こんにちは!広告事業本部でアプリケーションエンジニアをしている中村です!!
全然関係ないですが、サウナで整った後が一番集中してコードを書けますよね!! 弊社のグループが運営しているオールドルーキーサウナはその中でもTop of 整うのでサウナ好きエンジニアは是非一度足を運んでみてください!
前振りはこんなもので今回は、ログ収集・検索にコストをかけずに効率化できる方法についてお話しします! 特に、DuckDBを使ってどのようにログを可視化するかに焦点を当てます。
読者ターゲット
- ログ収集・検索の環境に困っている方
- コストをかけずにログ収集・検索を行いたい方
- DuckDB UI の利用例を知りたい方
背景
私たちのチームで開発しているシステムは、ウェブサーバーやジョブサーバーからログを専用のログサーバーに転送し、さらにそれをS3に保管するという構成をとっています。
以下が簡単な構成図です。
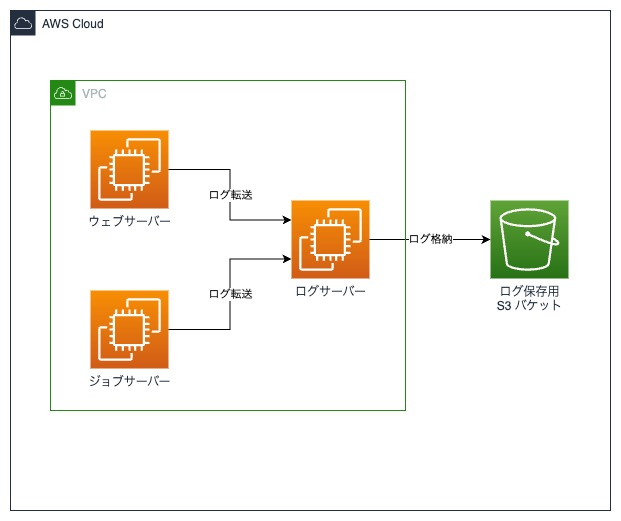
ログサーバーは、利用者から問い合わせがあるときや障害が発生した時の調査に利用しています。
現状、サーバーにSSHで接続し、grepやjqを使ってログを絞り込んでいますが、調査の頻度が低くても、手間がかかるのが現実です。ログの検索がしやすくなるツールとして、AthenaやCloudwatch Logs Insights、Datadog Logsなどのサービスもありますが、コストの問題があります。そこで、話題のDuckDBの使い勝手を調査してみることにしました。
DuckDBについて
DuckDBとは何か?
DuckDBは、高速なOLAP(オンライン分析処理)を可能にするシステムです。オープンソースで無料で利用でき、通常のSQLクエリを用いて大規模なデータを解析するのに適しています。DuckDBの強みは、そのシンプルなインターフェースと高性能なクエリエンジンにあります。サポートしているフォーマットには、CSV、Parquet、JSONなどがあります。
DuckDBを使ったログデータの確認までの流れ
以下に、DuckDBをインストールしてローカルでログをテーブル化して調査するための簡単なデモをご紹介します。 実際の調査ではAPIログを確認することが多いので、サンプルのAPIログを元にデモをしていきたいと思います。
DuckDBのインストール
まずは、DuckDBのインストール方法について説明します。各自の環境によりインストール手順が異なる場合がありますので、詳細はDuckDB Installationを参考にしてください。 以下に簡単なインストールコマンドを示します。
curl https://install.duckdb.org | sh
DuckDBの起動、サンプルのログファイルを読み込んでテーブル化
次に、DuckDBを起動しログファイルをテーブル化します。ここではインメモリでDuckDBを起動します。
$ duckdb > CREATE TABLE examples AS SELECT * FROM read_json_auto('sample.log');
sample.logファイルの中身は以下の通りです。
sample.log
{
"id": "sample_id_12345",
"started": "2025-05-01 08:02:44 +0000",
"payload": {
"request": {
"method": "PUT",
"path": "/11/accounts/sample_account/line_items",
"body": {
"id": "sample_line_item",
"name": "Sample LineItem Name"
}
},
"response": {
"code": "200",
"data": {
"id": "sample_line_item",
"name": "Sample LineItem Name"
}
}
}
}
{
"id": "sample_id_12346",
"started": "2025-05-01 08:02:44 +0000",
"payload": {
"request": {
"method": "PUT",
"path": "/11/accounts/sample_account/line_items",
"body": {
"id": "sample_line_item_2",
"name": "Sample LineItem Name 2"
}
},
"response": {
"code": "200",
"data": {
"id": "sample_line_item_2",
"name": "Sample LineItem Name 2"
}
}
}
}
データの確認
次に、作成したテーブルの中身を確認します。
> SELECT * FROM examples; ┌─────────────────┬──────────────────────┬─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐ │ id │ started │ payload │ │ varchar │ varchar │ struct(request struct("method" varchar, path varchar, body struct(id varchar, "name" varchar)), response struct(code varchar, "data" struct(id varchar, "name" varchar))) │ ├─────────────────┼──────────────────────┼─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤ │ sample_id_12345 │ 2025-05-01 08:02:4… │ {'request': {'method': PUT, 'path': /11/accounts/sample_account/line_items, 'body': {'id': sample_line_item, 'name': Sample LineItem Name}}, 'response': {'code': 200, 'data': {'id': sample_line_item, 'name': Sample LineItem N… │ │ sample_id_12346 │ 2025-05-01 08:02:4… │ {'request': {'method': PUT, 'path': /11/accounts/sample_account/line_items, 'body': {'id': sample_line_item_2, 'name': Sample LineItem Name 2}}, 'response': {'code': 200, 'data': {'id': sample_line_item_2, 'name': Sample Line… │ └─────────────────┴──────────────────────┴─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
上記のように、明示的にカラムを指定しなくてもスキーマを自動で推測してカラム化してくれますが、ネストされたキーをカラムとして推測してくれないため、必要であれば明示的に指定してください。 APIログの調査では、リクエストメソッドやリクエストパスで絞ることが多いので、これらをカラム化します。
$ duckdb > CREATE TABLE examples AS SELECT *, payload->'request'->>'method' as request_method, payload->'request'->>'path' as request_path FROM read_json_auto('sample.log'); ┌─────────────────┬──────────────────────┬───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┬────────────────┬────────────────────────────────────────┐ │ id │ started │ payload │ request_method │ request_path │ │ varchar │ varchar │ struct(request struct("method" varchar, path varchar, body struct(id varchar, "name" varchar)), response struct(code varchar, "data" struct(id varchar, "name" varchar))) │ varchar │ varchar │ ├─────────────────┼──────────────────────┼───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┼────────────────┼────────────────────────────────────────┤ │ sample_id_12345 │ 2025-05-01 08:02:4… │ {'request': {'method': PUT, 'path': /11/accounts/sample_account/line_items, 'body': {'id': sample_line_item, 'name': Sample LineItem Name}}, 'response': {'code': 200, … │ PUT │ /11/accounts/sample_account/line_items │ │ sample_id_12346 │ 2025-05-01 08:02:4… │ {'request': {'method': PUT, 'path': /11/accounts/sample_account/line_items, 'body': {'id': sample_line_item_2, 'name': Sample LineItem Name 2}}, 'response': {'code': 2… │ PUT │ /11/accounts/sample_account/line_items │ └─────────────────┴──────────────────────┴───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┴────────────────┴────────────────────────────────────────┘
以上がログファイルをDuckDBを用いてテーブル化し、確認するまでの簡単な流れです。
これだけでも十分に強力な武器になり得るのですが、データ量が多くなると、レコードが省略されてしまったり、視覚的に見づらい部分もあります。
DuckDB UIを使ったデータの可視化
そこで、DuckDB v1.2.1以降で導入された「DuckDB UI」を活用することで、データの可視性がさらに向上します。
起動は、-ui引数を指定してあげるだけです。
詳細が気になる方はDuckDB ローカルUIでチェックしてみてください。
$ duckdb -ui
起動したUIを通して、以下イメージのようにデータの確認ができます。
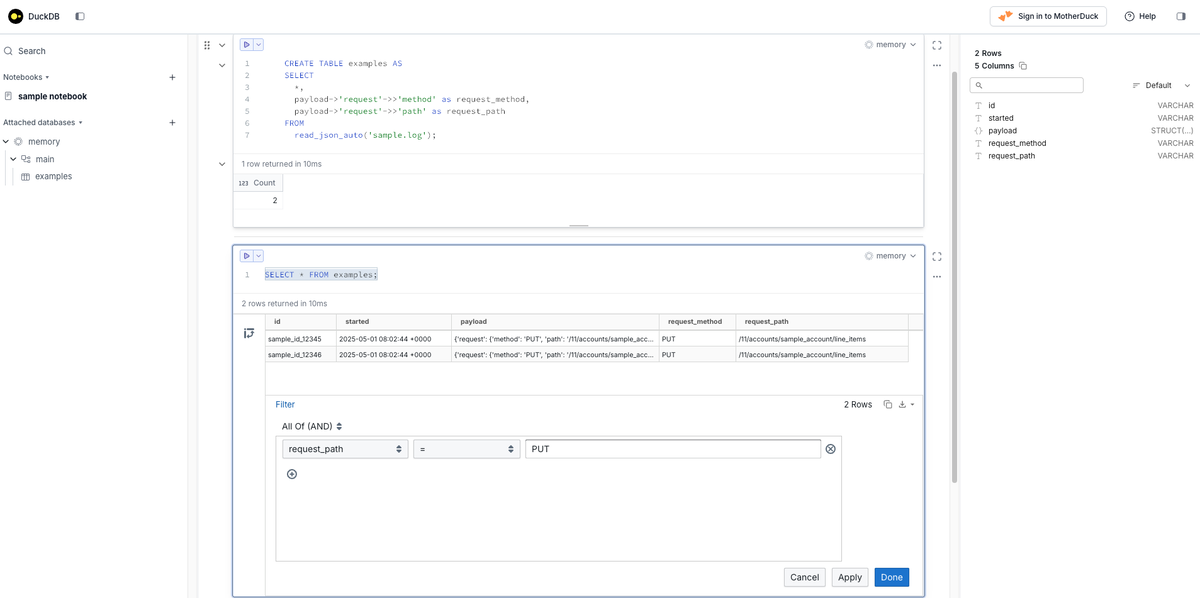
このように、DuckDB UIを使うことで、絞り込みを直感的にできたり、クエリが保存できたりと、便利なことがたくさんあります。
運用で利用するスクリプトの実装
ここまでは、DuckDBを用いたデータ確認の簡単なデモを行いました。しかし、これを実務で運用する際には、以下の手作業が必要になります。
- 取得したいログファイルを指定する
- ログファイルをリモートサーバーから取得する
- ログファイルを適切なスキーマでテーブル化する
これらの作業を毎回手動で行うのは負担が大きいため、可能な限り自動化したいと考えています。
ただし、まずはメンバーに迅速に利用してもらうことが重要だと判断し、簡単に実装可能なBashスクリプトを作成することにしました。
以下にそのスクリプトの概要を示します。このスクリプトでは、指定した日付のログをSSH経由で取得し、DuckDBでテーブル化してからUIを起動するという一連の流れを自動化しています。
#!/bin/bash
# ディレクトリとファイルの設定
LOCAL_LOG_PATH="/path/to/logs"
DUCKDB_FILE_PATH="/path/to/duckdb_file.duckdb"
REMOTE_SERVER="example.server.com"
REMOTE_PATH="/var/log/example"
# ログの取得とテーブル作成スクリプト
echo "ログを取得し、DuckDBにテーブルを作成します。"
# 日付を入力
echo "取得したい日付をカンマ区切りで入力してください(例: 0,1,2,3):"
read input
# 日付の配列に変換
IFS=',' read -r -a days_array <<<"$input"
# ログファイルの取得
mkdir -p ${LOCAL_LOG_PATH}
for date in "${days_array[@]}"; do
scp user@${REMOTE_SERVER}:${REMOTE_PATH}/log-${date}.log.gz ${LOCAL_LOG_PATH}/
done
# DuckDBでテーブルを作成
duckdb ${DUCKDB_FILE_PATH} <<EOF
CREATE TABLE logs AS
SELECT * FROM read_json_auto('${LOCAL_LOG_PATH}/log-*.log.gz');
EOF
# UI起動
duckdb -ui ${DUCKDB_FILE_PATH}
現状の課題
上記のスクリプトを利用してもらい、チームメンバーからのフィードバックを受けていくつかの課題が浮き彫りになりました。
それらの内容を整理し、今後の改善点として以下に挙げます。
処理時間の問題 スクリプトの実行からUIが起動するまでに時間がかかるため、メンバーが待機時間を避けて直接サーバーを確認してしまうケースが発生しています。
絞り込みの制約 特定のキーでログを絞り込みたい場合に、スキーマの自動推測によってカラムが設定されず、WHERE句でのフィルタリングが困難になることがあります。
さらに、自分自身でも以下のような課題を感じています。
スクリプトの肥大化と管理の難しさ ログの種類が増えるごとにスクリプトのコード量が増加し、管理が難しくなっています。
テーブル化するログの選択ができない 現在、APIログの特性に応じて複数のテーブルを作成していますが、調査に不要なテーブルまで生成されてしまい、効率が悪化しています。
これらの課題に対処することで、ログの処理をより効率化し、チーム全体の作業がより円滑に進むことを目指しています。 メンバーがログを確認できる環境を整えることができたため、大きな一歩を踏みだせました。これを基盤として、さらなる改善を進めていきたいと思います。
これからやりたいこと
これまでの取り組みを踏まえ、次に実現したいことを以下にまとめました。より効率的で使いやすいログ収集・検索環境を目指して、以下の点を改善していきます。
処理速度の改善
ログファイルの取得プロセスを非同期処理に変更し、全体の処理速度を向上させます。
絞り込みの制約の解消
データフィルタリングが可能になります。
スクリプトの肥大化と管理の難しさの解消
現在のスクリプトは規模が大きくなり、管理が複雑になっています。この問題を解決するために、Rubyを用いてコードを整理し、ファイル取得やテーブル作成などの機能をクラスごとに分割します。また、これをRakeタスクとして実行できるようにすることで、管理と実行の効率を高めます。
テーブル化するログを柔軟に選択できるようにする
コマンドライン引数やRakeタスクの引数を用いて日付や対象のログを指定し、柔軟にテーブルを準備することも可能です。
ただし、条件が増えると引数が複雑になり、運用が難しくなる可能性があります。そのため、ログの種類ごとにスクリプトを分け、必要に応じてそのスクリプトを実行してもらう方法も検討中です。この場合、DuckDB UIの起動はスクリプト実行後に手動で行ってもらうことを想定しています。
さらに、将来的な展望として、日付指定やその他の条件をより直感的に設定できるインターフェースの導入も考えています。
具体的には、Slackアプリを活用してモーダルインタラクションを実装し、メンバーが直感的に日付や対象のログを選択できる仕組みを構築することを考えています。ユーザーが選択を行った後は、AWS Lambdaを利用してバックエンドの処理を自動化し、最終的にローカル環境で簡単に利用できるデータを提供するフローを検討中です。
これらの改善により、ログの可視化と分析のプロセスをさらに洗練し、チーム全体の業務効率を向上させることを目指します。
最後に
今回は、ログの可視化方法としてDuckDBを活用するアイデアを紹介しました。現在の手法が最適解ではないことは理解していますが、チームメンバーがより簡単にログを確認できる環境を提供するために、試行錯誤を続けています。最終的には、S3から直接テーブルを作成する仕組みを整え、ログサーバーを廃止することで、さらなるコスト削減を実現したいと考えています。
この記事が、皆さんのログ管理における新しい選択肢の一つとなれば幸いです。今後も引き続き改善を重ねながら、より良いシステムを構築していきます。ご覧いただき、ありがとうございました。