへ接続する方法。 | VPC同士のプライベートネットワーク接続を利用してDatastreamとDBを接続する方法。 |
今回は「フォワードSSHトンネル」の方法を選択しました。
理由としては、
- プライベートネットワーク接続を確立していない
- DBにパブリックIPアドレスの接続を許可できない
- 弊社のインフラルールではDBが外部のネットワークへ接続することを許可していない
- そもそもセキュリティグループをガチガチに設定しているので穴を空けたくない
- 踏み台サーバーの構築が容易にできる環境が整っている
ところで、弊社にはAgency事業部や自社プロダクトの事業部の他に、技術本部という部署があります。 そこにはインフラの専門家たちが居て、今回のDatastreamのレプリケーション方法について相談させてもらいました。 こうやって専門的なことにも相談に乗ってくれるので、弊社のインフラエンジニアは優秀だなあと常々思っています。
フォワードSSHトンネルの方法で接続するのが決まったので、
Terraformを使ってコードを記述し、EC2の起動テンプレートとAutoScalingを使って勝手に終了しても復活するようにしました。
また、突然の終了にも気づけるようにMackerelでの死活監視も導入しました。
次に、避けては通れない問題の対応です。
Datastreamへレプリケーションするには、Aurora MySQLの binlog_format を ROW に変更する必要があり、それにはDBの再起動が必要でした。担当サービスは会社の基幹システムのような位置付けでもあり、クライアント様などにも利用してもらっている機能もあるためサービスを停止するわけにはいかなかったのですが、メンテナンス(サービスの一時停止)の時間をいただいて作業することができました。
夜中の作業ではありましたが、しっかりと手順書を作ったおかげでスムーズに進めることができました。
起動編
必要なもの
- 踏み台サーバー
- SSHするユーザーの作成
- Aurora MySQLの変更 (参考: Amazon Aurora MySQL データベースを構成する)
binlog_formatをROWにする- バックアップの保持期間を7日にする
- バイナリログの保持期間を7日にする
- アクセス用のMySQLユーザーの作成
1.ストリームの詳細の定義
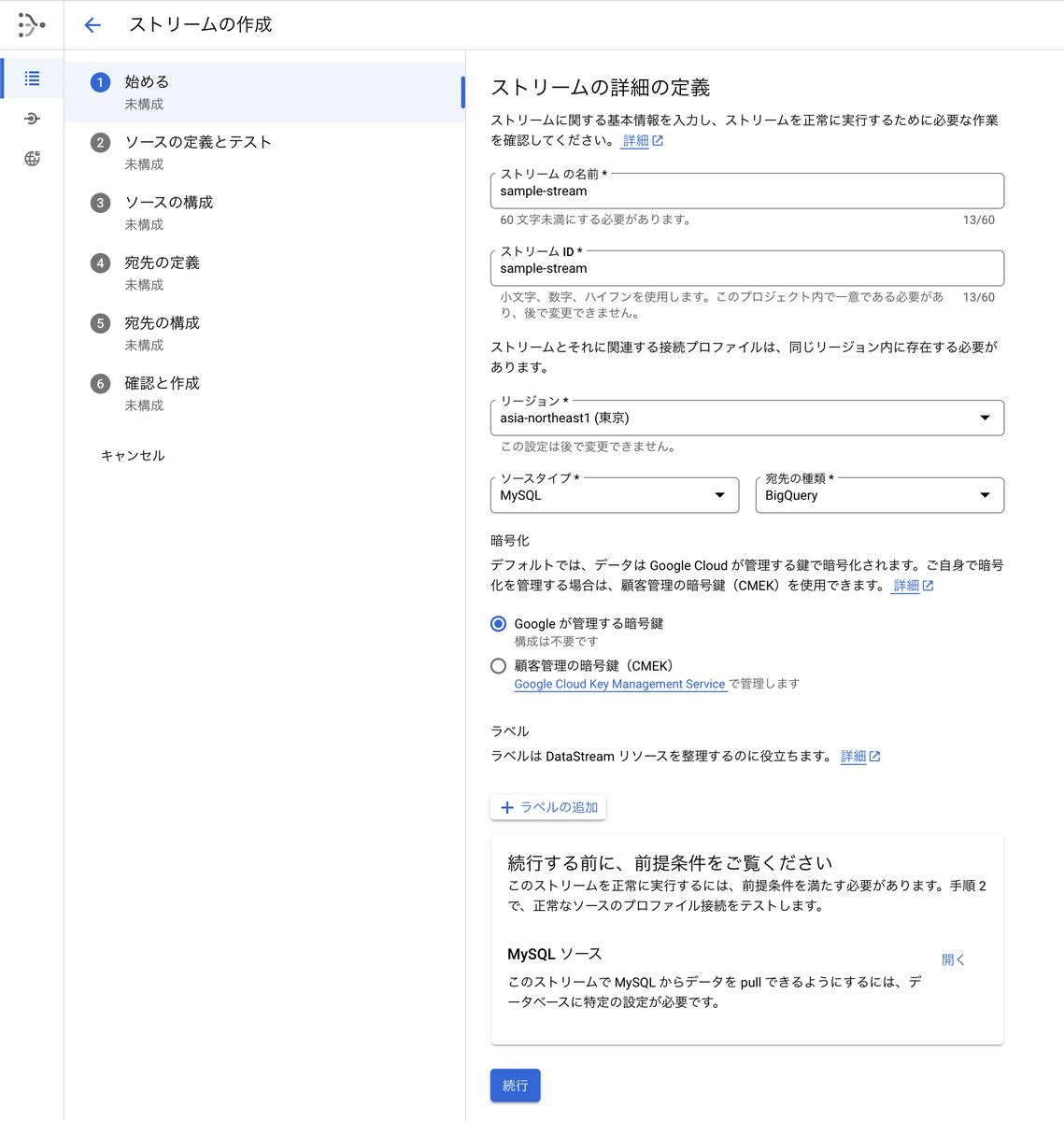
今回はAurora MySQLからBigQueryなので、ソースタイプは「MySQL」宛先の種類は「BigQuery」にします。
2. MySQL 接続プロファイルの定義(Aurora MySQLとの接続について)
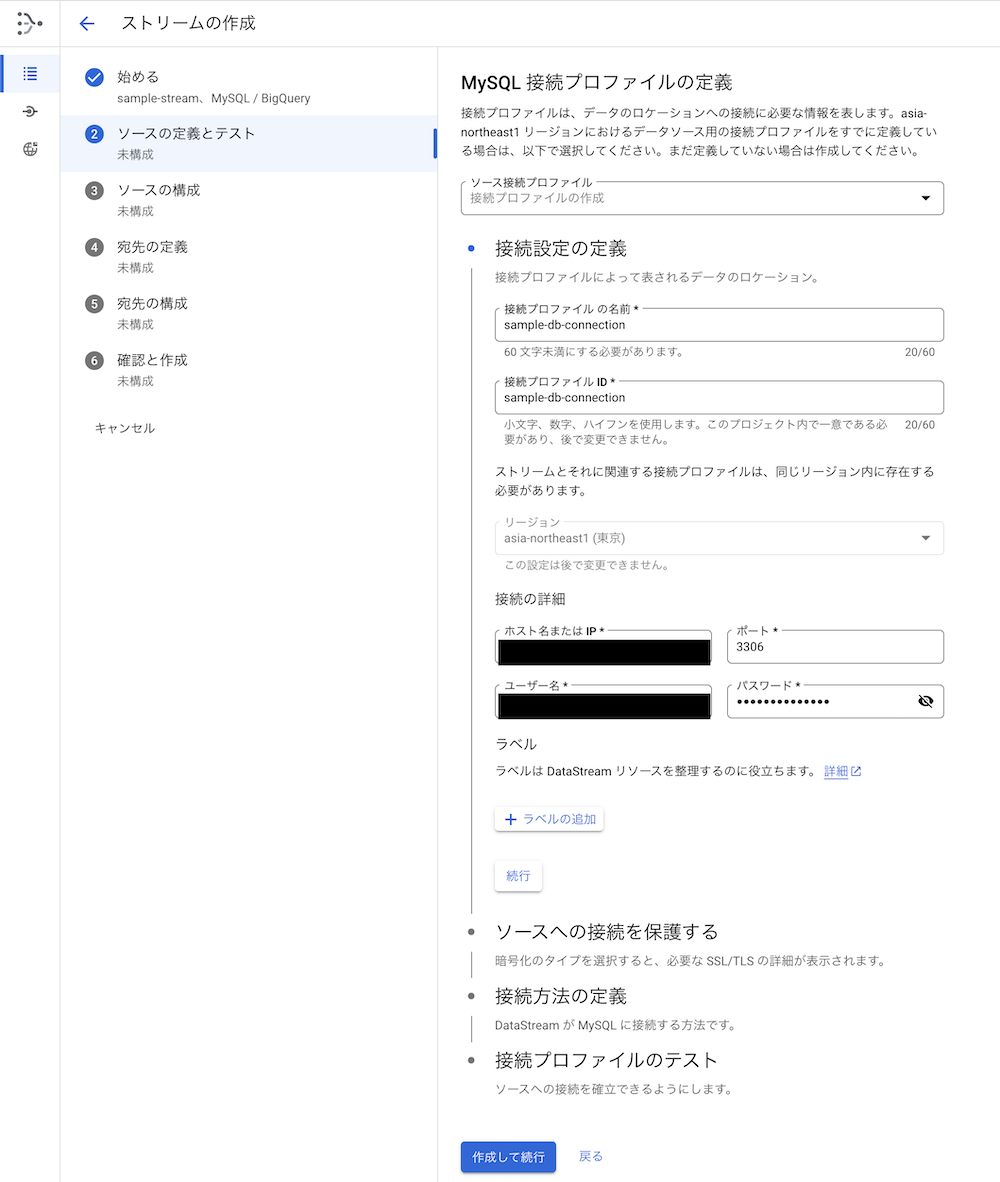
ここではMySQLに接続するためのプロファイルの情報を入力します。
「ホスト名またはIP」のところにはAWSのRDSの管理画面にある「エンドポイント名」を指定します。
ユーザー名やパスワードは作成したアクセス用のMySQLユーザーのものを入力します。
3. MySQL 接続プロファイルの定義(SSH接続について)
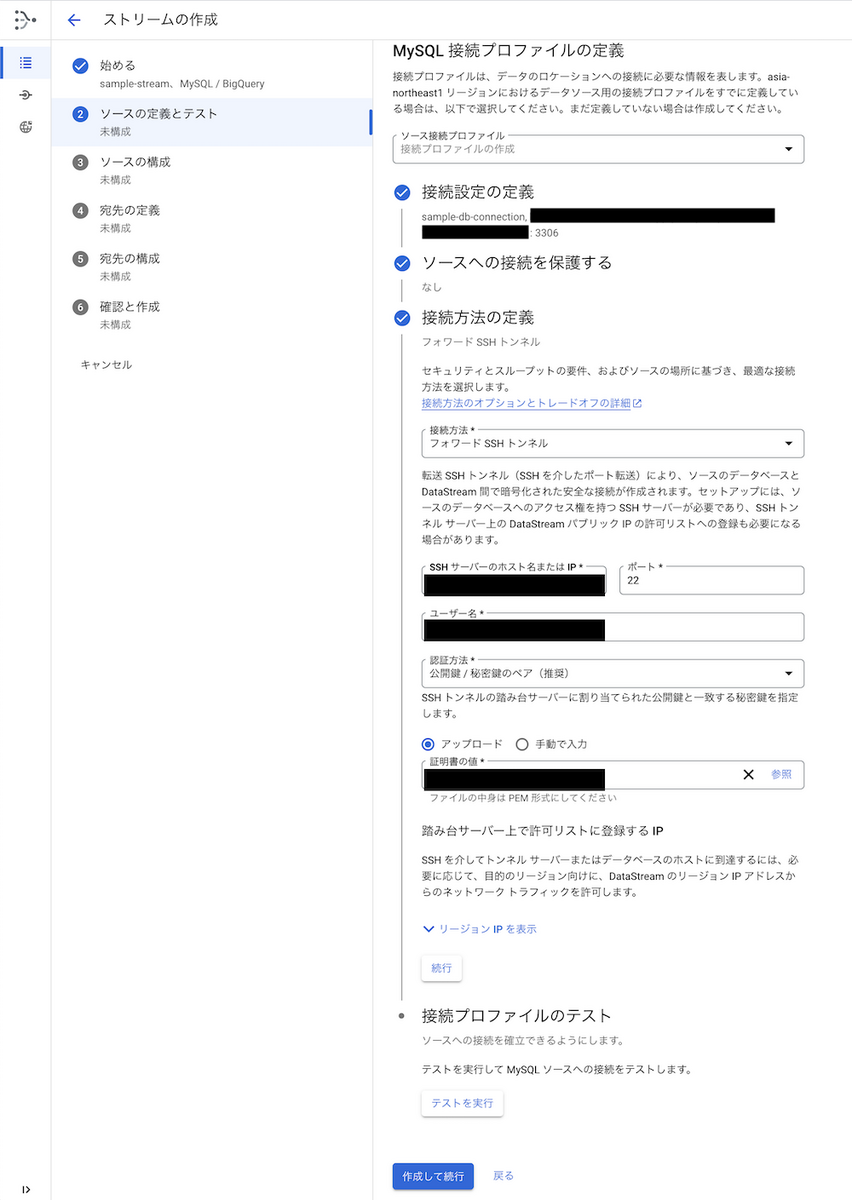
接続方法は選定した「フォワードSSHトンネル」を選択し、踏み台サーバーの情報とSSHするユーザーの情報を入力します。
4. ストリームのソースの構成
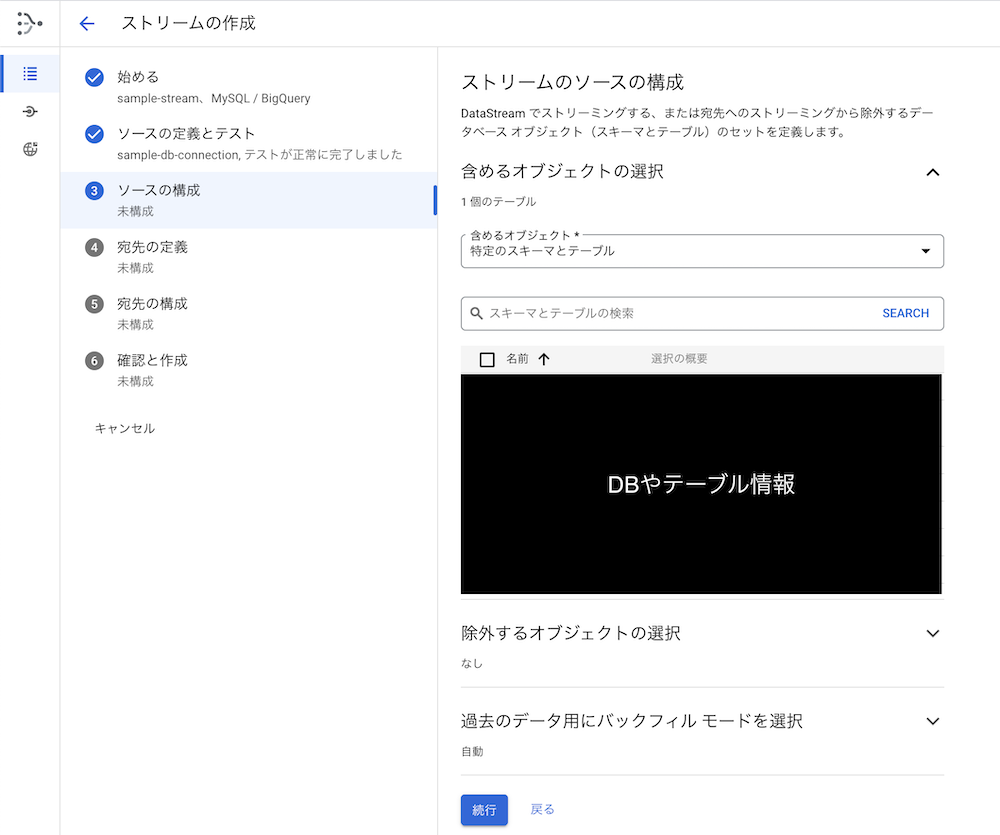
ここではストリーミングするDBやテーブル、カラムの設定をします。
除きたいデータがある場合はここで選択して除外します。
5. BigQuery 接続プロファイルの定義
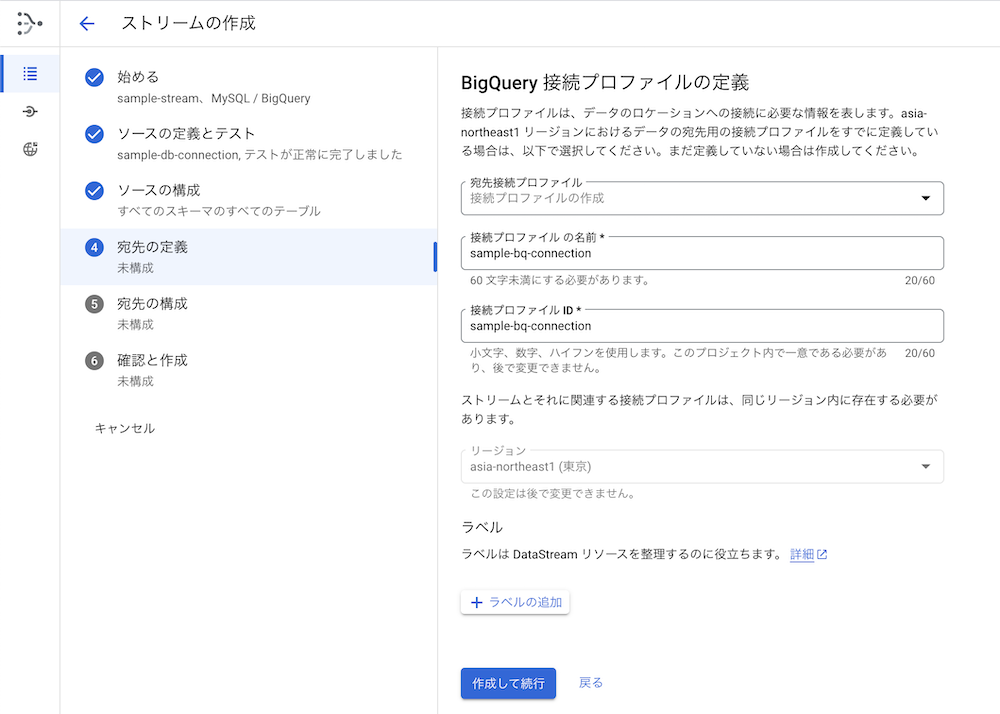
貼り付けた画像の通り、接続プロファイルの名前を設定します。
6. Datastream から BigQuery への接続の構成
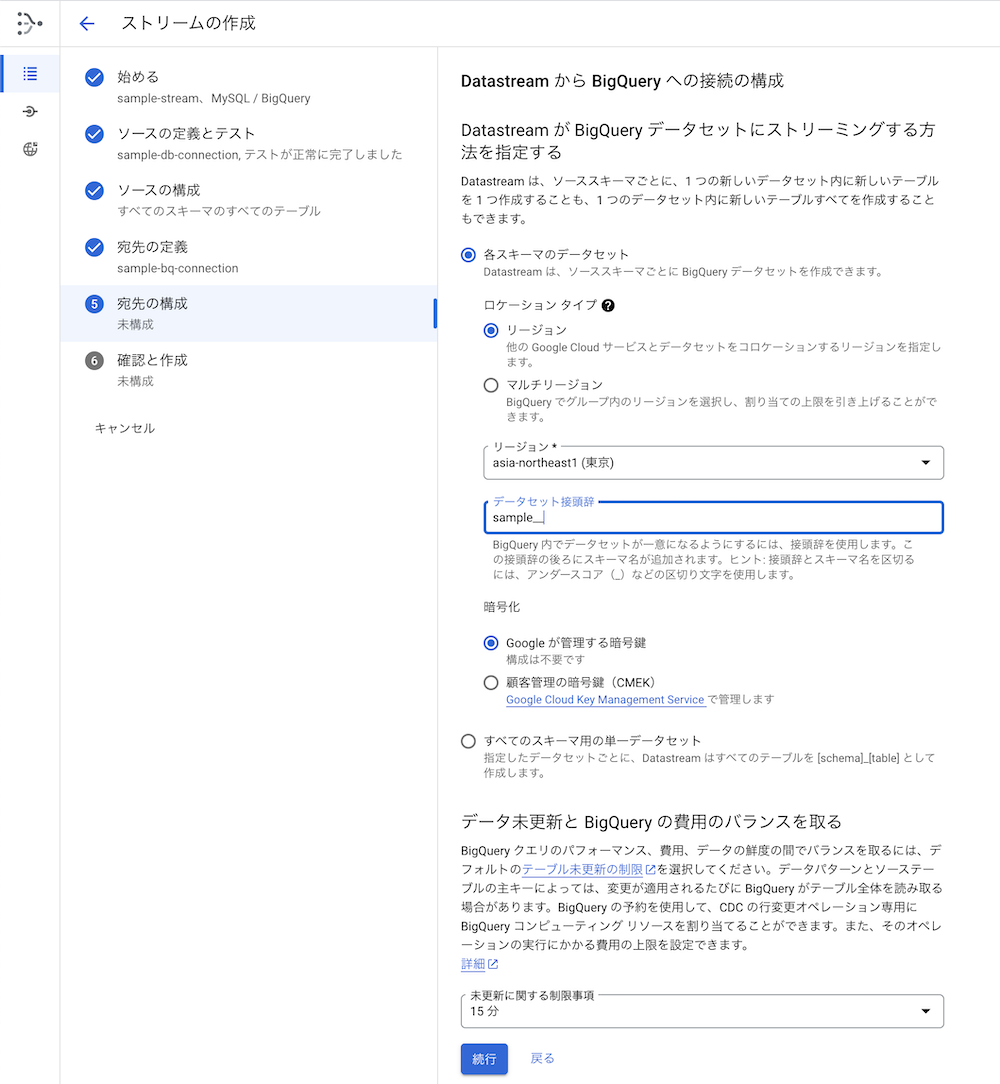
データの更新頻度は15分に設定しました(デフォルト)。
短ければそれだけリアルタイムに近くなりますが、料金が多くかかってしまうためこの数字にしています。
もし、リアルタイム性の需要が上がれば検討したいと思います!
7. 確認
最後の確認画面ではこれまで設定した内容が全て閲覧できると思います。
問題がなければそのまま作成し、レプリケーションを開始すればBigQueryへデータが保存されて行きます。
まとめ
久しぶりのエンジニアブログで少し緊張しましたが、いかがだったでしょうか?
Datastream自体の立ち上げはとても簡単に行えるので、今後のデータ活用がさらに活発になるのではと思っています!
ただ、やり残したことが一つあります。
担当サービスの構築にはTerraformを使っていてほぼ全てがIaCになっているのですが、今回のDatastreamはGCP上へのデプロイ方法が確立できていないため後回しにしてしまいました。
この課題点はどこかのタイミングで対応したいと考えています。
では!