こんにちは佐藤です。
今回はサービスのデータ分析基盤を作成する際に使用したDataformについて紹介させていただきます。
背景
現在、広告部署に所属する私たちのチームは自社のサービスデータと外部データを分析してユーザーの利用率向上につながる仮説検証をおこなうプロジェクトを進めています。
その中で様々なデータをTableauを用いて分析しており、データソースとして主にBigQueryを使用しているのですが、現状、分析データの加工、集計処理についてBigQueryのスケジュールされたクエリで作成したりtableau側のカスタムクエリで作成したりと対応方法がバラバラで管理自体ができていない状態でした。
それによって分析でどのデータが使われているのか分からない、どれがレビュー済みのクエリなのか分からないといった事象が度々発生していました。それを解消するためにデータの加工、集計処理を管理する仕組みを作成する必要がありました。
また、それと同時にデータ分析基盤を整える必要もありました。既存のデータ分析基盤は世間一般的なデータレイク、データウェアハウス、データマートといったデータ基盤の構成にはなっていなく、データレイクから都度都度必要なクエリを作成している状態でした。
- データの加工、集計処理(クエリ)の管理をしたい
- データ分析基盤を整えたい
以上の理由からデータパイプライン管理サービスであるDataformを導入しました。
類似サービスついては色々ありますが、以下の理由からDataformを採用しました。
- 自社で導入実績がある
- 他の部署で導入実績があり、導入時のノウハウを聞くことができる
- 依存関係がわかりやすい
- 管理画面上でデータの依存関係を図で確認することができる
- クエリに対してテストを書くことができる
- 生成されたデータの品質をテストすることができる
- 管理画面で追加、修正ができる
- 基本的に管理画面で開発が完結する
Dataformについて
Dataformはデータパイプライン管理ツールでELT(Extract/Load/Transform)処理のTを管理するツールです。
テーブルの定義や処理をSQLXという形式で記述します。SQLX自体、SQLを拡張した形式なのでSQLが分かる人であれば記述のための学習コストは低いと思います。
今回のプロジェクトではBigQueryでしか使用していませんが、BigQueryの他にもRedShiftやAzure SQL Data Warehouse、Snowflake、Postgresと連携が可能だそうです。
導入して良かったこと
依存関係がわかりやすい
選定理由でも書きましたが、データの依存関係について管理画面上から以下のような形で確認することができます。
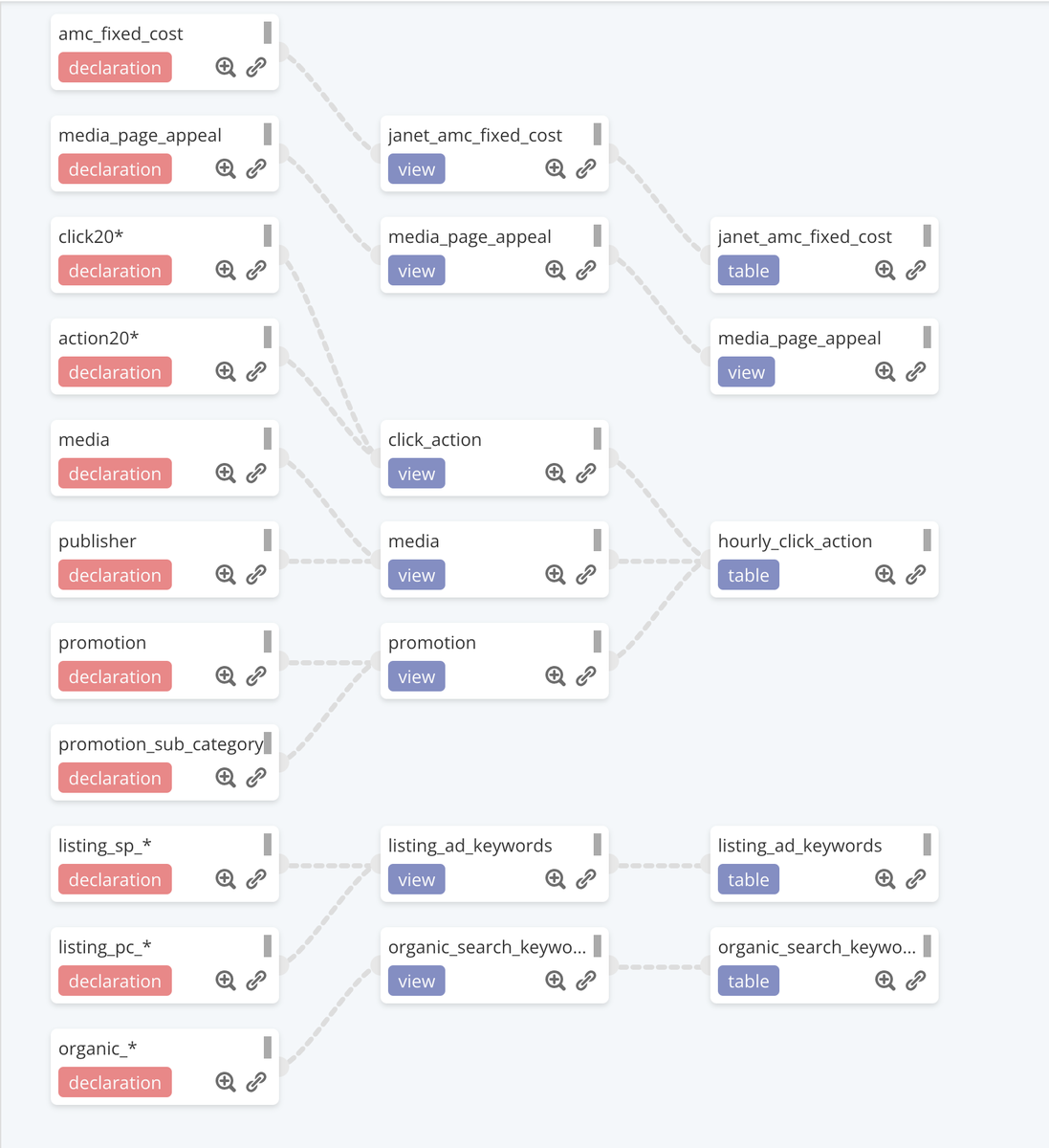
設定自体も簡単で、 Dataformのref()関数を使うことで依存関係を設定することができます。
例えば、ソースデータとしてpromotionテーブルが以下のように定義されている場合、
config {
type: "declaration",
name: "promotion",
description: "プロモーション"
}
promotionテーブルを利用する側で以下のように定義すると
config {
type: "table",
name: "promotion_list",
description: "プロモーションリスト"
}
SELECT * FROM ${ref("promotion")}
このように依存関係を設定することができます。

なお依存関係を設定しておくと、集計処理を実行する際も依存関係の順序で実行されます。
仮に上流のクエリの実行やテストが失敗した場合はそれ以降の処理は実行されません。
クエリのテスト
Dataformではassertionを使用してデータ品質についてテストすることができます。
記述方法については簡単で、configの設定としてテストしたい内容とテストするカラムを記述するだけです。
例として、promotionテーブルからpromotion_listテーブルを作成した際、promotion_nameがnullでないかテストするには以下のように書きます。
config {
type: "table",
name: "promotion_list",
description: "プロモーションリスト",
columns: {
promotion_id: "プロモーションID",
promotion_name: "プロモーション名"
},
assertions: {
nonNull: [
"promotion_name"
]
}
}
SELECT
promotion_id,
promotion_name,
FROM
${ref("promotion")} AS promotion
assertionでは以下の内容についてテストすることができます。
- ユニークな値かの確認(uniqueKey)
- nullではないかの確認(nonNull)
- 条件を満たしているかの確認(rowConditions)
生成されたデータのテストが簡単に記述できるのでDataform導入後には、チーム全体でデータのテストを書く習慣がついてきたと思います。
工夫した点
今回、Dataformを使用してデータ分析基盤を整えていく中での工夫について共有します。
フォルダの構成について
Dataformプロジェクトのディレクトリ構成は公式のベストプラクティスを参考にしました。
First steps with your Dataform project | Dataform
ディレクトリ構成
- definitions/sources
- データソースの定義
- データレイク
- definitions/staging
- プロジェクト内で使用する中間データセットの定義
- データウェアハウス + α
- definitions/reporting
- レポートやBIツールで使用するデータセットの定義
- データマート
データセット名、テーブル名について
Dataformでは以下のように定義すると、dataform.jsonのdefaultSchemaで定義されているデータセットに対してテーブルやビューが作成されます。
config {
type: "table",
name: "promotion_list",
description: "プロモーションリスト"
}
select * from ${ref("promotion")}
しかし、config内でschemaを定義することで出力先のデータセットを変更することができます。
config {
type: "table",
schema: "dataform_dwh",
name: "promotion_list",
description: "プロモーションリスト"
}
select * from ${ref("promotion")}
生成されたデータをデータウェアハウス、データマートと分けたかったので、"~dwh"や"~datamart"といったようにデータ層ごとにデータセットを分けて運用しています。
また、テーブル名、ビュー名についてもconfigで定義しており、定義した名前でテーブルやビューが作成されます。
configで設定しない場合、ファイル名から拡張子を取り除いたものがテーブル名になります。
シャーディングテーブルの定義について
公式のリファレンスにはおそらく記述がなかった(見落としていたらすみません)のですが、シャーディングテーブルの定義については以下のようにワイルドカードを使用して書くことができました。
config {
type: "declaration",
name: "promotion2022*",
description: "2022年のプロモーション"
}
ソースデータを使用する際も以下のようにサフィックスを利用して記述することができます。
config {
type: "table",
name: "promotion_list",
description: "2022/01/01から2022/07/22までのプロモーションリスト",
}
SELECT
promotion_id,
promotion_name,
FROM
${ref("promotion2022*")} AS promotion
WHERE
promotion._TABLE_SUFFIX BETWEEN '0101' AND '0722'
シャーディングテーブルをデータソースとして利用することが度々あったのでこの記述方法は重宝しました。
最後に
今回Dataformを導入してみて、想定よりも導入コストが低く、簡単にデータパイプラインを整備することができました。
チームメンバーからも評判が良く、Dataform導入を契機にデータ分析基盤の改善や分析活動が活発になってきているので良かったと思います。
他プロジェクトでも利用され始めているので、会社全体で知見を溜めつつ改善できると良いなと思っています。