こんにちは。まっちゃんです。
前までは上流工程などで要件決めを携わることが多かったのですが、ここ半年で開発機会を増やしています。
改めてレビューで多くの指摘をもらったり、設計思想の考え方、効率的な書き方など日々学ばせて頂いてます。
考えながらのコーディング、楽しいですね。
今回は GCP をガッツリ触ってシステム構築をしたり、 TypeScript でのアプリケーション開発を一から行いました。
仮説検証におけるコストパフォーマンスやシステム開発のコストパフォーマンスのバランスについて考えるきっかけになったので今回書くことにしました。
今回携わったプロジェクトのプロトタイプのアーキテクチャについて
今回作成したプロトタイプのシステム構築、アプリケーション開発をしたアーキテクチャを紹介します。
※ プロトタイプの解釈について
今回の記事ではプロトタイプとして紹介してますが、これを元に追加機能開発を行なっていくと思っているので実質 MVP (実用最小限の製品)では無いか?という声もあります。
現状開発は進んだものの、まだ顧客の価値やユーザーフローについてはまだまだ不確実性が高いです。
現状の開発チームでは UX の要件や仮説があるものを MVP として進めています。
なのでこの記事ではプロトタイプとして紹介します。
要件
開発チームが定義した要件を紹介します。
- プロトタイプで実現すること
- 外部データ(CSV)アップロード後のデータ整形、分析用テーブル作成のシステム化
- 展開しやすい仕組みを作成する
- BI ツールで使用するデータを BigQuery 上で管理できるようにする
- 外部データ(CSV)アップロード後のデータ整形、分析用テーブル作成のシステム化
- 機能一覧
- 外部データ(CSV)アップロード機能
- 外部データ(CSV)を BigQuery に登録することができる
- 外部データ(CSV)アップロード機能
ざっくり言うと 「誰でも外部データ(CSV)をアップロードすればBigQueryに登録することができる」 を実現します。
アップロードシステムとして業務で欠かせない存在となっている Google Drive を採用しました。
システム構成
プロトタイプのアーキテクチャについて紹介します。
今回は GCP を採用しました。
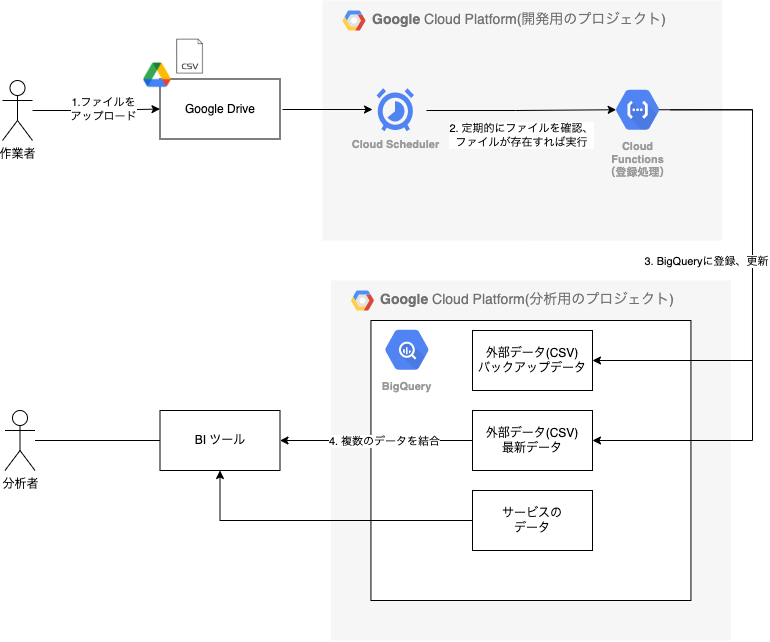
構成図を見てもらえればわかりますが、インプットが Google Drive のファイルアップロード、アウトプットが BigQuery となるため、 GCP を採用することで考えるポイントを少なくしてます。
テーブル構成
外部データ(CSV)ごとに作成します。
実際に BI ツールで参照するテーブルとバックアップ目的のテーブルをデータセットごとに分離しました。
hoge_dataset
└── xxx
└── yyy
hoge_backup_dataset
└── xxx_{yyyymmdd}
└── xxx_{yyyymmdd}
└── yyy_{yyyymmdd}
└── yyy_{yyyymmdd}
また BI ツールやクエリで扱いやすくするために、モードは NULLABLE を許容せず、 REQUIIRED とします。
もちろんデータに NULL はありえるため、アプリケーションで NULL だったら 0 や空文字などのデータ変換を行います。
処理内容
簡単にですが下記のように進めます。
- 1: ファイルをアップロード
- 作業者が外部データ(CSV)を用意する
- Google Drive の共有ドライブ内にある指定されたフォルダにアップロードする
- アップロードのタイミングは特に考慮しない(2で実施)
- 2: 定期的にファイルを確認、ファイルが存在すれば実行
- Cloud Scheduler で設定を行い、 Pub/Sub 経由で Cloud Functions を定期的に実行する
- 3: BigQueryに登録、更新(Cloud Functions で実行する関数)
- Google Drive API を用いて外部データ(CSV)を取得する
- 必要に応じてデータ加工する
- 登録用の一時ファイルの JSON を作成する
- JSON を元に BigQuery へ登録する
- 4: 登録できたファイルは削除する
アプリケーション構成
所属している組織ではバックエンドを Scala、 フロントエンドを TypeScript 使って開発を行なっています。
組織で採用しており属人化しにくい言語、Cloud Functions のランタイム選定も踏まえて今回は Node + TypeScript を採用しました。
構成は下記の通りです。詳細は苦労したポイントでも解説します。
. ├── index.ts ├── jest.config.ts ├── src ├── __tests__ │ │ └── xxx.spec.ts │ ├── bigquery │ │ └── index.ts │ ├── csv.ts │ ├── env.ts │ ├── gdrive │ │ ├── __tests__ │ │ │ └── xxx.spec.ts │ │ ├── index.ts │ │ └── types.ts │ ├── index.ts │ ├── types.ts │ └── util.ts ├── tsconfig.json └── yarn.lock
フロントエンドの知見も活かして CI で ESlint/Prettier の整形や Jest のユニットテストも組み込みました。
Gcloud SDK を使った CD も組み込んでます。
苦労したポイント
Google Drive API の操作や CD でのデプロイなど、細かいところではいろいろあります。
個人的に大きく印象に残っているのは下記 3 つです。
1: アプリケーション構成、テスト
テストを書くために固い構成は必要無い
テストを書くために、構成をガチガチに固める必要があると思ってました。
自分自身が過去に書いてきたコードは Scala で DDD や Clean Architecture で構成されており、テストも各層で書くことができます。
またフロントエンドも直近は Atomic Design を採用しており、 Presentational Components, Container Components で UI とロジックを分離して、Container Components にユニットテストを書いてます。
なので自分自身はガチガチに固める必要があると思ってましたがペアプロ時に「アップロードするというユースケースだけだからガッツリ構成を作り込まなくて良い」「動くことを優先しつつテストを書いて調整していけば良い」という助言も頂き改めて自分の中でのアプリケーション構成とテストの関係性が更新できたと思います。
今回のアプリケーション構成のポイント
改めてアプリケーション構成を見ます。
. ├── index.ts ├── jest.config.ts ├── src ├── __tests__ │ │ └── xxx.spec.ts │ ├── bigquery │ │ └── index.ts │ ├── csv.ts │ ├── env.ts │ ├── gdrive │ │ ├── __tests__ │ │ │ └── xxx.spec.ts │ │ ├── index.ts │ │ └── types.ts │ ├── index.ts │ ├── types.ts │ └── util.ts ├── tsconfig.json └── yarn.lock
ポイントはインフラストラクチャーレイヤーである Google Drive や BigQuery でディレクトリを分割していることです。そうすることで、データ加工などのロジックのテストが書きやすくなってます。
今は一つの外部データ(CSV)のみに対応してますが、 src 内のディレクトリを複製することでそれぞれの外部データ(CSV)に対応しやすくなり、拡張性も有ることもポイントです。
複雑な構成にしなくても押さえるべきポイントを押さえてユニットテストを書ける。という学びになりました。
2: サービスアカウントの権限や API の有効化
複数のサービスを触るので権限が必要
実装はできる、個人アカウントからも操作できる......という場合は大体権限絡みの問題でした。
特に最初の開発時点ではサービスアカウントでは無く個人アカウントで認証を行い、作業をしていました。
CD 実装で、サーバーアカウント経由での gcloud で Functions デプロイを行なうとデプロイできない問題がありました。
サービスアカウントの権限に「サービス アカウント ユーザー」の権限が無いとデプロイできなかったのはなかなか盲点でした......。
複数のサービスを使うため API の有効化が必要
本番環境を一から構築していた時の話です。
今回テスト環境は全体の検証環境をお借りしたため、既に API が有効になっている状態だったので必要だったことに気づかなかったです。
今回のシステム構成では下記 API を有効にすることで正常に動作を確認することができました。
エラーを見ては有効化にするという、トライアンドエラーの繰り返しでした。
- Cloud Resource Manager API
- Cloud Build API
- Drive API
3: GCP のマルチプロジェクト故の問題
社内特有のマルチプロジェクトの事情
所属組織の GCP 活用の歴史として、 BigQuery を使っていました。
BigQuery へ一部の自社データを同期して BI ツールで参照する目的で使われました。
その後は一部で GCE, S3, GKE が使われるようになっていきました。
BigQuery はプロダクトの分析用の GCP プロジェクト。
その他はプロダクトの開発用の GCP プロジェクトと言った使い分けです。
今回の要件では Cloud Functions はプロダクトの開発用の GCP プロジェクトで動かして、 BigQuery への登録はプロダクトの分析用の GCP プロジェクトへ登録する必要がありました。
開発時はここを考慮できてない故に本番環境構築後に動作確認を行うとプロダクトの開発用の BigQuery に登録されてしまうことになりました。
対応内容
実際にライブラリのコードを確認しました。
https://github.com/googleapis/nodejs-bigquery/blob/v5.10.0/src/bigquery.ts#L273-L280
分析用の GCP プロジェクトのサービスアカウントのクレデンシャルを参照すれば良さそうです。
const bigquery = new BigQuery({
keyFilename: '/path/to/keyfile.json'
});
.env を下記の形にしてローカルで動いたのでこれで良しと思ってました。
BIGQUERY_PROJECT_CREDENTIALS="/path/to/keyfile.json"
これだと CD 時に問題が発生します。
gcloud functions deploy では --env-vars-file 指定してビルド変数を指定してますが、ファイルパスのみの記載だともちろん動かないんですよね......
かといってクレデンシャルファイルも成果物として CD するのは非常に良くないです。
Secret Manager は機密データを保存するサービスでかつファイルマウントもできたので今回は Secret Manager で対応しました。
Secret Manager 登録後に、 gcloud beta functions deploy で --set-secrets=/credentials:latest=hoge-credentials:latest のオプションを渡せば OK です。(Secret Manager を使用する際は alpha or beta を使ってください)
が「Secret Manager のシークレット アクセサー」の権限が無いと正常には動かないので改めて権限には気をつけてください......。
アーキテクチャ選定をふりかえって
スプリントレビューで議論が合った内容も踏まえつつ、自分なりに考えてみます。
データ分析基盤への入り口
現在私が所属している組織、アドテクノロジーディビジョンでは自社データの分析やチューニング、外部データ活用を始めとした「データ」を使うことで事業への影響を与えるために「データ最適化で売上UP」を掲げています。
自社サービスのデータとしてインプレッション、クリック、コンバージョンといった様々なデータがあります。
外部データとして検索キーワードや広告主が保持しているデータがあります。
それらを組み合わせて新しい切り口を開いて売上を上げる = データ最適化で売上UPに繋げようとしてます。
仮説検証とシステム構築のコスパ
アドテクノロジーディビジョンでは新規開発では MVP 開発を行います。
データを見て、仮説を立て、実際に作り、学びを得て新しい仮説を立てる。
その繰り返しを行い、提供価値があるのか?規模を拡大させるか?などを考えます。
PM は図などを使って上記を判断などを行なってます。(詳細は下記記事を参照)
自身も過去に何度かプロダクト新規開発に携わりましたが、失敗に終わりました。
様々な原因はあると思いますが仮説を多く立てれなかった、仮説を立証するための検証スピードが遅かった。というのがあると思います。
事業優位性を上げるためにスピードは大事な一要素だと思ってます。
仮説検証を行うために、エンジニアは確実な要件を素早く作ることが必要です。
データを使った仮説検証のコストパフォーマンスを考えてみる
どうすればデータ活用を活発にしつつ、仮説検証を進められるでしょうか?
以下の内容が考えれるかなと思います。

API を使ったデータ連携
イメージしやすいですね。
サービスが相互に API 連携しあうので良く使われている手法だと思います。
正式な機能提供だと必要不可欠です。
メリット
- API 仕様があるので決められた仕様でやり取りすれば良い
- アプリケーションが操作しやすい
デメリット
- API 仕様が変わると都度対応が必要になる
- 使用者との連携
- バージョンアップ対応
クラウドストレージ(バケット)を使ったデータ連携
これもイメージしやすいですね。
指定したクラウドストレージ(バケット)に対して読み書きする形です。
これはある程度仮説検証が進んでのフェーズ〜正式な機能提供で出てくるイメージです。
メリット
- 一度ストレージの場所が決まればそれに対しての操作を行えば良い
デメリット
- 作成側はデータ生成されているかを都度確認が必要、監視する仕組みも必要
- 読み込み側はデータが生成されてない時の例外処理を作らないといけない
ローカルで作る
手動で作るパターンですね。これは本当に価値があるのか?価値模索で出てくる印象です。
今回のプロジェクトも最初はディレクターの方がデータを取得してローカルで作って価値模索を行なってました。
メリット
- 手動でできるのでやりたいことはシステム開発を待たずともすぐできる
- 作業が確立すれば他の方にお願いすることができる
デメリット
- 都度都度対応が必要
- 本格的な仮説検証を行う時に手動での対応は限界がある
データ連携をしない
自社のデータのみで頑張るパターンです。あえてこういう選択肢を取る場合も出てくると思います。
メリット
- 今あるデータなら追加開発が不要
- データ分析基盤が整っていればエンジニア以外も触れる
デメリット
- 自社のデータだけでは仮説検証に限界がある、切り口が見つからない可能性が高い
システム開発のコストパフォーマンスを考えてみる
開発する上でやってみたいことややりたいこと、いろいろ追い求めればそれだけ工数もかかります。
携わってみた開発構成などを元に考えてみます。

フロントエンド、バックエンドを作る
よくある構成ですね。UI とロジックが分離できるので分担も行いやすく、品質担保もしやすいです。
基本的にシステム同士の API 連携でフロントエンドとバックエンドを繋ぐ形になります。
ですがフロントエンドのアーキテクチャ、バックエンドのアーキテクチャなど考えるポイントは多くなります。
Clean Architecture や Atomic Design など構成を考えるのは楽しいですが、事業や仮説検証のことも考えるとある程度のところで落とし所を決めるべきです。
スピード、実装優先で、アーキテクチャも考えない!テストも書かない!だとそのツケはいずれ返ってくるので一番避けるべきです。
テストを書かないことで失敗した経験は何回もあります。
サーバ・インスタンス、コンテナ、サーバレス
コンテナ技術の進歩、クラウドの活用などで選択肢は増えました。
サーバ・インスタンスを選択するといろいろ見るべきポイントは増えます。ですが今は Ansible で構成管理を行なっているため、昔より運用は楽になっています。
コンテナも一部では採用してますが、クラウドサービスで扱うための知識や技術は必要で、初めて行う場合はどうしても時間がかかります。これはサーバレスも言えますね。
ですがクラウドサービス側が面倒を見てくれてる部分もあるので、サーバ・インスタンスと比べるとメンテナンス部分はだいぶ楽になりますね。
外部サービス
OAuth 認証などの仕組みを使って外部サービスを使うパターンです。
今回はアップロードという要件があるものの、 Google Drive へのアップロードという設計を行い、アップロードする仕組みは作り込まないという選択肢を取りました。
早い機能を作る上ではこういう選択もあることを実感しました。
コンソール・CLI
本当にサクッと作りたい場合は簡単なスクリプトで済ませることもあると思います。
シェルスクリプトを作ってジョブ管理ツールで動かすなど昔は多くやってました。
データ分析基盤の入り口を最適なコスパで行うために
いろいろ洗い出して見ましたが結局今回はなんでこういう設計にしたのか?という部分を「コスパ」を意識して書いていきます。
なぜ管理画面でアップロード画面を作らないのか、スタンダードな設計では無いのか
よくある構成でアップロード機能を作るとなると以下の観点で設計を考える必要があります。
- アップロード
- アップロードページの作成
- アップロードに必要なパラメータをバックエンドに渡す
- バックエンド
- パラメータのバリデーション
- アップロード処理
- 容量がどれくらいまでいけるのか
- インフラ
- アップロードするための権限
- アクセスするユーザを制限するための認証
- アップロード先のストレージ
- どこに保存するか
今回のプロトタイプでは Google Drive を採用したため以下の点のみで済みます。
多くは Google Drive で担保をしているためです。
- アップロード
- Google Drive API の取り扱い
- アップロード先のストレージ
- フォルダを作成
考えるポイントは少なくなるので「外部データ(CSV)をアップロードをしたい」という要件に対するコスパは良さそうです。
なぜクラウドで GCP を使い Cloud Functions を採用したのか
インプットが Google Drive のファイルアップロード、アウトプットが BigQuery となるため、 GCP を採用することで考えるポイントを少なくした。と書きましたが他にもあります。
仮説検証はフェーズによって拡大していくことが大事になるタイミングがあります。
その際に拡大しにくいシステムアーキテクチャだとどうでしょうか?事業とシステムの乖離が起きてる場合です。
頑張って追加要件に対応していくのか、一から作り直すのか、要件や機能を削ぎ落とすなどが考えられますが事業や仮説検証のスピードを考えるとなかなか難しい選択になります(PMもエンジニアも)。
その際に拡大しやすいシステムアーキテクチャならどうでしょうか?
今回は Cloud Functions を使ってますが、別のデータアップロードをしたい。データを加工して組み合わせたい。という要件が仮に来た場合、新規で Functions を作れば対応しやすいのかなとも思います。
今は Pub/Sub は Cloud Scheduler のメッセージ用途でしか使ってませんが、データパイプラインとして Pub/Sub と Cloud Functions を組み合わせて実装するパターンもありそうです。
こういうことができると今回のプロトタイプを元に BigQuery にデータを集約して、 BI でどんなデータも触れる未来もそう遠くないのかなと思います。データの民主化も見えてきそうです。
(ここまで来るとエンジニアとしてはパイプラインを整備したいから Cloud Workflows や Dataflow を使いたいっていう欲は出てきそうですが笑)
まとめ
長々と書きましたが大きく伝えたいことは下記の点です。
- データを使った仮説検証のコスパとシステム開発のコスパの落とし所として
- 今回のプロトタイプでは「Google Drive」を使うことでアップロード機能関連の処理の考えるポイントをまるまる減らせた
- クラウドサービスを活用することで今後の事業や仮説検証の拡大にも追いつけそうな仕組みができた
要件を決めてから動くようになるまでは一ヶ月もかかってないです。開発自体は1週間+αで完了しました。
(もちろんここはチームやテクニカルマネージャー、プロダクトマネージャーの協力もあるからです、いつもありがとうございます)
このブログを書くにあたってのアウトライン作成をマネージャーと一緒に行いましたが、リードのシステムエンジニアには「事業の状態や会社の状態を考えた上のアーキテクチャ選定をしてほしい」という言葉を頂きました。
ただ要件を鵜呑みにする、品質のことばかり考えるのも非常に良くないです。
事業のことも踏まえた技術やアーキテクチャ選定、品質のバランスは非常に難しいですが引き続き頑張ります。