こんにちは、自社広告サービス担当の飛田です。
だいぶ暑くなってきましたね。いよいよ夏本番です。晴れ晴れしたコバルトブルーの夏空サイコー!!
とエモさ全開ですが、気を取り直して開発プロセスをデータドリブンで改善していく話をしたいと思います。4月から取り組み始めて3ヶ月程度ですが、何かお役に立てれば幸いです。
はじめに
私たちは開発プロセスにおけるパフォーマンスを定量化していないため、自分たちの開発パフォーマンスが分からないまま、ただただ先の見えない高みを目指している状態にあります。同僚の一人は「開発自体は遅くはないけど早いとも言い難い」となんとも歯切れの悪い表現をしていました。これには私も同意せざるを得ません。
そこで広大なネットの海に潜ること数分。私は4つのキーメトリクスと出会いました。
出会いのきっかけはshibayuさんの 開発チームのパフォーマンスを測る指標を学ぶ - 「LeanとDevOpsの科学」読んだ でした。
4つのキーメトリクスとは
「LeanとDevOpsの科学」で提唱された「リードタイム」「デプロイ頻度」「MTTR」「変更失敗率」のメトリクスです。これら4つのソフトウェアデリバリに関するメトリクスは、企業の業績に影響を及ぼしていることも調査研究の結果で明らかになっています。
リードタイム
一般的なリードタイムと定義が異なるため注意が必要です。狭義のリードタイムやサイクルタイムと言ったほうが分かりやすいかもしれません。定義はコミットから本番環境稼働までの所要時間です。4つのメトリクスの中で一番計測しやすいとされています。
私たちはできるだけ正確な時間を計測するため、開発着手時にマージリクエストを作成するルールを設けました。本番環境稼働はGitLabのCI/CDでデプロイJOBが成功した時間としました。
デプロイ頻度
本番環境への正常なデプロイの頻度です。私たちは当初デプロイ数と勘違いしていましたが、あくまで頻度です。私たちはGitLabのCI/CDでデプロイJOBの成功をデプロイと定義しました。
MTTR
本番環境で障害が発生してから回復するまでにかかる時間です。今回は注力しないため計測はしません。
変更失敗率
デプロイが原因で本番環境に障害が発生する割合(%)です。今回は注力しないため計測はしません。
また、これらのメトリクスはパフォーマンスごとにレベルの定義があります。
| エリート | ハイ パフォーマー |
ミディアム パフォーマー |
ロー パフォーマー |
|
|---|---|---|---|---|
| リードタイム | 1日未満 | 1日~1週間 | 1週間~1ヶ月 | 1ヶ月~6ヶ月 |
| デプロイ頻度 | オンデマンド (1日に複数回) |
1日~1週間に1回 | 1週間~1ヶ月に1回 | 1ヶ月~6ヶ月に1回 |
| MTTR | 1時間未満 | 1日未満 | 1日未満 | 1週間~1ヶ月 |
| 変更失敗率 | 0~15% | 0~15% | 0~15% | 46%~60% |
これら4つのメトリクスのうち、リードタイムとデプロイ頻度に注力することにしました。MTTRと変更失敗率は来期以降で取り組む予定です。
やったこと
では実施した取り組みを紹介していきます。
まずはじめに、リードタイム削減に向けて要件をまとめた関連図を作成しました。また、チーム内で認識の齟齬が少なくなるように成功/失敗などの抽象的な表現はできる限り避け、成功/失敗とはどのような状態なのか具体的に記述するように務めました。
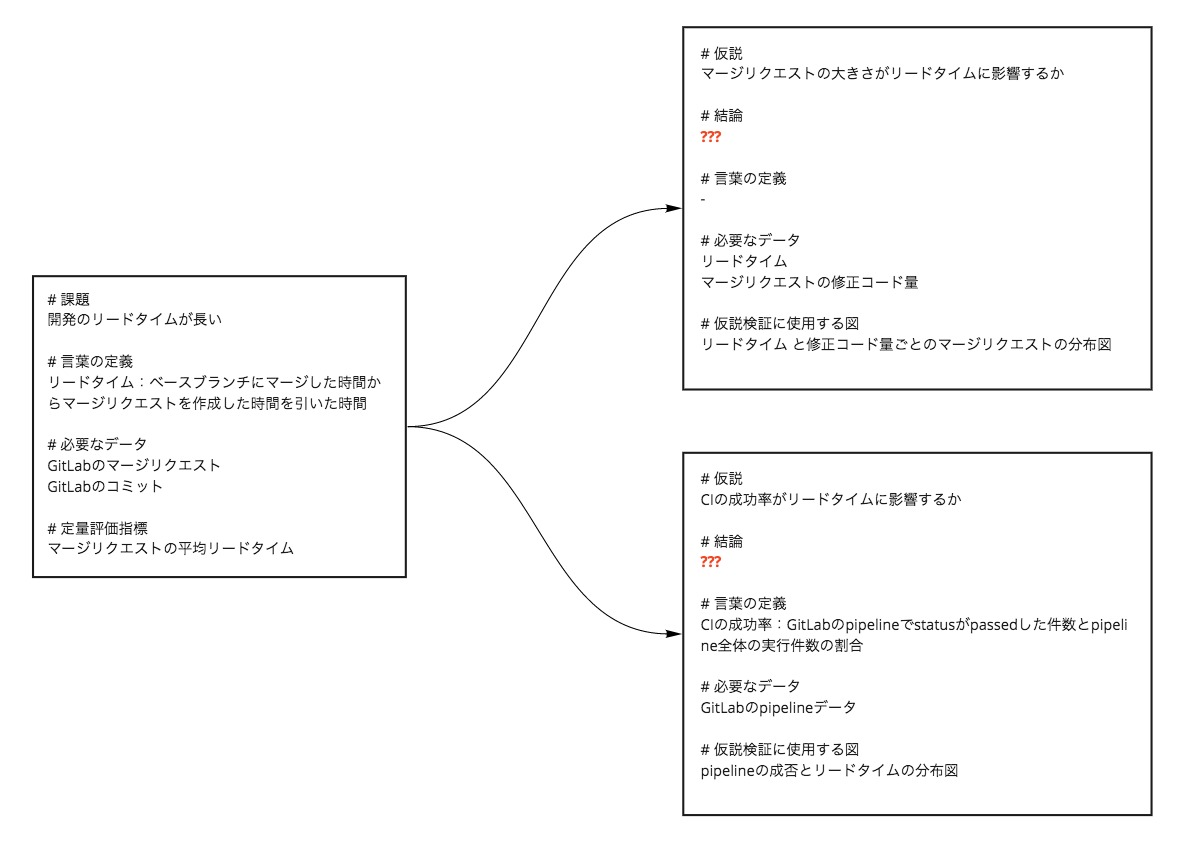
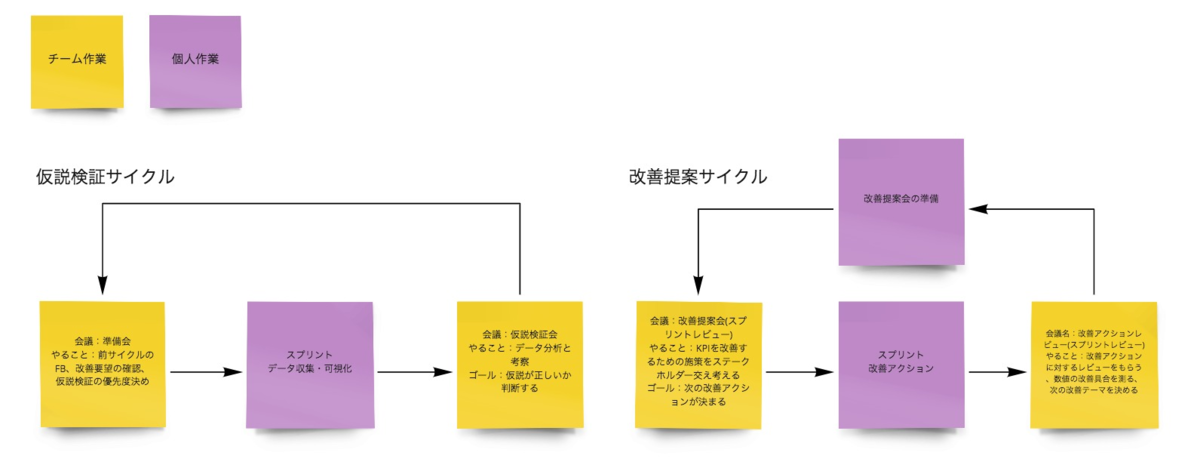
次に潜在的な課題を発見するための仮説検証サイクルを考えました。私たちのチームはスクラムを採用しているため、スクラムイベントのコンテンツ内容も一部変更しました。
また、自明になった課題に対する改善提案サイクルも作成しました。こちらは仮説検証とは観点が異なるため別サイクルとして切り出しています。
ここまでで要件や進め方が決まったので、ここからは実際にデータを取得していきます。
実装方法はGitLabのAPIを叩くスクリプトを定期的に実行しBigQueryにインサートしています。
詳しい内容は既に素晴らしいまとめ記事がありますのでそちらを参考にしてください。
- https://github.com/GoogleCloudPlatform/fourkeys
- Pull Requestから社内全チームの開発パフォーマンス指標を可視化し、開発チーム改善に活かそう
- Four Keys 〜自分たちの開発レベルを定量化してイケてる DevOps チームになろう〜
engineer.recruit-lifestyle.co.jp
必要なデータが揃ったらみんな大好きRedashを使って分析しやすいように可視化していきます。
Deploys/Day/Developer(1人当たり1日にデプロイした件数)の時系列
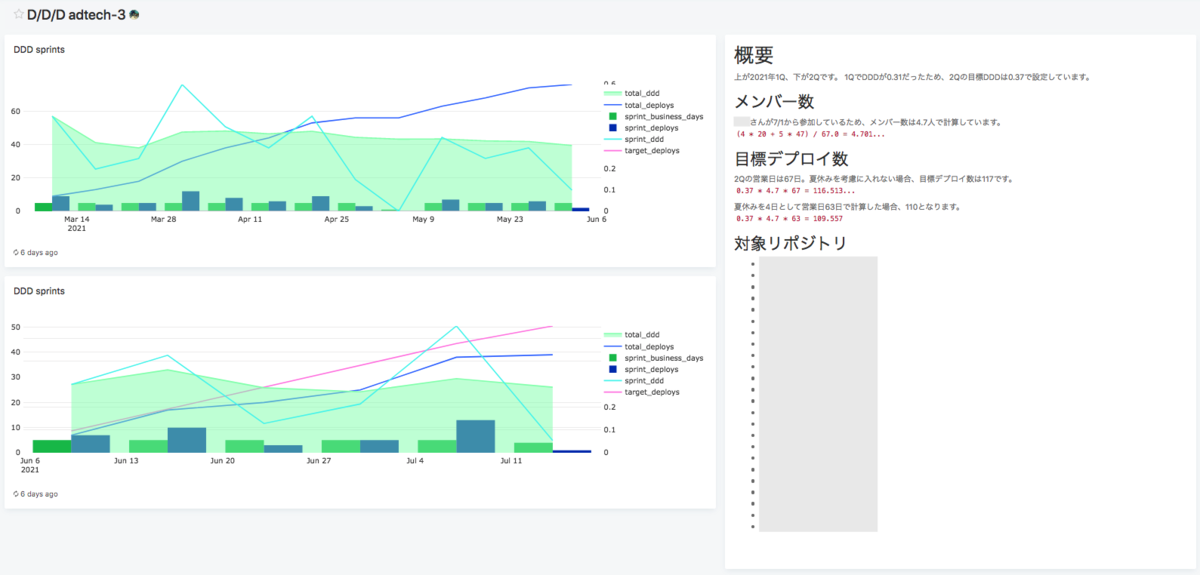 前期と比較して今期は20%UPを目指しています。
前期と比較して今期は20%UPを目指しています。
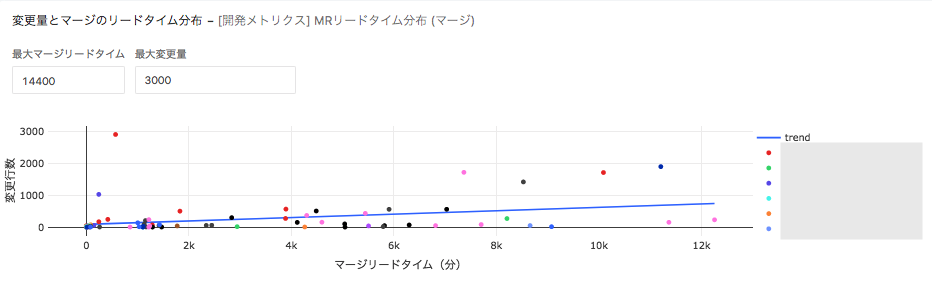
マージリクエストのコード修正量とリードタイムの分布
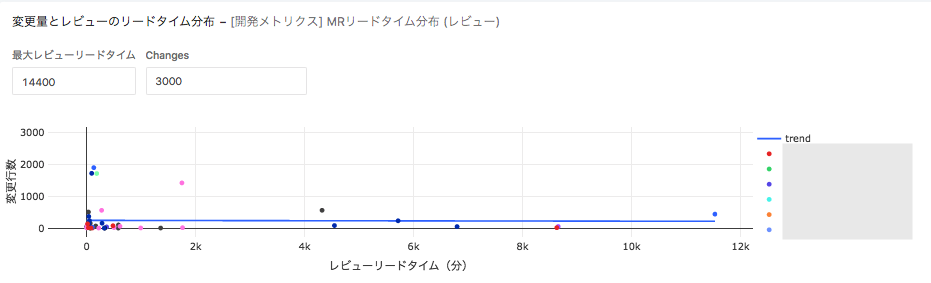
マージリクエストのコード修正量とレビューにかかった時間の分布
マージリクエストのコード修正量とコーディング時間の分布図
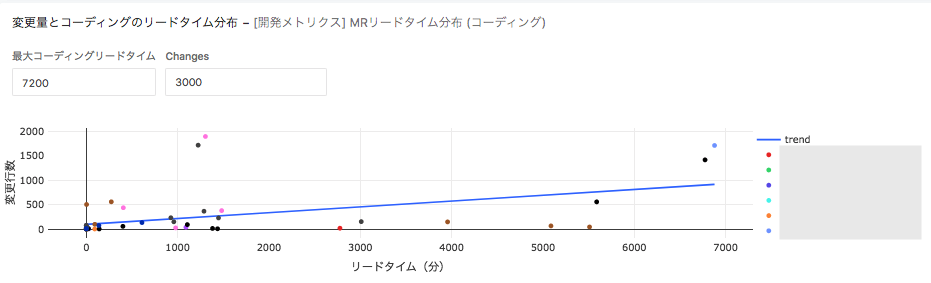
最後に分析です。図は「マージリクエストの大きさ(コード変更量)がリードタイムに影響するのか」を検証した結果になります。

以降はこのサイクルをよしなに回していきます。
わかったこと
計測するリポジトリが多く計測漏れがあった
私の所属するチームはシステムのアーキテクチャや足回りを整備する業務が多く、修正を施すリポジトリが多岐に渡るため、計測を広範囲で行う必要がありました。従って修正を施す必要のあるリポジトリはわかってる範囲ですべて計測できるように変更しました。
コード修正を伴わないタスクが計測から漏れていた
単発ではあるがコード修正が伴わない(デプロイの定義に当てはまらない)タスクがいくつかありました。現状は数も多くないので計測から外していますが、増えてくる場合は対応を考えないといけません。
データドリブンになっていない
データ収集と可視化はできているものの、その分析結果を起点とした意思決定までには至っていません。私たちはデータドリブンな習慣を身につける必要があるようです。
つぎにやること
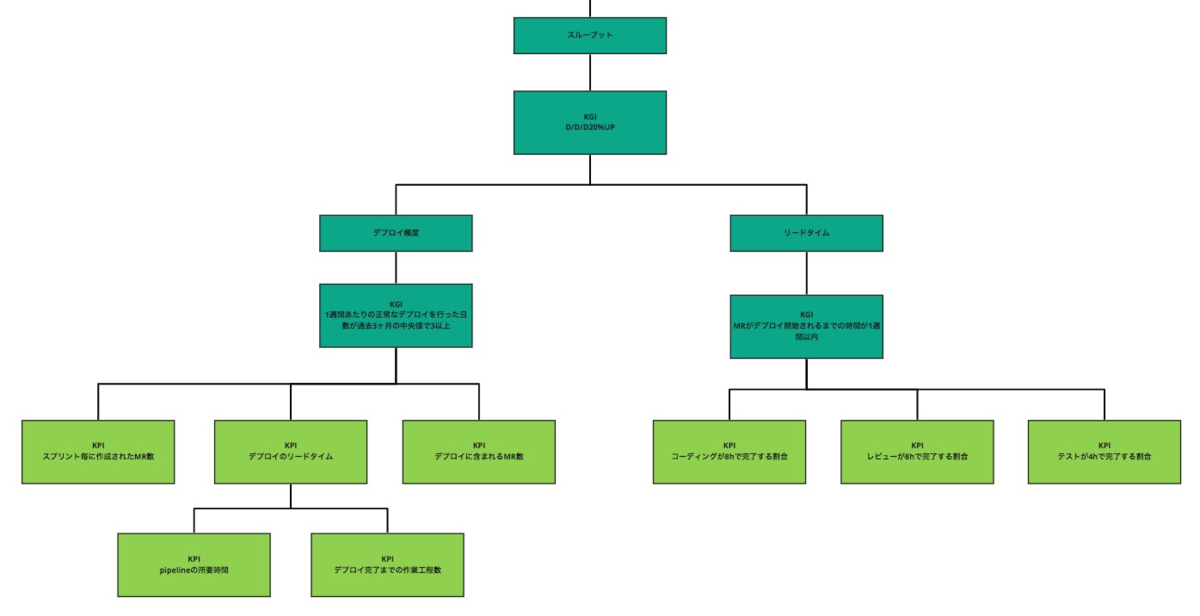
KPIツリー作成
現状の関連図ではプロセス改善がリードタイムに与えるインパクトを把握できておらず、適切な優先度で改善が進められていません。そこで「要件をまとめた関連図」をもとにKPIツリーを作成しています。まだ作成途中ですがだいぶ良い感触を得られました。順調に進めば8月から運用が始められる見込みです。
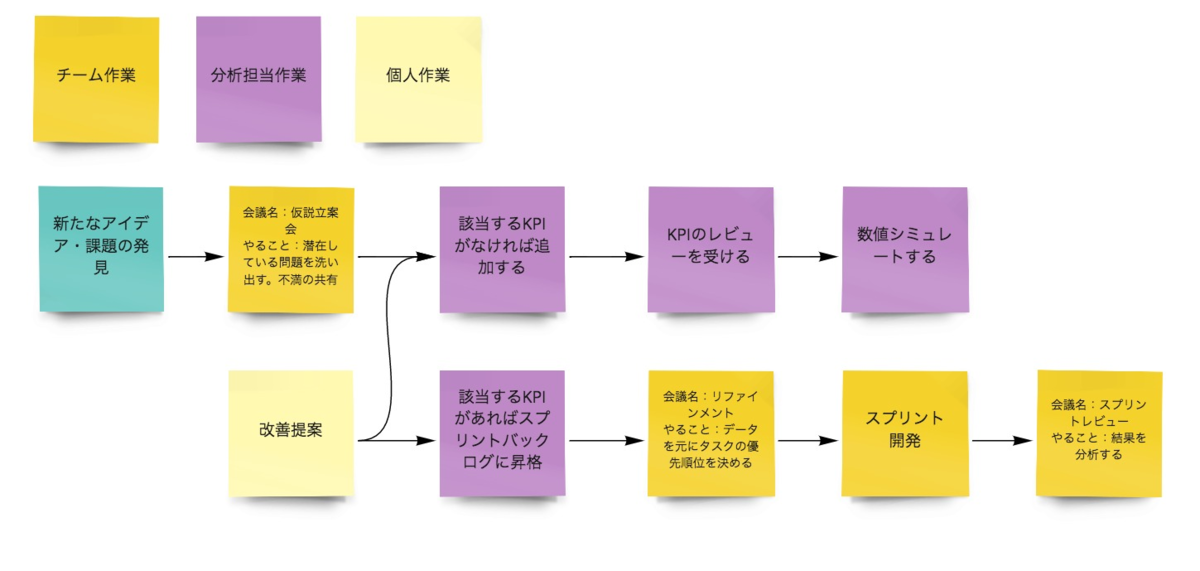
業務フローの見直し
データドリブンな習慣を身につけるため、リファインメントやプランニングでの意思決定に分析結果を使うようフローを見直します。また、KPIツリーの運用に伴って「KPIのレビュー実施」や具体的な数値を当て込んだ「数値のシミュレート」をフローに追加しました。特に数値シミュレートは重要で「〇〇が増えるとXXも増えるけど、これは私たちが求めていることだっけ?」とKPIを見直すことができます。実際に本質から外れたKPIをいくつか改めることができました。
最後に
参考になった内容はありましたか?
これを機にまだ4つのキーメトリクスを測ったことがない方は、一度レベル感を確かめてみてはいかがでしょうか。厳密な精度は問わず、一旦感覚で評価するのもありよりのありですよ!
ちなみに私たちチームの評価はこのような結果でした。
| メトリクス | レベル |
|---|---|
| リードタイム | ハイパフォーマー |
| デプロイ頻度 | ハイパフォーマー |
| MTTR | ハイパフォーマー |
| 変更失敗率 | エリート |
それではよい週末を。