お久しぶりです!!!
データエンジニアの大窄 直樹 (おおさこ)です.
今年も始まったかと思いきや,
もう年末で驚いています.
年齢を重ねるにつれ, 光陰矢の如く1年が過ぎ去っていきますね(笑)
それでは, 本題に入ろうと思います.
今回は, 自社のデータ分析基盤作成システムにSLOを導入し,
運用することでシステムの信頼性を向上できた話をしようと思います.
(SLOは, 本来のものを少々独自解釈している部分があります)
SLOの導入に至る背景
ある日, PO(Product Owner)とSE(System Enginner)の日常会話です.
- PO: 最近障害多いような気がする??? なんか良い感じに品質上げれない???
- SE: 確かに, 最近いろいろ起きてますね. 直近起きてた障害は解決できましたけど..
- PO: (障害記録を見ながら) この障害前々から定期的に起きてるけど解決できてるの??
- SE: 確かに.... まだ解決できてないです....
- PO: 障害を良い感じに可視化して, 良い感じにシステムの信頼性上げる方法ない???
- PO, SE: (調査) SLOっていうのを用いたら良い感じに信頼性上げれそう!!
- PO: SLOを導入すると, 上手くいけばシステムの信頼性を上げれそう!!
- SE: SLOを用いてうまく運用出来るとシステムの信頼性を上げれそう!!
SLOの導入を決意!!
SLOとは??
SLO(Service Level Objective)とは, サービスの信頼性目標レベルのことです. これを導入し運用することで, データドリブンの開発, 改善の意思決定をチームが行えるようになります.
類似したものものに, SLA (Service Level Agreement)が存在し, こちらはユーザーとの契約に用います.
一般にSLOより緩い数値目標を設定し, 設定した数値を下回ると契約に則ったペナルティが課せられます.
また, SLO, SLAの指標をSLI(Service Level Indicator)と言います.
Amazon EC2の場合 は下記のようになります.
- SLIは月間稼働率
- SLAは99.5%で, 99.5%を下回ると使用量の10%が返金, 99.0%を下回ると30%の返金, 95%を下回ると100%の返金
- SLOは自社内での目標数値のため外部には非公開
ここではSLOについて詳しい話は割愛するので, 詳細を知りたい方はこちらのリンクをご覧ください.
データ分析基盤作成システム
今回システムの信頼性を向上させたいシステムは, データ分析基盤作成システムです.
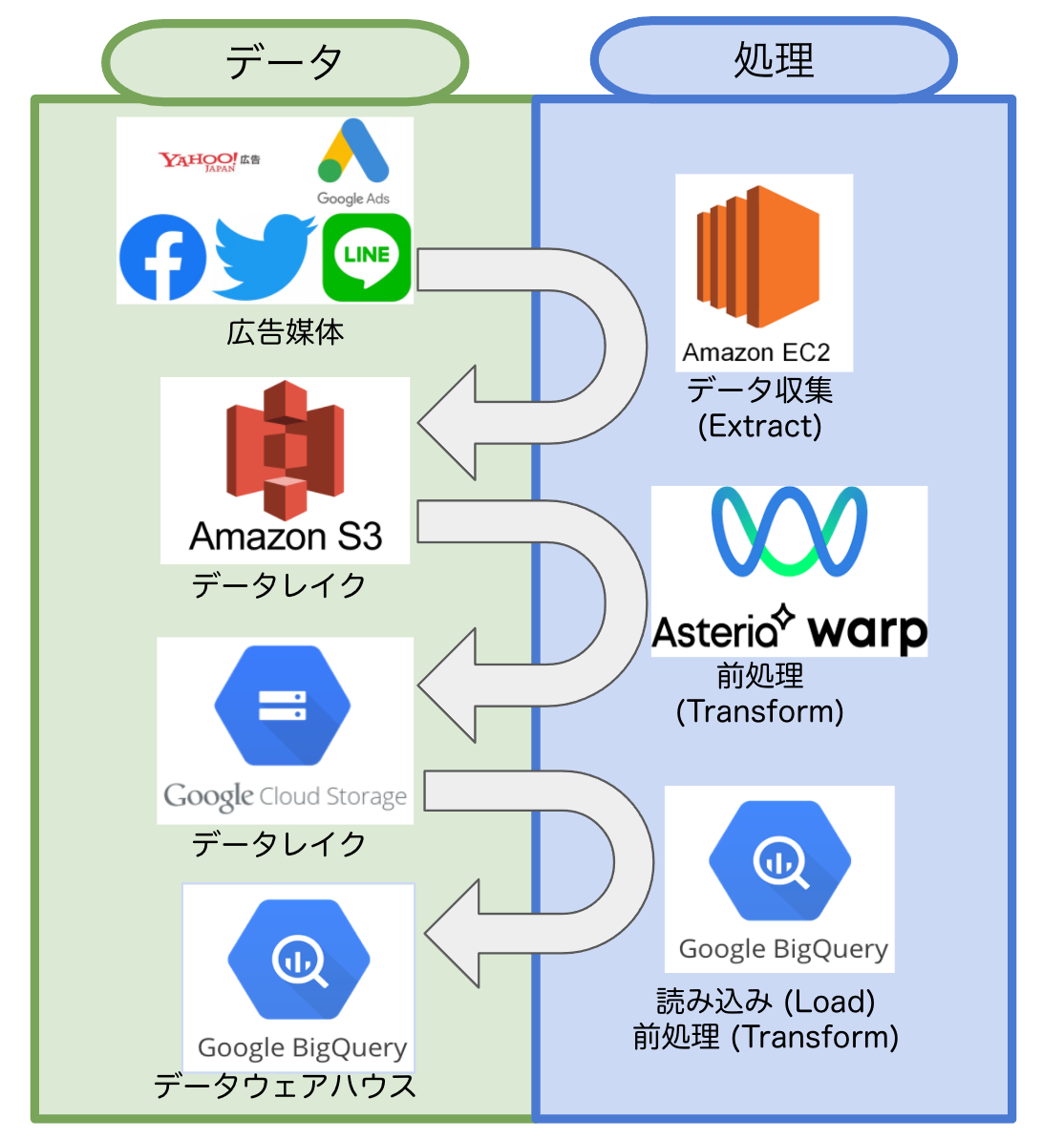
このシステムは, ETLT(Extract Transform Load Transform)を行うシステムで下記のような処理を毎朝行っています.
- 複数の広告媒体データを, EC2を用いてデータ収集しS3に格納 (Extract)
- S3の取得したデータを, Asteria warpを用いて扱いやすいように前処理しGCSに格納 (Transform)
- GCSのデータを, BQに読み込み(Load)
- BQのデータを, さらに扱いやすいように前処理しDWHをBQに作成 (Transform)
SLOの導入に苦戦
SLO自体は非常にシンプルなものなのですが, 実際に導入しようとすると悩ましいことが多かったです.
今回導入対象のデータ分析基盤システムを含め,
ほとんどのシステムは何らかの自分たちのコントロール外のシステムと密接な関係にあります.
例えば, 他社のAPIを利用していたり, AWS, GCPをいったクラウドサービスを利用していたりなどです.
その場合, 他社のAPIで障害が起きたら利用しているシステムも障害になりますし, サーバーにEC2を利用していてEC2に障害が発生してもシステム障害になります.
つまり, 自分たちの作成したサービスに何も問題がなくても障害は発生します.
私の保守するデータ分析基盤作成システムでもまた同様で, 広告媒体, AWS, GCPなどで障害が発生した場合私のシステムもまた障害が発生します.
そうなると, 図のようにシステムの可用性とは何??, どうすれば私たちの改善したい障害だけピックアップできるの?? という疑問を抱きました.
この時の私の頭の中を下記図に示します.

- 利用しているシステムが多ければ多いほど可用性は下がる???
- 前工程の可用性が90%の場合, 後ろの工程は90%以下になる??
この時, 私は迷走していました...
私は上図のシステム全体の可用性を上げようとしているが,
目的は自分のコントロールの範囲内の可用性をあげたい.
データ分析基盤作成システムをデータドリブンに可用性をあげたい!!!!
この時になってやっと気付きました,
データドリブンに可用性を上げるためには,
まず指標であるSLIを設定する必要がある, その次にそれを測定可能にするために障害記録の付け方を変更する必要があるということに.
SLOの導入
我に返った私は, まずSLIを設定しました.
SLIは, 媒体粒度での"(日数-自分たちのコントロール範囲内の障害日数)/日数" としました.
つまり, SLIはデータ取得を行う媒体数分あります.
ここで, 媒体粒度にした理由は全て一括りという大きな粒度より媒体粒度という小さい粒度の方が扱いやすいからです.
また, 障害日数ではなく自分たちのコントロール範囲内の障害日数としたのは, 改善可能な数値を指標にしたかったからです.
SLOはPOとの取り決めで90%としました.
また, SLIを測定可能にするために障害記録の付け方を変更しました.
今までも, 障害が起きたらその内容を, スプレッドシートにまとめていましたが, それを形式化し必要な情報を改めて考え直しました.
その結果, 障害記録に必要な項目は下記でした.
障害による影響のある媒体, 障害発生起因の2つを追加することで, 自分たちのコントロールの範囲内の障害を絞り込むことができます.
- 障害, インシデント
- 日付
- 発生時刻
- 復旧時刻
- 障害により影響のある媒体
- SLIを媒体粒度にしたため必要
- 障害発生起因 (媒体,データ取得, データ整形, オペレーション, その他)
- 自分たちが解消できる障害かどうか判断
- エラー理由
- 対応内容
- リカバリ状況
SLOの運用
SLOを導入したことにより, 自分たちのシステムの可用性が可視化できるようになりました.
下図はデータ分析基盤作成システムの可用性を可視化したものです.

重要視しているのはSLIですが, 一応SLIとは関係のないコントロール範囲外の障害回数も計測しています.
運用としては, 1月毎や1クォータ毎など適切なタイミングで, SLOを下回りそうではないか,
下回っていないかを確認し下回りそうなら全力で改善するといった運用をしています.
(聞いた話にSLOを下回ったら新規開発を止めて, 改善に全集中というのを聞いたことがあります)
また, このように数値化を行うことでどの障害が頻繁に起きているか明確になりシステムの信頼性を効率的に向上できるようになりました.
新規開発を優先するか, システム改善を優先するか悩んだ際にも, まだSLOには余裕があるので新規開発に専念しようといった判断も行いやすくなりました. つまり, SLOの値により新規開発の速度とシステム改善のバランスが取れるので非常に開発が行いやすくなりました.
SLOを導入当初は, 可視化することで様々な改善点が浮き彫りになり, SLIがSLOを下回ることが多々ありましたが
現在は落ち着いて当初に決めたSLOを下回ることは少ないです.
システムの平常運転満たせるようになったのでSLOの導入前と比べ可用性が向上し, 信頼性を向上させることができたんじゃないかなと思ってます!!
私たちのSLOの反省点??
SLOを, 自分たちが扱いやすいように独自解釈したために一般的なSLOと少々違うものになりました.
また, SLIに用いている変数の"コントロール範囲内の障害"を正確に把握できれば良いのですが,
実際はそうはいかず数週間後に把握できる場合が多いです.
そのため定期的に振り返らないと, 間違った内容が障害記録として残ってしまう傾向にありました.
最後に
少々独自解釈したSLOをデータ分析基盤作成システムに導入し
運用したら品質を向上させることができました!
今回SLO導入の学びとして, 大切だと思ったのは下記です.
- まずSLI, SLOを設定する.
- 次に, SLOを満たせるように改善する
- 最後に, SLOを満たせるように新規開発とシステム改善のバランスを考え運用する
です
自分たちのシステムの状況を正確に把握するためにSLOの導入を検討されてはいかがですか?