こんにちは、ADWAYS DEEEでアプリケーションエンジニアをやっている渡辺です。
現在、私は携わっているプロダクトで生成AIを組み込んだ機能を開発しています。そこでこの記事では、生成AIをどのようにプロダクトに取り入れたかをご紹介したいと思います。
背景
近年、広告において、誤った表現や誤解を招く表現を避けることが求められています。
また、そのような広告は広告主のブランドイメージを悪くしたり実際に利用するユーザーに不利益があったりとどちらにとっても好ましくない結果をもたらします。
そのため、アフィリエイト広告においては実際に各メディアで表示している内容の確認と広告表現ルールとの照らし合わせが重要となります。
従来、これらの違反チェックは人間の目視で行われていましたが、作業コストが高く、見落としのリスクもありました。
そこで、生成AIを活用して広告部分を画像として取り込みテキストを解析し、規制違反の可能性がある表現を提示できるツール(以下、「本ツール」)を開発しています。
このツールでは以下の課題に取り組みました:
- 画像内のテキスト抽出(OCR)
- 抽出テキストから違反表現の検知
- 検知精度の定量的評価と継続的改善
システムアーキテクチャ
本ツールのテキスト検知機能は以下のような構成になっています:
graph LR
A[広告画像] --> B[OCR処理]
B --> C((テキスト抽出))
C --> D[生成AI分析]
D --> E((違反検知結果))
E --> F[アプリケーションDB]
主要コンポーネント:
- OCR処理: Google Cloud Visionなど
- テキスト分析: VertexAIなど
- データ保存: 各種DB
- 処理制御: Go言語によるバックエンドサービス
実装アプローチ
OCR処理とテキスト分析
システムのフローを簡単に説明します:
- Google Cloud Visionを使用して広告を含んだ画像からテキストを抽出
- 抽出したテキストをブロック単位で処理・整形
- 生成AIに規制ワードなどと照合させ違反の可能性があるテキストを検知・抽出
システム内で生成AIを含むAPIを組み合わせて実行し、目的とするデータを抽出しています。
生成AIの活用アプローチ
生成AIは一見すると賢く答えを返してくれるように見えますが、万能というわけではありません。
生成AIの性能を最大限に引き出すため、いくつかの工夫をしました。
特に重要だったのは以下の点です(今もアプローチ方法が変わっていっているのであくまで現時点の重要項目です)
- 明確な指示と役割の設定:生成AIに対して明確な指示と役割を与えることで、より精度の高い判定を実現
- 構造化された入出力形式:一次情報である画像をそのまま渡すのではなく、テキストデータを構造化して渡すことで判定精度を向上
- 二段階判定による精度向上:一次判定と二次判定の2段階で処理することで、誤検知を削減
この設計により、例えば「絶対安心!」のような過度な誇張表現を高精度で検知できるようになりました。一方で、「比較的安心できる」のような実態にあった表現は適切に許容するという判断ができています。
品質保証と性能評価の仕組み
本ツールでは、開発フェーズと性能評価フェーズを明確に分離し、それぞれ異なるアプローチで取り組んでいます。
以下はテストに着目したシステムのチャートです。
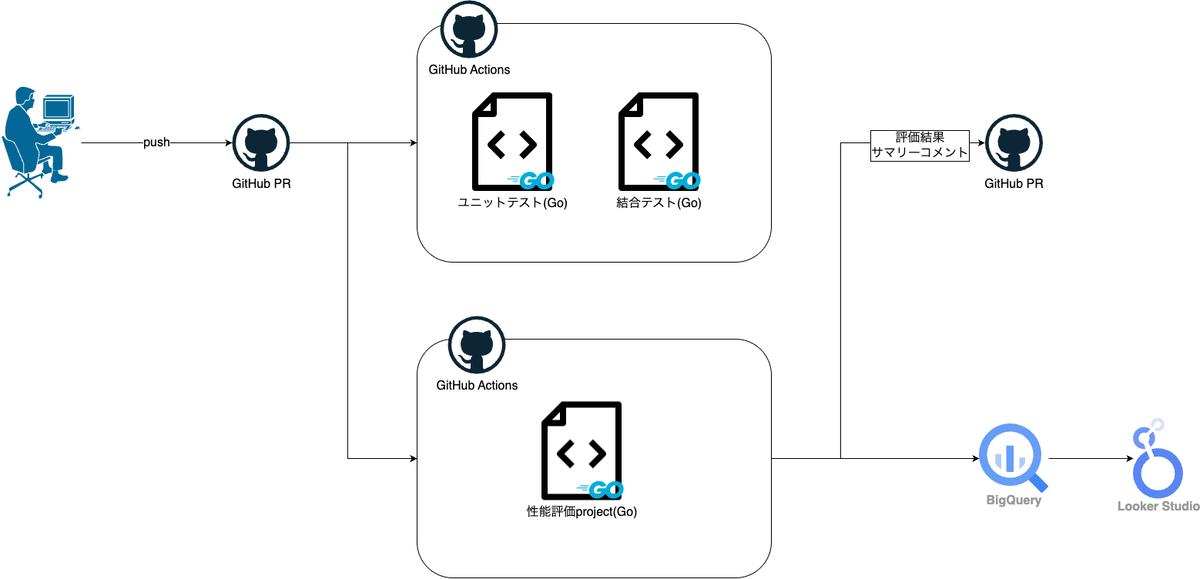
開発時の品質保証
実装フェーズでは、以下のような品質保証の仕組みを導入しています:
ユニットテスト: 各コンポーネントが期待通りに動作するかを確認
- OCR処理の正確性テスト
- テキスト分析ロジックの動作確認
- この時点では精度に着目せず、最低限レスポンスを返せるかに重きを置く
- エラー処理の検証
統合テスト: システム全体の連携が正しく機能するかを確認
- 画像入力から検知結果出力までの一連の流れのテスト
- ここでも精度については置いておく
- 画像入力から検知結果出力までの一連の流れのテスト
これらのテストはCI/CD環境で自動実行され、コードの品質維持に貢献しています。
実装時点では精度に関するテストはおいておき、ローカル上で実データを試すなどに留めています。
精度の担保まで実装の段階で要求してしまうと、成果物を出すのが遅くなってしまいます。
まずは機能を出し、ステークホルダーやユーザーに機能が有用かどうかフィードバックをもらうのが重要なので精度をこの段階で厳密には求めません。
別環境での性能評価システム
本ツールの特徴は、実装とは別の独立した環境で性能評価を行っている点です。この分離により、客観的な評価と継続的な改善が可能になっています:
定量的な評価基盤:
- 精度指標(Precision/Recall/F値)の計測
- テスト用データセットによる評価
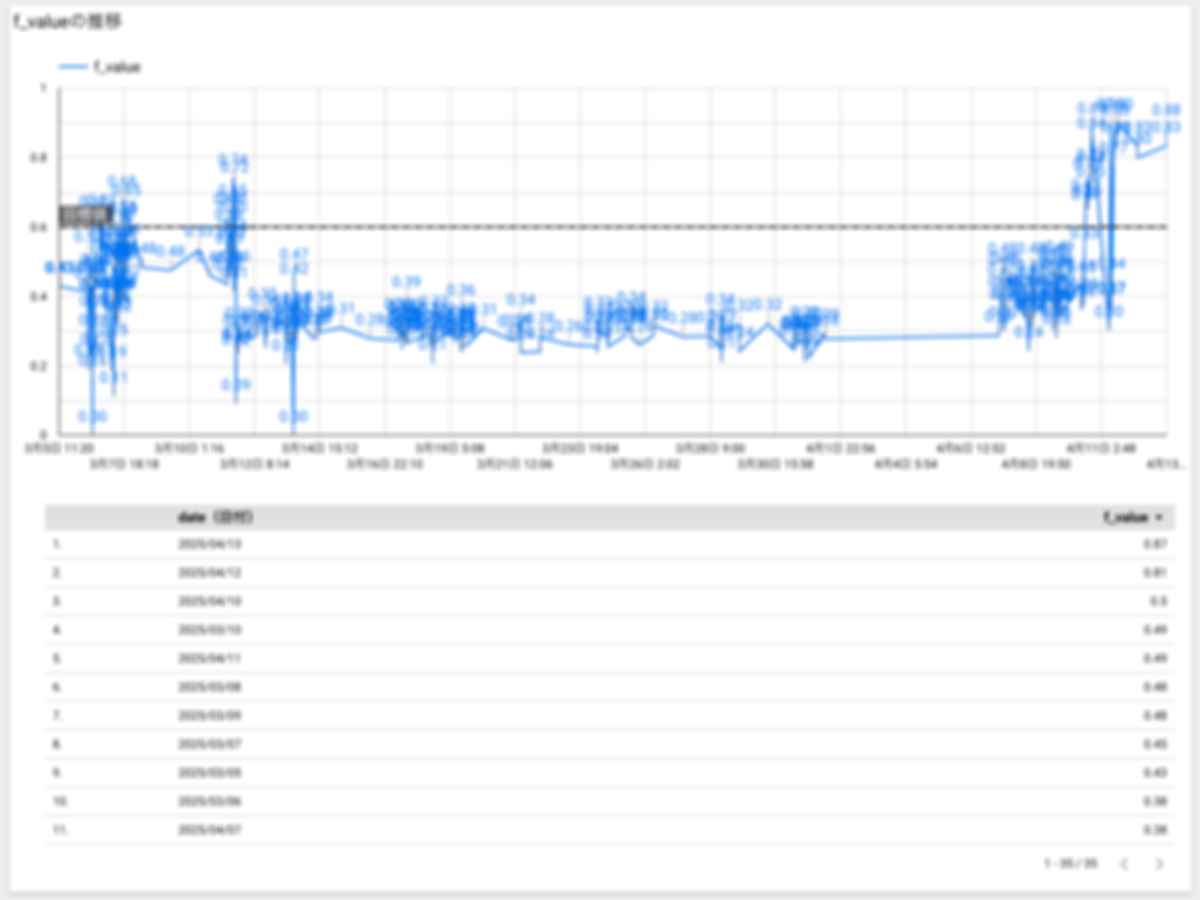
時系列での性能追跡:
- 評価結果をBigQueryに蓄積
- Looker Studioによる可視化と分析
フィードバックループ:
- 評価結果に基づく改善ポイントの特定
- 改善後の効果測定
特に、精度評価では以下のような指標を用いています:
- TP(True Positive): 正しく検出できた件数
- FP(False Positive): 誤って検出してしまった件数
- FN(False Negative): 検出できなかった件数
- F値: 精度と再現率の調和平均
性能評価テストはリモートリポジトリに変更があるごとに行われ、そのデータはBigQueryに蓄積されます。
その結果をエンジニアはもちろん、プロダクトオーナーやステークホルダーも自由に見ることができる状態にしています。

効果と課題
この取り組みによって得られた主な効果は以下の通りです:
定量的な評価基盤の確立: AIの性能を数値で把握できるようになり、改善の指針が明確になりました。これまでは「このツールはどれくらい正確なのか」という質問に対して感覚的な回答しかできませんでしたが、現在は精度・再現率・F値といった客観的な指標で説明できるようになっています。特に経営層や他部署との対話においてツールの信頼性を具体的な数値で示せることは大きな価値がありました。
ステークホルダーとの認識共有: 「現状の進捗、精度はXX%です」と具体的に説明できるようになりました。これにより、プロジェクトの透明性が高まり、エンジニア以外のステークホルダーも含めた建設的な議論が可能になりました。具体的に、精度が現状XX%であるなら実践投入するにはYY%くらいが必要になりそうだといった定量的な数値による会話が発生したりしました。
一方で、開発を進めていく上で以下の課題も見えてきました:
- エッジケースへの対応: 想定外の表現パターンにどう対応していくか
- テストデータの多様性確保: 性能を評価する上で必要な網羅的なテストデータの作成
- 精度向上の限界: 生成AIの特性による精度の上限をどう扱うか
これらの課題の解決には現在鋭意取り組んでいるので、今後の進展にご期待ください。
まとめと今後の展望
生成AIを使った違反テキスト検知ツールを開発し、継続的に精度を測定・改善する仕組みを構築したことで、より高精度な広告表現是正の効率化が可能になりつつあります。
本プロジェクトを通じて、AI技術を実際のビジネスシステムに組み込むうえで重要なのは、モデルそのものよりも「評価」と「改善サイクル」の設計であることを実感しています。どれだけ高性能なAIモデルを採用しても、その性能を客観的に測定し継続的に改善していく仕組みがなければ、実用的なシステムにはなりません。
生成AIを活用したシステム開発では、単に「動くもの」を作るだけでなく、その性能を定量的に評価し継続的に改善していく仕組みが重要です。今回紹介した取り組みが、みなさんのAI活用プロジェクトの参考になれば幸いです。
ちなみに、柔らかい親しみやすい文体が好きなのですが今回はテックブログっぽく硬めに書いてみました。
でもやっぱりフレンドリーな文章にしたくなってしまいますね。次回私が書く際はまたフレンドリーな感じになっていると思います。それでは。