新年明けましておめでとうございます!
ADWAYS DEEEでリードアプリケーションエンジニアをしています、中村です。
今回は、自社サービスのDBクラウド移行に取り組んだ話について書こうと思います。
背景・目的
サービスについて
今回のDBクラウド移行の対象サービスは、機能開発は止まっておりメンテナンスのみを行なっているサービスでした。
Divとして(部署として)DBクラウド移行の実績はあったものの、なかなか優先度が上がらずにいました。
そんな時、インフラストラクチャーDivからオンプレミス(自社で運用・管理しているの意、以下オンプレ)のサーバに関して費用削減の提案がきました。
金額的にもインパクトの出せるプロジェクトだったので、これを優先的に進めることになりました。
チームについて
私の所属するアドテクノロジーDiv(以下アドテク)では、7月あたりからスモールチーム化を進めています。
これはチームのエンジニアの人数を最大3人に抑えることでフロー効率を優先させてプロジェクトを進めることができるようにすることを目的としています。
私のチームは内部ではクラウド化チームと呼ばれており、3人で構成されています。いずれも当該サービス仕様には明るくない状態でした。
方針
今回のクラウドDB移行は以下のような方針で進めました。
ロールバックしやすい体制を整える
先ほど述べた通り、クラウド化チームの3人は当該サービス仕様には明るくない状態でした。加えて、プロジェクト開始時点では明確な納期が存在せず、時間をかけようと思えばいくらでもかけられる状態でした。
ただ、このままでは仕事が進まないので、ロールバックしやすい体制を整えることを前提に、影響範囲の調査は最低限にとどめました。
具体的には、以下のようなことを行いました。
- Reader(READ系クエリが来るDB)については、既存のDBを一気にリプレイスするのではなく、レプリケーション対象としてクラウドDBを追加して、徐々にクエリを捌けていることを確認(数日の様子見)してから既存のDBをサービスアウトする。
- 既存のWriter(WRITE系クエリが来るDB)に向いているクエリのうち、Readerに向けても問題ないクエリをReaderに向けるように変更する。
- Writer移行は整合性の問題が発生するため、一気にリプレイスする必要がある
- その移行の影響範囲を最小限にすることが目的
今までの移行実績に則る
アドテクでは、他のサービスのDBクラウド移行を実施しており、その際に得たノウハウを活かすことで、今回の移行を進めました。
状況としても以下のような共通点があり、今までの移行実績に則ることができました。
- オンプレのサーバで動いている
- MySQL 5.6系
- 移行先はAmazon Aurora(以下Aurora) 3系
- MySQL 8.0系
- 構成として似たサービスの移行経験がある
- MySQL 5.6系 → MySQL 8.0系
- この2つのバージョン間にはレプリケーションの互換性がない
- オンプレにDBが2台あり、それを1台に統合する要件がある
- MySQL 5.6系 → MySQL 8.0系
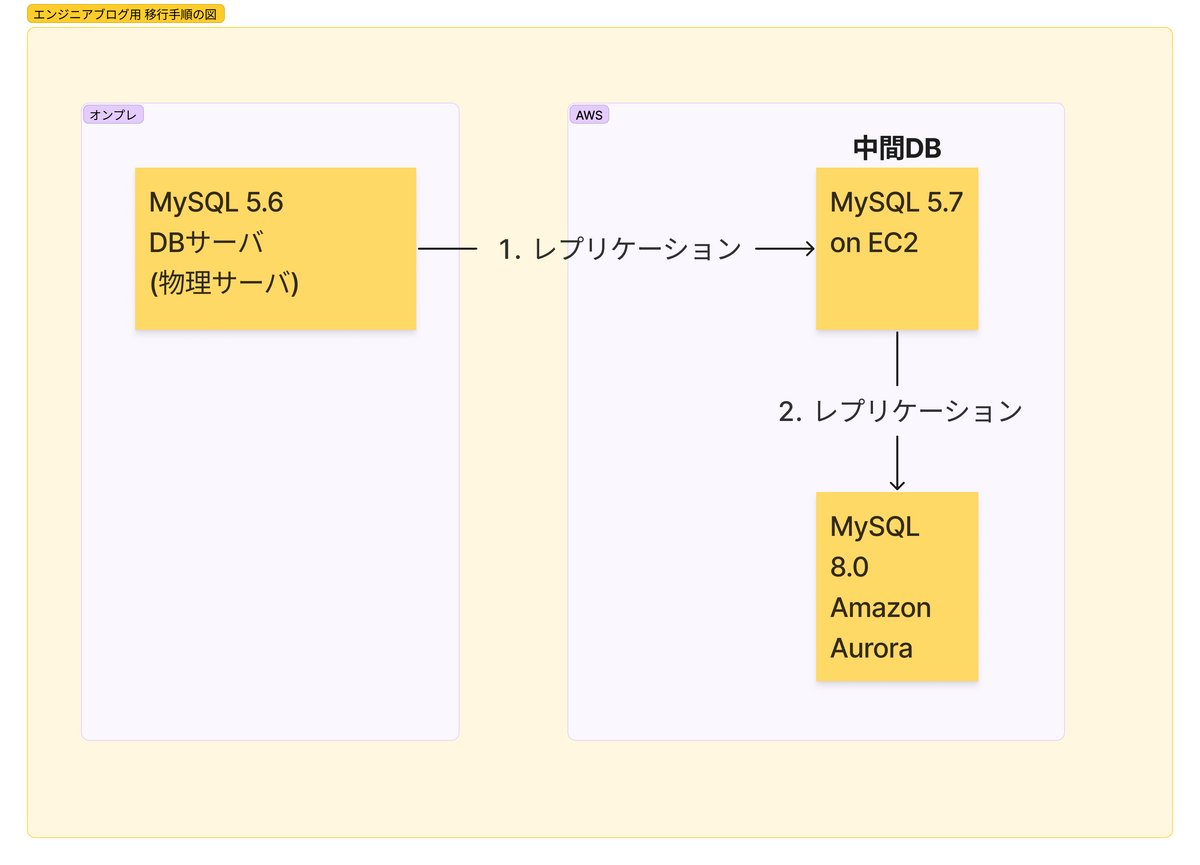
具体的には、以下の図のように5.7系のMySQLを経由して8.0系のMySQLに移行することで、移行を進めました。
優先度を決めて課題に対応する
言葉にすると当たり前ですが、実際に実行する上で大事だと思ったので書いておきます。
移行途中で発生した問題・発見した既存のサービスの課題の対応について、以下のように優先度をつけて対応しました。
- それを解決しないと移行が進まないものに関しては、直ちに対応する
- ただし、回避できるものに関しては回避し、移行後に運用タスクとして対応する
- そうでないものに関しては、移行後に運用タスクとして対応する
特に今回は機能開発が止まっているサービスのため、4年以上触られていないDockerのimageやMySQLのバージョンが上がったことによるdriverがbundleされているpluginの更新に必要な依存関係の解決(ここまで一息)など、ちょっと顔をしかめたくなるレベルの技術的負債が溜まっていました。
その他: チーム運営的なところ
通常のエンジニアのチームでは、各個人にタスクを割り振って毎日朝会で進捗を確認する、みたいな進め方が一般的だと思います。
ですが、今回はメンバーが3人でチームも新たに編成されたということもあり、少し変わった進め方をすることにしました。
それは、コアタイムである12-17時(昼休憩は13-14時)はZoomを繋ぎっぱなしにして、モブプログラミング(モブプロ)形式で1つのタスクを進めていくというものでした。
画面共有をする人(ドライバー)はローテーションし、1時間ごと(作業50分:休憩10分)に交代します。
この形式にすることで、以下のようなメリットがありました。
- 画面を共有してるので、コマンドなどの小技を含む具体的な知見の共有ができる
- 障害対応や調査、各タスクの最初の設計など不確実性の高い部分の対応について、話し合いながら進めることができるのでスムーズに進められる
- その場で議論したり雑談したり、コミュニケーションが活発になる
- 3人で常に認識を合わせて進められる
- いわゆるスクラムイベントのような会議はグッと減る
一方で、以下のようなデメリットもありました。
- 作業の進捗、全体像が見えにくい
- 全員が一つのタスクに集中するため
- 個人の理解度によって3人で進める上で効率が悪いと感じる場面があった
- 全員がわかりきってるタスクや個人でもできるタスク
- 他の2人がただみているだけになってしまう
- 1人だけがわかっていなくて、他の2人が理解しているタスク
- 3人で進めるというよりは教育的な意味合いが強くなる
- 分担できる作業は途中から分担したが、どうしても直列になる場面もあった
- 全員がわかりきってるタスクや個人でもできるタスク
- ローテーションの途中で一人が抜けた場合、その合流や共有に時間が取られる
個人的には、この進め方はとても気に入ってます。同じタスクでも人のやり方を学べたり、作業時間帯の前後で自分の理解を後追いできたり個人タスクを進められたりするので学びが多かったです。
特に思い出に残っている課題と解決策
全体としては2ヶ月ほどで移行を完了しました。(今年の8月中旬~10月中旬) その間に発生した課題と解決策のうち、特に思い出に残っているものをいくつか紹介します。
サブネットやネットワーク設定から整備する
クラウド化が本格的に始まってないサービスのため、最低限のサブネットやネットワーク設定のみされていました。しかしそれさえも命名規則がバラバラだったので、その辺りを統一するところから開始しました。
命名に関しては、他のサービスを参考にしたのでそこまで時間はかかりませんでした。(:今までの移行実績に則る)しかし、ネットワークの面で見てみると一部のバッチ処理が他のサービスのDBに依存していたり、他のサービスのバッチ処理が当該サービスのDBに依存していたりと、依存関係が複雑に絡み合っている部分がありました。密結合ではあるもののすぐに対処するのは難しいため、一旦通信を許可することでこの課題は回避しました。(:優先度を決めて課題に対応する)
DB移行あるあるを綺麗に踏む
MySQL5.6系→8.0系なので、メジャーバージョンが2つ上がります。加えて、オンプレDBからクラウドのマネージドDBに移行します。デフォルトの設定が変わった部分や、挙動が変わった部分も多くありました。
特にびっくりしたものは以下の4つです。
group byは暗黙的にソートされる(5.7系)
これによりレポートの検索結果の並び順が狂ったので修正しました。
order by ASC/DESCで明示的にソートすることが推奨されています。
GROUP BY implicitly sorts by default (that is, in the absence of ASC or DESC designators)
UNIX_TIMESTAMP()関数が64bitの浮動小数点数をデフォルトで保持するようになり、結果が小数で返ってくるようになった
これにより、UNIX_TIMESTAMP()で取得した値が整数として期待されていた処理がエラーになり、修正が必要になりました。
The functions FROM_UNIXTIME(), UNIX_TIMESTAMP(), and CONVERT_TZ() now handle 64-bit values on platforms that support them, including 64-bit versions of Linux, MacOS, and Windows.
Writer, 中間DB, Reader全てのタイムゾーンがJSTに揃うように設定する必要がある
そもそも、MySQLサーバではシステムタイムゾーン(system_time_zone)とサーバの現在のタイムゾーン(time_zone)の2種類があります。
しかし、Auroraのパラメータグループで設定できるのはtime_zoneのみなので、そのままNOW()などで値を入れるとsystem_time_zoneのUTCが効いて値が9時間ずれます。
レプリケーションを2段階張っている(オンプレ→中間DB, 中間DB→Aurora)ためです。
なので、対処としてはオンプレDBのmy.cnfに--default-time-zoneを指定(+09:00)してmysqldを再起動することでずれをなくしました。
予約語にrowsが追加され、それがクエリに使われていた箇所があり、エラーになった
``で囲むことで回避しました。
シニアエンジニア不在での調査対応
チーム全体でエンジニアが3人なので、1人休むと2人になります。ここでの1人休むはシニアエンジニアが不在という意味です。
チームの中で頼れる先輩がいない中、自分が指揮をとって障害対応や調査に当たることが何度かありました。
調査は2人で行うのですが、周りへのコミュニケーションや連絡、今日どこまでやらなければいけないのかなどの判断、調査結果のまとめと共有などマクロとミクロの視点の両方を行ったり来たりしないといけなかったのが大変でした。幸い、経験を積む中でチームメイトの調査能力が高くなってきたので、自分はマクロな視点に集中できるようになりました。
職位としてリードに上がってから初めてその責任を求められる場面でうまく動けたので、自分の成長を感じることができました。
緊急度の高い差し込み案件
移行が始まって約1ヶ月経った時、別の機能開発が止まってるサービスのDBのEoL(End Of Life: サービスのサポート終了)対応が緊急度高く差し込まれました。調査と問い合わせの結果、EoLが伸びたので緊急度が下がり、移行を優先することになりました。
- 差し込まれたサービスはAmazon RDS(以下RDS) 5.7系で動いており、調査を始めた当初はRDS 標準サポート終了日が2023年9月でした(現在は延長されていて、パッチバージョンにより異なります)
この案件のおかげでスイッチングコストという言葉を身をもって実感することになりました。
良かったこと・改善したこと
ここまでは課題やマイナスな面を中心に書いてきましたが、良かったことや改善したことも書いていきます。
インフラストラクチャーDivから指定された期限に間に合った
当初は期限がなかったのですが、費用削減の見込みが立ったあたりで期限が決まりました。(10月末)
後からやることはそこそこ出てきたものの、方針が立った後は物量勝負みたいなタスクが多かったのでなんとか終わらせることができて良かったです。具体的には先述の以下のタスクです。
- 既存のWriter(WRITE系クエリが来るDB)に向いているクエリのうち、Readerに向けても問題ないクエリをReaderに向けるように変更する。
スプレッドシートにまとめて管理しながら作業しました。約300ファイルほどのアプリケーションコードを読んで、都度クエリの向き先が変更可能か判断し、可能なものについては変更しました。
バッテリー劣化のアラートがなくなった
当該サービスのDB物理サーバで運用していました。このサーバは度々ハードウェア劣化により、バッテリーの交換が必要な状態になっていました。
そのためDBを止めてメンテナンスが必要になったりする事象がこのプロジェクトに着手するつい数日前にも発生していました。こういう事象に限って深夜によく起こるので、なかなか悩みの種でした。
この悩みの種も、クラウド化により解決しました。
不要機能、コードの削除により見通しが良くなった
影響範囲の調査の過程で、不要と判断したコードはガンガン削除していくことで見通しが良くなりました。
また、バックアップ用の仕組みをマネージドサービスに委任することができるようになり、不要になりました。結果、AWS側に立てたDBインスタンスより多くの台数のオンプレサーバを返却することができ、費用削減に大きく貢献しました。
まとめ
今回はオンプレ→クラウド化の波に乗って、自社サービスのDBクラウド移行を行った話を書きました。
しかし、今のままだと数年後に数サービスのDBに対して、一気にEoLがきます。その時に一気に対応するのは無理大変なので、今後はクラウドの力を利用しつつ、運用保守をしやすいように改善を続けていきます。