みなさんこんにちは。ADWAYS DEEEでアプリケーションエンジニアをしています、中村です。
この記事では、自分が主導して行った2.8億レコードのデータが入ったDBのスキーマ変更のタスクに関して、どのように進めていったか、及びその中で感じたことを振り返りながら書いていきたいと思います。
特に、今回は課題点のみがふわっと与えられて、調査や方針決めから実装まで一通りやり切る、という自分にとって初めての経験をしました。加えて、技術的に初めて触る部分もありました。その辺りの苦労や学びも併せて書いていけたらなと思います。
DBスキーマのマイグレーション事例を探しているエンジニアの方には事例の参考として、2~3年目で少し粒度の大きいタスクに初めて取り組むエンジニアの方には一つの体験談として、読んでいただけたら嬉しいです。
背景と目的: 広告プラットフォーム連携の最適化のための精度改善
自分の部署では、自社サービスのデータを利用して広告の最適化を図る施作を複数実施しています。
今回の仕事では、その中でも広告プラットフォーム側の広告識別子(広告ID)を用いる必要がありました。
この広告IDはJANetのDBの中に入っているのですが、保存できる文字数が255文字(VARCHAR(255))までとなっていました。
そのため、256文字以上の文字列は切り捨てられた状態で連携しており、広告最適化の精度に悪影響を与えていました(✅課題点)。
この精度改善が、今回の仕事の目的となります。
概要: 行ったこと・所要期間
スキーマ変更前(1ヶ月強)
スキーマ変更前には、主に仕様面と技術面の調査と、検証環境での検証をしました。
それらを通して、課題の懸念点や観点を踏まえた解決の案を複数提案し、チームのエンジニアやサービスのディレクターにレビューしてもらうことで方針を固めていきました。
表1: 実際の作業で調べたこと・やったこと、および所要期間
| 作業分類 | 調べたこと・やったこと | 所要期間 |
|---|---|---|
| 仕様面の調査 | 実際に移行するDBのテーブルの一覧及び必要性 テーブルがどのようにシステムから使われているのか (参照系or更新系) 懸念点や観点の洗い出し |
2週間 |
| 技術面の調査 | 実際に使うクエリのMySQLドキュメント、及び使えそうなツールの洗い出し 他社のDBのスキーマ変更の事例 (なるべくレコード数の規模が近いもの) Amazon Aurora(以下Aurora)やGCPのBigQueryなど、実際に使うクラウドサービスのAPI |
3週間 (検証や仕様面の調査と並行) |
| 検証 | 本番DBのデータをクローンした検証環境の用意 実際にクエリを叩くorツールを使う→かかった時間を計測 |
2週間 |
決まった方針
- 今回の連携に際し必要なテーブルのみ変更する
- そのうち、不必要な期間のデータ(半年以上前)は削除することでなるべくレコード量を減らす
- 過去、及び未来に作られるテーブルについては、変更をリリース前後にまとめて行う
- 現在作られているテーブルについては、対象のレコード量によって対応を変える(理由: 途中で何か起きた時にロールバックしやすくするため)
- レコード量の少ない(~50万レコード)テーブルは、alter tableを直で叩く
- レコード量の多いテーブルはスキーマ定義を更新した新テーブルを作り、そこに既存のデータをselect&insertしていく
スキーマ変更(深夜対応: 3時間)
変更は本番DBに触るため、なるべく影響の少ない深夜2:00~に行うことになりました。
(意外とリアクションついてみんな起きてるんだな〜〜と驚いた記憶がありますw)
事前に開発環境でテストしたSQLを用意し、それをひたすら叩いていきました。減らしたとはいえ2億レコードくらいあったので100万レコード前後の大きさに区切りながらselect&insertしていきました。 当日は特に大きな問題もなく、スムーズに終えることができました✌️
スキーマ変更後(1週間)
残作業として、一部既存のデータのBigQuery移行、過去と未来分のテーブルについてのスキーマ定義変更を行いました。
ここから、実際に取り組んだことについて、意識したことや考慮した上でやらなかったことなどを含めて書いていきます。
実際に取り組んだこと
仕様面の調査
このタスクが与えられた時点で、自分は対象となるDBのテーブルについてはなんとなく聞いたことあるくらいでした。システムについても今まではインフラ面の改修が多く、アプリケーション面の見識はほぼなかったです。一応、「なんとなくこの辺が改修ポイントになりそう」みたいな部分は事前に軽く与えられていたので、その部分から調査を開始しました。
表に書いた調べたこと・やったことについて、意識したことを書いていきます。
実際に移行するDBのテーブルの一覧及び必要性
広告IDが入りうるカラムを持つテーブルを一通り洗い出して表にまとめました。また、スキーマ定義を更新するタイミングについて、一緒に更新しなければいけないもの、後でもいいもの、洗い出したが不要だったものの3種類に分類し、なるべく一緒に更新しなければいけない量が少なくなるように調整しました。
更新する量を減らすための具体的な例として、社内レポートシステムのデータベースについて紹介します。 レポートシステムの体験向上のため、既存のデータベースとアプリケーションとは別に社内レポート専用のデータベースとアプリケーションが存在しています。 データ量が多いため、一定の条件下では抽出期間に制約がある仕様ですが、社内レポート専用のデータベースには過去データが保持されたままでした。 そこで、数年前の古いデータは既に使われていないのではないか?と思い、調査をしました。具体的には、アプリケーションのコードを読み(技術面の影響)、ディレクターにも確認(ビジネス面の影響)をしてもらいました。その上で、不要と判断されたデータについてのみ削除を行いました。
このデータ削除を行う前、一番大きいテーブルが2.8億レコードでした!!
このデータ削除により、テーブルは最大で約2億レコードまでスリム化することができました。
ここで学んだことは、減らせる仕事は最初に減らしておくということです。一覧を洗い出した段階でそもそも要らないテーブルを選別しておくことで、単純に後の検証での工数が削減できます。関心ごとも減らせるので良いなと思いました。
テーブルがどのようにシステムから使われているのか(参照系or更新系)
テーブルを選別した後、そのテーブルに向いているクエリや頻度をAmazon RDSのPerformance Insightsを使って調査しました。ここは厳密にやるとキリがないので、時間がかかる傾向のある、かつよく叩かれているクエリを軽くチェックするくらいにとどめました。
調査や設計全般に言えることですが、やろうと思えばいくらでも調べられます。
なので、ある程度のところで見切りをつけるのも大事になってくるかなと思います。
懸念点や観点の洗い出し
エンジニア目線では、テーブル追加、及びスキーマ変更の際のダウンタイムの発生の有無および長さ、単純な開発コストに加えて運用コスト(拡張性やメンテナンス性)がありました。営業目線では、管理画面からデータの調査・確認ができることが条件でした。 両者の合意が取れるような方針を考えることを意識しました。
ほぼ全ての仕事は合意をとっていくことで進んでいきます。
技術面の調査
実際に使うクエリのMySQLドキュメント、及び使えそうなツールの洗い出し
selectやinsert文については使ったことがあるので軽く確認するくらいでしたが、alter tableについてはあまり使ったことがなかったのでしっかり調べました。
また、online(ダウンタイムが発生しない)のままスキーマのマイグレーションができるツールとして、pt-online-schema-changeやgh-ostも調べました。
参考
しかし、今回の要件には合わなかったので(検証はしましたが)採用は見送りました。具体的に合わなかったこととしては、これらのツールを使うとalter tableを普通に叩くより遅くなること、合計の作業時間が3時間を越えると一回の深夜対応では厳しくなること(なるべく深夜対応を何度もやりたくない!)、データの差分チェックツールとの整合性の担保が難しくなる、などが挙げられました。
他社のDBのスキーマ変更の事例(なるべくレコード数の規模が近いもの)
他社の事例をたくさん集めることを意識しました。ツール名やクラウドサービス名を組み合わせて検索することが多かったです。
その中でも特に、何を考えてどういう手法を採用したのかが書いてあるブログはとても参考になりました。
参考(一部)
Amazon AuroraやGCPのBigQueryなど、実際に使うクラウドサービスのAPI
一部テーブルのデータはGCPのBigQueryに移行することで調査可能な状態にすることになりました。このタスク自体はスキーマ変更の後に行ったものですが、その過程でクラウドサービス間のデータ移行について知見を深めることができました。
大体コンソールからできることは限られています。
なので、APIのオプションを調べた方が早いということも学びました。
また、今まで初めて触るサービスはコンソールから操作しがちでしたが、
どんなAPIがあるのかまず一回見てみるようになりました。
検証
本番DBのデータをクローンした検証環境の用意
JANetはDBのAWS移行が進んでいるため、Auroraのクローンを作成することで本番環境のデータを使った検証が容易に可能です。クラウド化の恩恵ですね。
参考
ただし、本番と違ってリクエストは全く来ない状態での検証になるため、多少速度が良い方に出てしまうことに留意して行いました。データの規模はほぼ同じになるため、参考値程度の認識です。
実際にクエリを叩くorツールを使う→かかった時間を計測
洗い出した各テーブルに対して実際にクエリを叩き、timeコマンドでその時間を計測しました。
データを集める目的は、実際に合計どれくらいかかるか見積もるのもそうですが、どちらかというと説得材料を実測データとして集めるためという側面が大きかったです。
「推測するな、計測せよ」という言葉がある通り、推測だけで物事の方針を決めることは良くないこととされています。また、レビューしてくれるエンジニアの先輩も自分より仕様面に明るい人、技術面に明るい人、など得意な分野が異なります。
それらの人を巻き込んで、時には議論しながら説得して進める必要がありました。一朝一夕に仕様面や技術面に突出することは不可能なので、自分が使える実測データという武器を携えて、方針を確定させていきました。
スキーマ変更
当日は、左側のディスプレイ1でitermを6つに分割表示させた環境で作業しました。そのうち5つをselect&insertのクエリ(大体1回クエリを叩くと10分弱かかる)、1つをalter tableを叩くために使用しました。また、右側のディスプレイ2でIOPSの監視をしつつ、異常が起こっていないことをモニタリングしながら進めました。以下の図にそのイメージを示します。
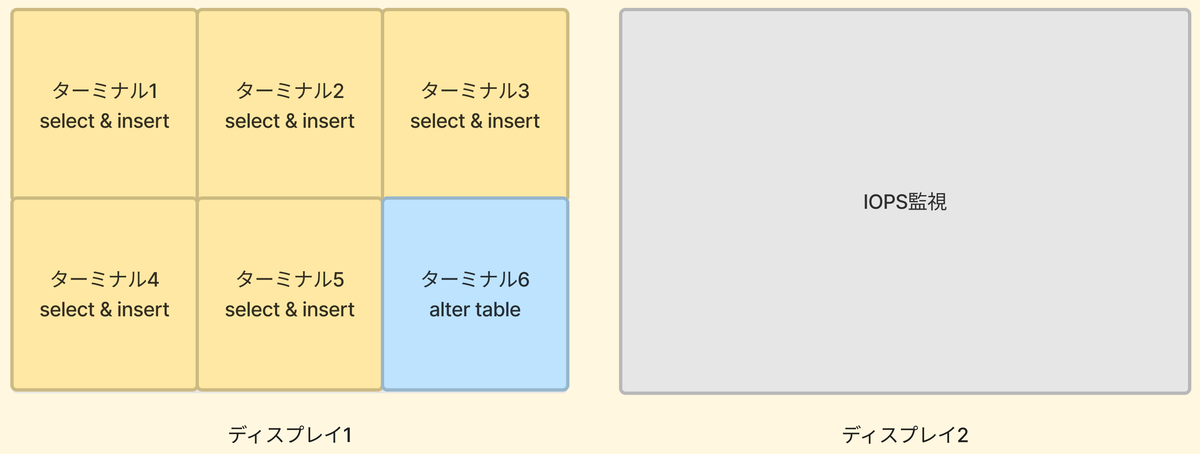
MySQLはマルチスレッドなので、ある程度まで並行する分にはちゃきちゃき捌いてくれました。
最後全ての作業が終わった後、select count(*)して数字がぴったり合った時とても安心しました。
まとめ
今回の仕事を経て得た学びを以下にまとめます。
- 仕事の進め方
- 減らせる仕事は早い段階で減らしておく
- そもそも変更が必要かどうか?
- レコード数を減らせないか?
- どうしても一緒に変更する必要があるもの以外は分けることで、なるべく一回に変更する量を少なくする
- 調査はある程度のところで見切りをつける
- 実測データを説得材料として集める
- 減らせる仕事は早い段階で減らしておく
- 技術面
- 要件を把握した上で、手段は意図を持って選ぶ
- 調べた上で使わないこともよくある
- クラウドサービスはコンソールからではなく、APIでできることを調べるほうが選択肢が広いことが多い
- 要件を把握した上で、手段は意図を持って選ぶ
このタスクに取り掛かる前は、スキーマ変更なんて新しく追加するか変更するかしかないのでは?と思っていました。しかし、仕様を知るにつれてデータが多いテーブルが複数あったり、いろいろ考えること・調べることが多いと分かりました。それに伴って学びもとても多かったです。
これからは(具体的な仕事ももちろんやるとは思いますが、)さらに抽象的な課題に対して、扱ったことのない技術を用いて解決していくこともあるかなと思っています。なので、今回の仕事で得た学びを忘れずに進めていこうと思います!