ADWAYS DEEEでリードデータサイエンティストをしている上田です。
元々エンジニアとして入社したのですが、昨年の7月にADWAYS DEEEでデータサイエンティストのチームが新設されたタイミングで、筆者もデータサイエンティストへと職種を変更し本格的に分析業務を始めました。
分析チームとして専門的に動くのが事業部として初めての試みだったこともあり、現在まで1年強の期間で様々な学びがありました。
この記事では実際にどのような業務を行ったかを振り返りつつ、得た学びを紹介できればと思います。
(筆者は主にリワード広告のサービスであるAppDriverに関わっているため、その内容がメインです)。
データサイエンティストがどのように動いた結果、何が難しくて何を学べたか、具体的な内容やタイムスケールを含めてイメージが伝われば幸いです。
プロダクト全体のデータ分析
チームが発足して、まず最初に2〜3か月かけてプロダクト全体のデータ分析を行いました。
それまでも単発の仮説検証やその結果分析は行っていたものの、その場限りでの分析に留まっていました。プロダクトとして共通して追うべき目標や、解決すべき課題がしっかり定まっている状態が理想と考え、まずはその整備から始めました。
やったこと
まず、プロダクトとして追うべき指標を定義しました。
これまでの業務ではわかりやすい指標であるアクション率やeCPM (インプレッションあたりの実質的な売上) を追うことが多かったですが、以下のような事例もありました。
- アクション率は向上したものの、単価が大きく減少し、収益性はマイナス
- eCPMが一時的に向上するが、それでユーザーのリワード広告に対するニーズが満たされてしまい、その後eCPMが低下する
またサービスの特性上ライトユーザーが多い一方、一部のヘビーユーザーが売上の大部分を作っているという事実もあります。
そこでヘビーユーザーに注目した指標としてLTV (life time value) を導入することにしました。
LTVを中心に「何がLTVを決めるのか?」という分析を、単純集計から統計モデリング・機械学習までの幅広い技術を用いて分析しました。その結果、ユーザーの行動パターンについていくつかの考察が得られました。
図は分析途中で用いた、「決定木分析」のイメージです。
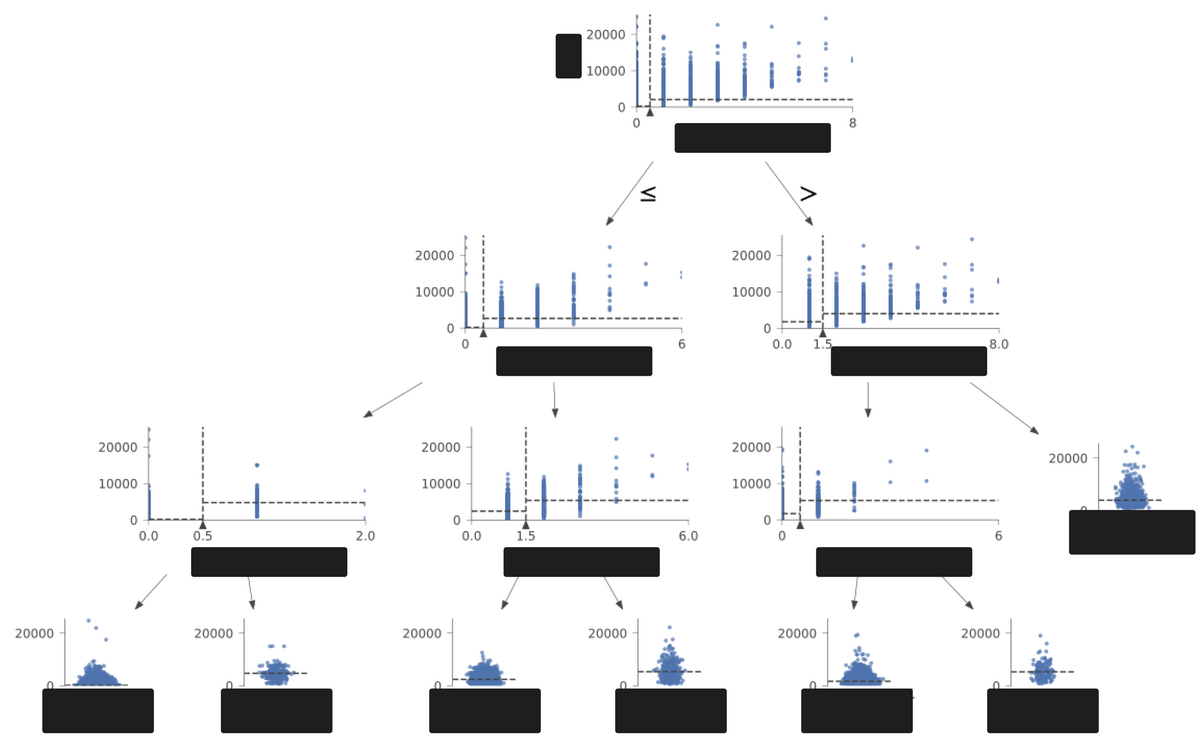
よかったこと
LTVは遅効指標かつ、サービスの特性上ユーザーの離脱 (= life timeの終了) が明確でないため、有限の時間内で正確に計測することは不可能です。そのためある程度割り切って、近似的な定義を決める必要がありました。
今回はひとまず定量データを元に妥当そうな基準を見つけることができ、関係者間での合意も取れました。
現在でも仮説検証において、(検証の内容によって直接的なKPIは変化するものの) LTVを上げるという目標を意識した設計・結果分析を実施できています。
また、LTVの分析において得られたユーザーの行動パターンなどの考察は、仮説検証のアイデアを出す上で非常に役に立っています。
難しかったこと
プロダクト全体の分析が初めてだったこともあり、分析手法の選定や、結果の解釈は大変でした。
チーム内での議論を重ねた他、分析チームでは社外のコンサルの方と契約をしているため、その助けも借りつつ効果的な方法を実践することができました。
また分析チームや近いメンバーではLTVの概念を理解しているものの、営業などには浸透しきっていない部分もあります。引き続きLTVを指標とした分析を行い、その有用性を伝えることで目線を揃えていきたいです。
プロダクトチームへの施策提案
プロダクト全体の分析を2〜3か月行った結果、さまざまな傾向や課題感・さらに伸ばせそうな箇所が見えてきました。
次はそれらの考察を元に、プロダクトチーム (主に新機能の開発や仮説検証を担当するチーム) への施策提案を行いました。これらの準備・提案からその後の動きを決める種々の会議まで、こちらも2か月ほどの期間をかけました。
やったこと
以下の2種類の施策を提案しました。
- ユーザーによってある程度行動パターンが固定されることがわかったため、初期のアクション傾向を元にその後のレコメンドを行う
- 何度も案件を見て比較しているユーザーが多いことがわかったため、閲覧履歴を元にリアルタイムでのターゲティングを行う
1点目について、レコメンド機能自体はすでにAppDriverの機能として存在していました。しかしそこではブラックボックスな機械学習モデルを用いており、その案件がレコメンドされた理由などが明示できないものでした。
今回はユーザーのペルソナに基づきストーリー立ててレコメンドを行うため、UI/UX観点での工夫も見込めそうなものになりました。
2点目については、現状ではリアルタイムの処理は行っていないため新規での提案でした。
よかったこと
いずれもただ闇雲に性能のいいブラックボックスモデルを使うのではなく、ストーリー立てた提案を行うことで、プロダクトチームの納得感を得ることができました。
また定量データを元にシミュレーションを行うことで、施策開発による価値や優先度の判断にも役立てることができました。
図はストーリーの可視化やシミュレーションの一例です。
1枚目はユーザーの行動パターンをいくつかの「状態」とその間の「遷移確率」に分解し、遷移確率を図示したイメージです。
2枚目は提案に当たってある閾値を決めるために、「その施策でカバーできるユーザーの割合」を確認しているものです。
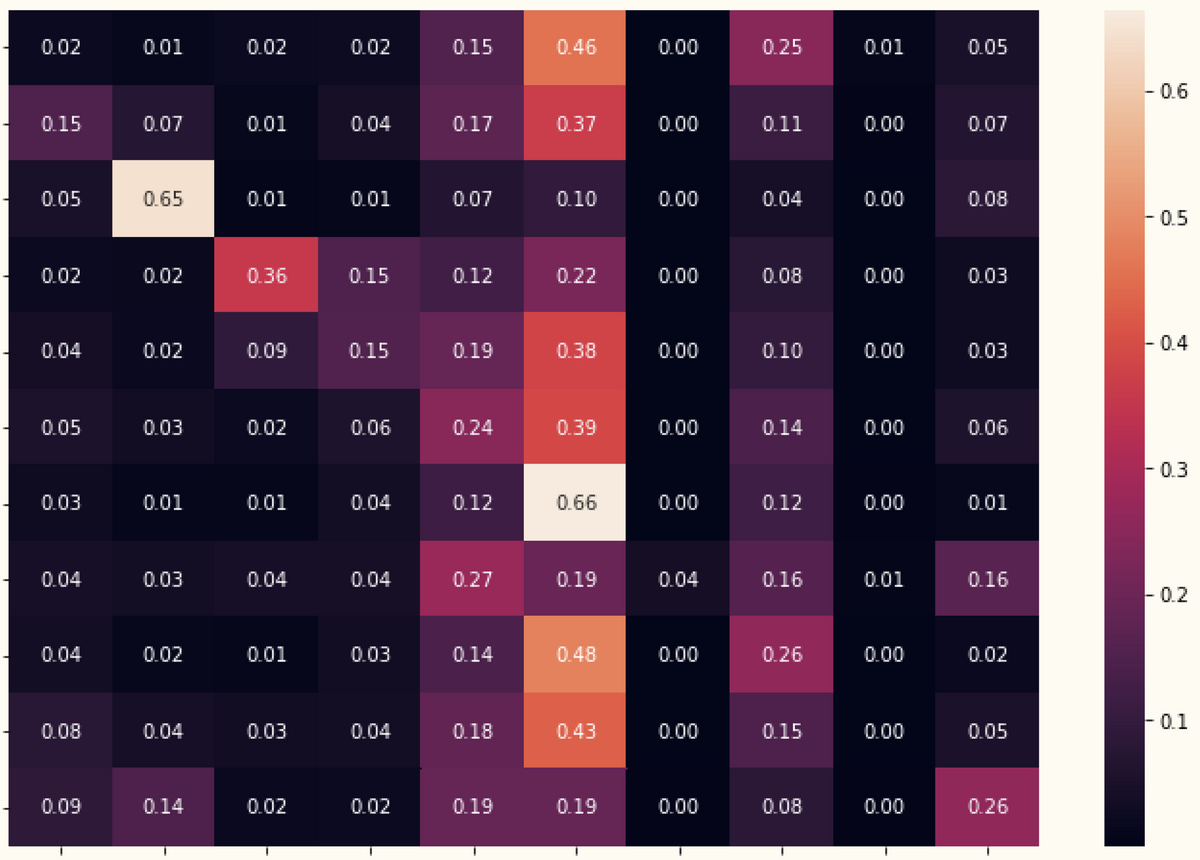
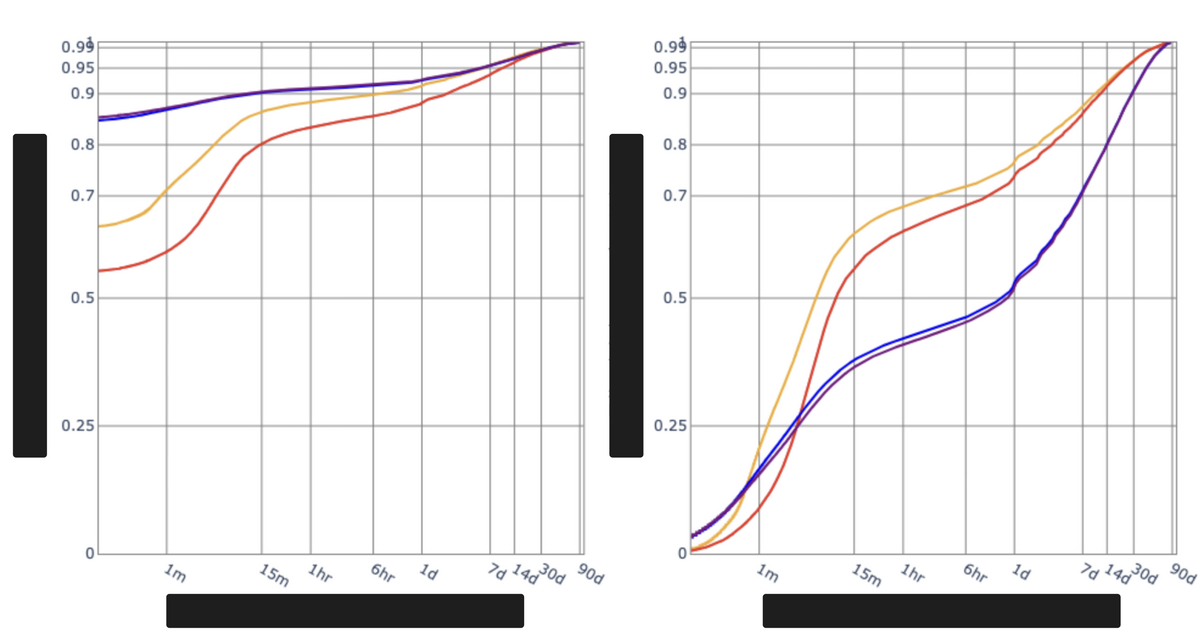
個人的にはこういった提案や、関係者を巻き込んで決定をリードしていく動きは初めてだったので、大変だったもののいい経験になりました。
データサイエンティストに必要な要素として「データサイエンス」「データエンジニアリング」「ビジネス」の3つがあるとはよく言われます。今回「ビジネス力」を強めていくための第一歩にはなったのかなと思います。
難しかったこと
個別の考察はいろいろ見つかったものの、ストーリー立てて提案まで持っていけたものは2つに留まってしまいました。
またある程度考慮はしていたものの、いずれの提案もある程度の工数をかけて開発をする必要があり、優先度が上がりにくくなってしまいました。
プロダクトの状況が2〜3か月単位で変化していく中、必要な新機能の開発や、UI変更など1週間程度でできる仮説検証が優先となってしまい、今回の提案内容に関しては実装・検証まで行うことができませんでした。
分析チームとして独立した動き
年明けにアドプラットフォーム事業部がADWAYS DEEEとして分社化されたこともあり、方針の巻き直しなど含めて状況が流動的となったため、分析チームは独立して価値を出せるような動きに集中することになりました。
ChatGPTなど生成AIも盛り上がっていた時期で、それの検証などもやりつつ、AppDriverの改善を進めました。
レコメンドの改善
AppDriverには複数のレコメンド機能が搭載されていますが、いずれも数年間運用されているものです。そのためモデルの経年劣化や、検証用の機能が残ったまま手動管理している部分の運用工数が大きくなっていました。
現状の課題感などを営業へのヒアリングで把握しつつ、営業戦略の実態に合わせた形にモデルを修正しました。運用コストが改善されただけでなく、営業が感覚でやっていた戦略をモデル上で再現することで、売上も向上させることができました。
実施に当たっては、さまざまな課題や改善案を図のような2次元マトリックスに落とし込み、優先度の判断を行いました。
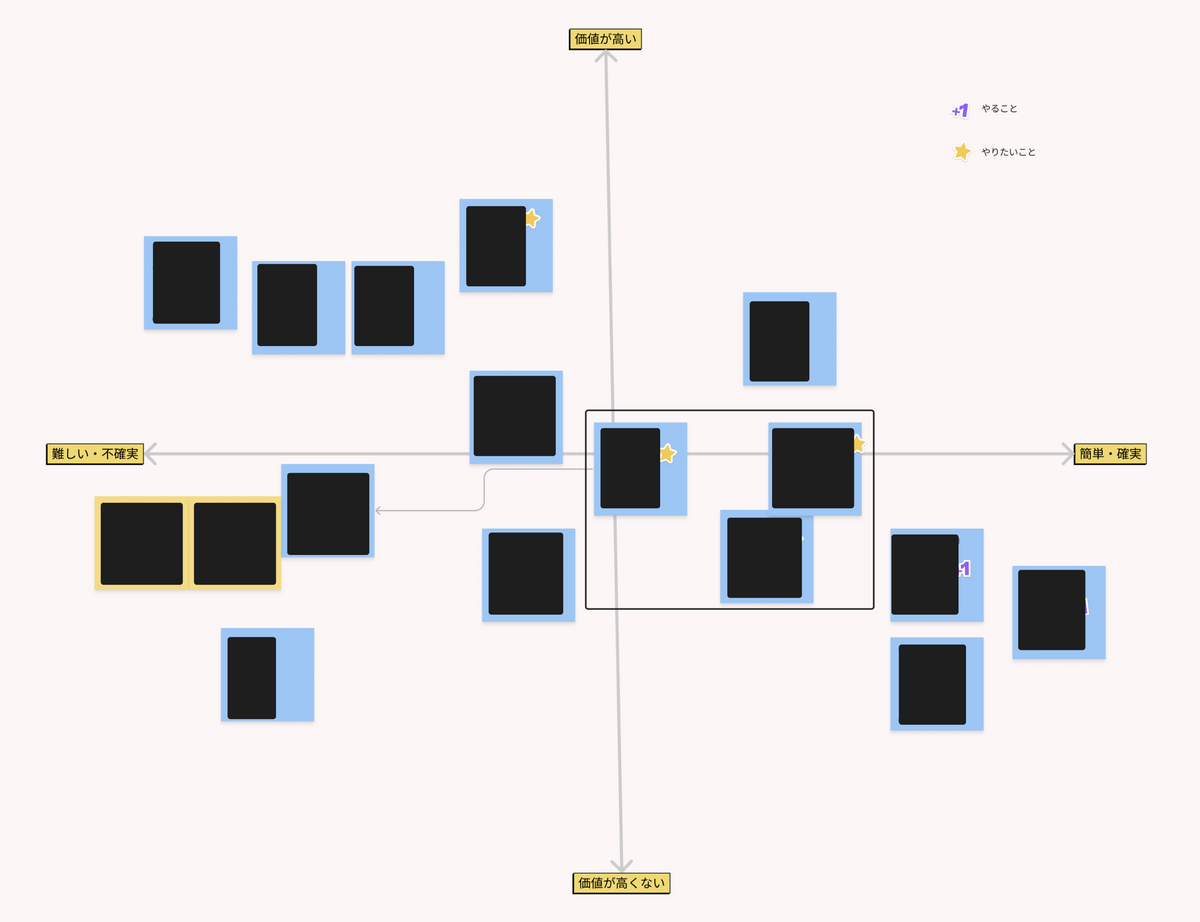
クライアントデータの分析
これまではメディア側へ向き合った分析や仮説検証が多かったですが、一方でクライアント向き合いでの分析をする重要性も上がっていました。
いろいろな施策や提案をする上でもまずは案件在庫を確保することが必要ではあるものの、これまであまり在庫の確保・拡充に向けた分析にはリソースを割けていない状態でした。
ここをしっかり分析し提案や最適化などに繋げていくことで、AppDriverとして強みになると考えました。
AppDriverでは特にこの時期までにCPE案件のマルチリワード (ゲームアプリなどで複数のリワード成果地点を設定することで、ユーザーを深いところまで段階的に誘導する方式) が実装されたこともあり、クライアント営業側でも成果地点の設計や運用などが課題になっていました。
そこでどのような成果地点を設定すればクライアントKPIであるROASを担保しながら、AppDriverとして売上を伸ばしていけるかを模索しました。
完全に新しい動きだったため、手探りでの分析となり大変でした。特に以下のような点で苦労しました。
- 関わるステークホルダーが今までと異なるため、関係値を作るところから始める必要がある
- データ分析環境も整備されていないため、データ取り込みや前処理などの準備も一からしないといけない
- 担保すべき指標がクライアントROASとAppDriverの売上の2種類あり、何が課題で目的なのか、ヒアリングをしてしっかり定義することで分析の軸を決める必要がある
チーム内やステークホルダーとの議論を重ねて分析を進め、いくつかデータから得られた考察を元に、ROAS改善の提案を営業担当へ行うことができました。
プロダクトチームへのジョイン
直近はプロダクトチームへジョインし、一緒に仮説検証を進めています。現在進行中の検証ということで具体的な中身は書けませんが、チームと一緒に動くことで得られた学びを紹介します。
よかったこと
メンバー間の距離が近くなったのでPdM・デザイナー・エンジニアとデータサイエンティストの間で情報共有がリアルタイムで行われるようになり、分析のスピード感も大きく向上しました。
KPIの設定や仮説検証計画の策定からデータサイエンティストが関わることで、結果に説得力をもたせる部分でもある程度貢献できたのではと思います。
仮説検証なので当然うまくいかないことの方が多いですが、その場合でも得られた定量データを元に根拠を持って改善策を提示することで、社内のステークホルダーだけでなく、関係するメディアの信頼感も得られたのではと思っています。
難しかったこと
新規の機能開発を進めているため、開発が終わって実際にサービスインするまでデータが存在しないことが多く、大まかなシミュレーション以上のことができない場面が多かったです。
できる範囲で妥当な考察を出しつつ、あまり深入りしないというバランス感を掴むのが難しかったです。
またチームに様々なロールが集まっているため、仮説検証のフェーズによっては忙しいロールが偏ることがありました。
他のチームではデータサイエンティストがいないところもあるので、こういう時期はそちらの分析も並行して対応しています。
まとめ
データサイエンティストのここ1年強における動き方を紹介しました。組織やチームにおける分析業務の状況や、その中で私が学んだこと・苦労したことなどイメージが伝われば幸いです。
今後もデータ分析の重要性はますます増していくので、個人的にはこれまでの経験を活かしさらに有意義な分析結果を出していければと思います。またデータサイエンティストは常に不足しているので、ぜひ応募もお待ちしております!