こんにちは!こんばんは!ほったです(`・ω・´)ゞ
今回はエラーバジェットポリシーの作成と仮運用をしてみたので
実際の具体例も踏まえて説明していこうと思います!
過去のSLI/SLO策定に関連する記事はこちら
エラーバジェットポリシーについて「サイトリライアビリティワークブック」では
以下のように書かれています。
サービスがバジェットを使い果たしてしまった時に行うことをおおまかに定めたポリシー
<出典:Betsy Beyer、Niall Richard Murphy、David K. Rensin、Kent Kawahara、Stephen Thorne 編、澤田 武男、関根 達夫、細川 一茂、矢吹 大輔 監訳、玉川 竜司 訳 「サイトリライアビリティワークブック」 p29>
背景
SLI/SLOの策定を進めていたものの、実際にバジェットを使い果たした時に
どういうアクションを取れば良いのかが明確になっていませんでした。
エンジニアだけでなくPdM、セールスも含めてフローを具体的に示し、
スムーズに対応に当たれるようにしておきたいと考え、エラーバジェットポリシーを作成することにしました。
取り組んだこと
ではここからは具体的に実際に作成したエラーバジェットポリシーについて説明していきます!
エラーバジェット50%消費のアラートが飛んできた場合
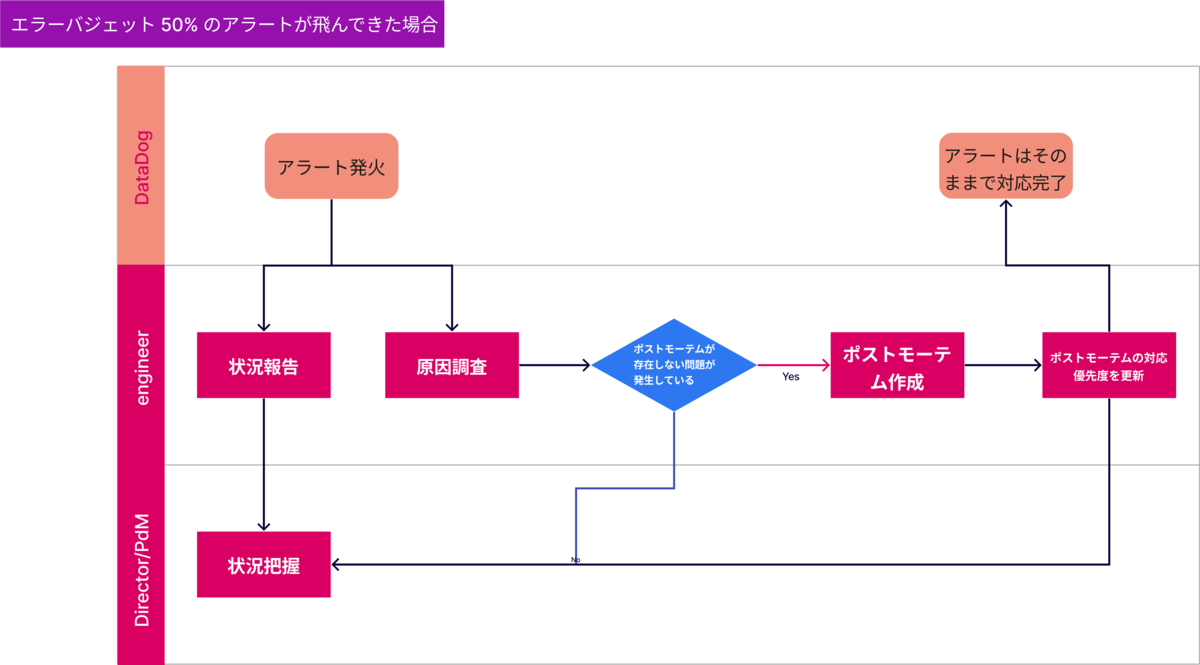
ここでポストモーテムという言葉が出てきていますが、ポストモーテムは以下のようなドキュメントです。
ポストモーテムは、インシデントとそのインパクト、その緩和や解消のために行われたアクション、根本原因(群)、インシデントの再発を避けるためのフォローアップのアクションを記録するために書かれるものです。
<出典:Betsy Beyer, Chris Jones, Jennifer Petoff, Niall Richard Murphy 編、澤田 武男、関根 達夫、細川 一茂、矢吹 大輔 監訳、Sky株式会社 玉川 竜司 訳 「SRE サイトリライアビリティエンジニアリング」 p175>
エラーバジェット超過が発生した際に、エラーバジェットの消費を食い止める対応をしますが
調査して対応するまでの間もバジェットは消費しつづけてしまいます。
できるだけバジェット消費の時間を少なくするために、エラーバジェットが50%消費された時点で
事前に暫定対応が実施できる程度の調査を進めておくようにしています。
エラーバジェット超過

ある程度パターンを想定してフローを考えるようにしました。
パターン例)
- 50%消費時点でバジェットを消費していた問題と、超過時点で大きくバジェット消費している問題が違う
- 短期間でエラーバジェットが枯渇し、ポストモーテムが書かれていない
また、セールスへの連絡や判断はPdMに任せて、
エンジニアは調査やエラーバジェットの消費を食い止める作業に集中できるように役割を明確にしています。
ポストモーテムによってSLOを守っていく上で障害となる要因が明らかになった
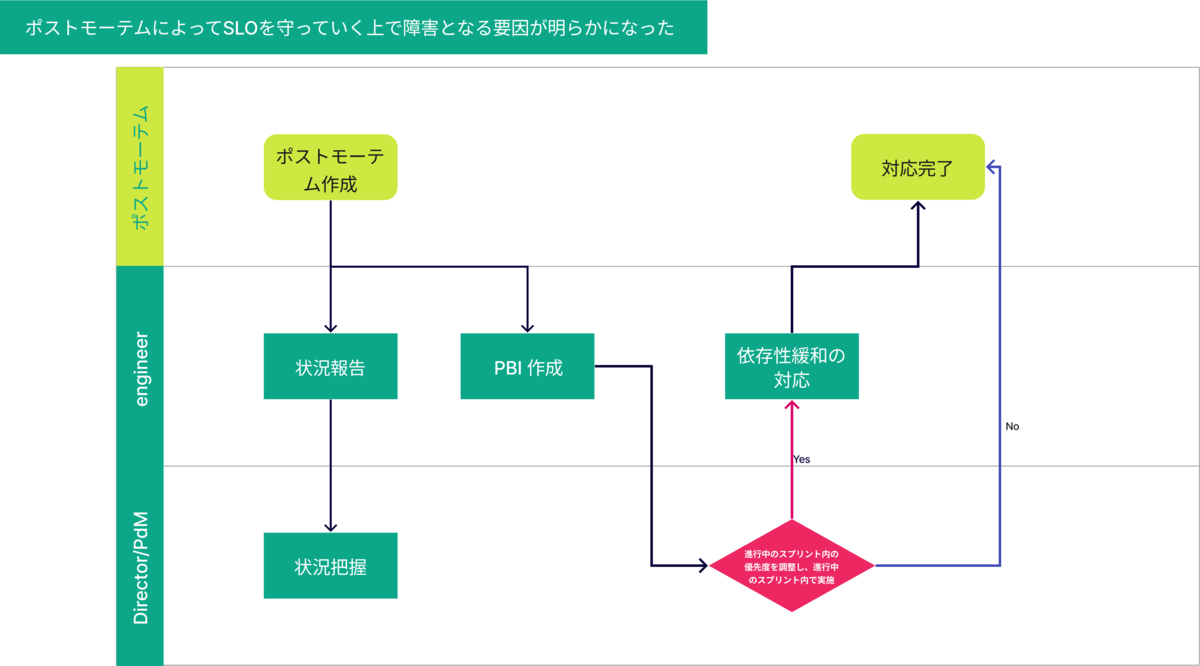
SLOを守っていく上で障害となる要因とは以下のようなものを想定しています。
- SPOFでシステムの可用性に問題があること
- 他のサービスのSLOと運用しているサービスのSLOに矛盾が生じていること
- 例)Aサービスを利用するBサービスのSLOが、AサービスのSLOよりも高い
エラーバジェットポリシーを運用しているサービスは、サービスが開始してから10年以上経っており
技術的負債が少ないとは言えない状況です。
ポストモーテムを書いている時に、今後障害につながる可能性のある問題が見つかることもあります。
なのでディレクターやPdMに報告し、いつ対応するか他のタスクとの優先度を検討できるようにしています。
またここでPBIやスプリントという言葉が出てきますが、
該当サービスはスクラムを採用しているので、スクラムの用語が出てきています。
エラーバジェットをきちんと消費しなかった
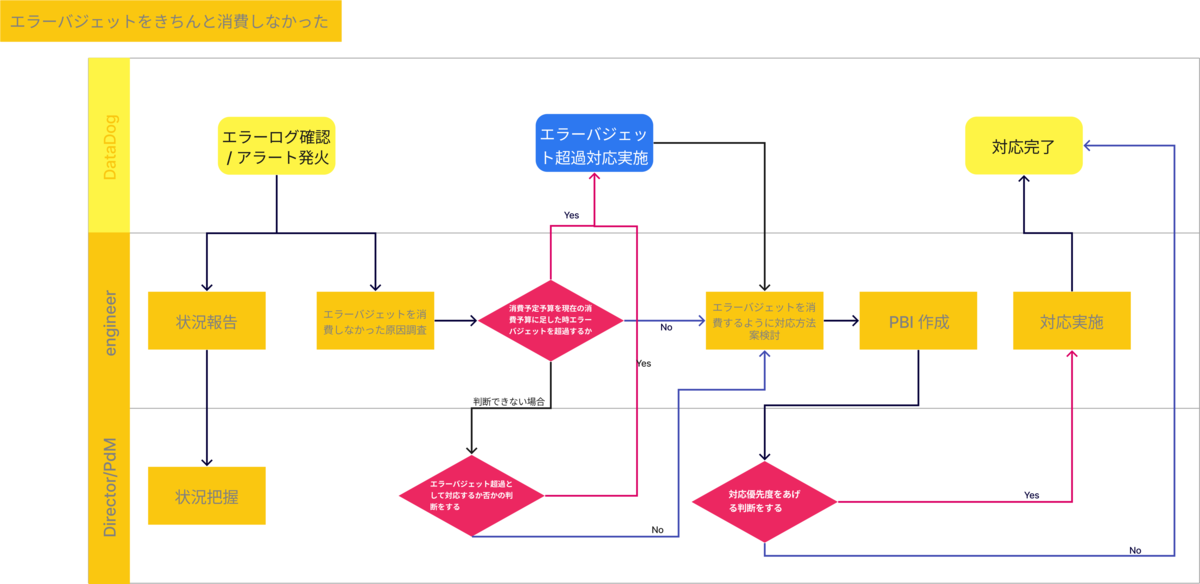
策定したSLIが間違っていた時に、本来であれば消費する必要のあったバジェットが
消費されない可能性があると考え、こちらのフローも策定しました。
いまのところ、このフローに則った対応をする機会がなかったため、うまく対応できるかはわかりませんが
方針として明確にしておきたかったので、フローを作成しています。
リリース時に障害が発生した
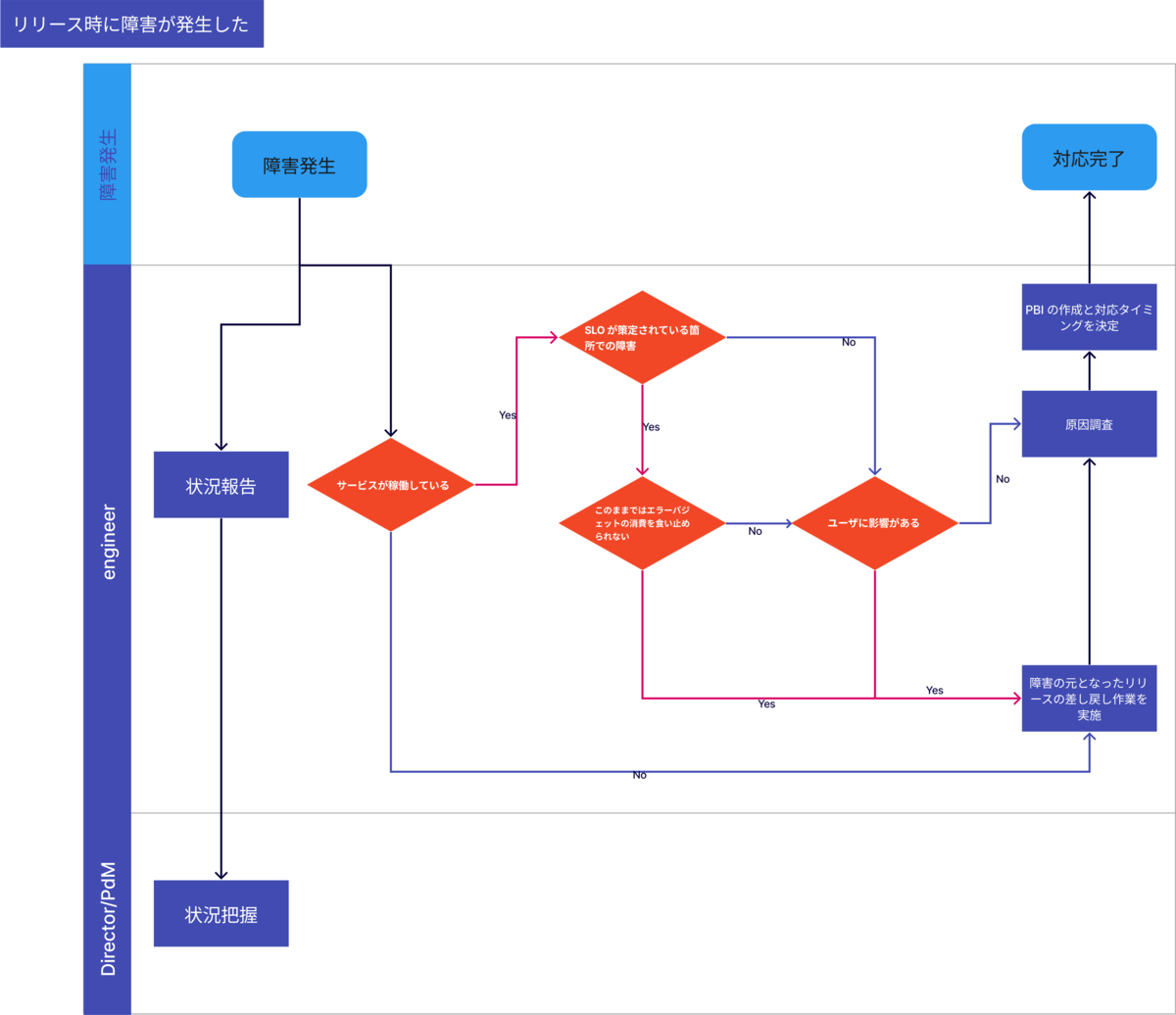
全ての機能にSLOが定められているわけではないことと、ユーザの関わる箇所全てに対して
適切にSLOを定められていない可能性を考慮してロールバック基準を定めました。
従来から運用している障害対応時のフローに、SLOの概念が追加された感じになりました。
よかったこと
実際にエラーバジェットポリシーを作成・運用してみて、
SLOの設定が求められる信頼性よりも高い状態になっていたことがわかりました。
SLOの数値見直しに繋がり、エンジニアが必要以上の信頼性回復に力を入れる必要が減り、
新規価値と向き合う時間ができました。
また、エラーバジェットポリシーを運用していく過程で、ポストモーテムのテンプレート作成もしました。
今はテクニカルマネージャー、テックリード層で月1回ポストモーテム共有会を実施しています。
サービスは違っても扱っている技術が似ているので、他のサービスで同じような問題が発生しないか、
ポストモーテム内のアクションについて別の視点でアイディアはないかなど、有意義な議論ができています。
今後について
今回ご紹介したポリシーの運用自体はまだ仮段階で、
サービスに関わるテクニカルマネージャー、テックリード間で進めているものになります。
今後はサービスに関わる全てのエンジニアがポリシーに従って対応できるように
チームに展開していきつつ、必要に応じて変化させていきたいと考えています。
個人的には、うまく運用できそうなら他サービスにもアプローチして組織として
障害フローを統一していきたいなと思っています。