こんにちは、三谷です。
普段は運用型広告向けプロダクト開発チームでエンジニアリングマネージャーをしています。
今回は機械学習初学者である私が AutoGluon を利用して未来予測した話を紹介したいと思います。
本記事の対象者と目的
記事を通して「機械学習に興味があるけど二の足を踏んでいる」ような方が「触ってみよう!」と思えるきっかけになれば幸いです。
今回は機械学習の学術的な話や細かいチューニングテクニックはありませんのでご容赦ください。
背景 〜ビジネス課題〜
イメージをしやすいよう機械学習を利用した背景を簡単に説明します。
私の関わっている運用型広告では配信実績等の膨大なデータが存在しています。このデータをうまく活用して少し先の未来を予測することができれば、運用判断の精度を高めることができるのではという思いから機械学習の利用を開始しました。
利用ツール: AutoGluon について
今回は AutoGluon という AutoML ツールキットを利用し表データの回帰分析を行いました。
AutoGluon は公式の説明にもあるように初心者にも利用可能な AutoML ツールであり、下のような数行のコードでモデルのトレーニング〜予測を実行することができます。
from autogluon.tabular import TabularPredictor predictor = TabularPredictor(label=COLUMN_NAME).fit(train_data=TRAIN_DATA.csv) predictions = predictor.predict(TEST_DATA.csv)
めっちゃ簡単ですね!!
実行環境があれば自分で用意するのはコード中の TRAIN_DATA.csv TEST_DATA.csv にあたる学習データと予測したいデータだけです。
また、利用するにあたっては presets というパラメータを与えて精度・コストの優先度を指定することができます。
AutoGluon の詳細については公式の情報や@ITさんに詳しい記事がありますので御覧ください。
検証のステップ
検証のステップは下図の通りです。学習データの作成〜結果の評価を繰り返し実施しています。
AutoGluon の項目でも触れましたが用意するのはデータセットだけなので、結果の善し悪しは学習データの特徴量の作り方に左右されます。
この検証サイクルを繰り返し実施することで、精度の高い良質なモデルを作成することができます。
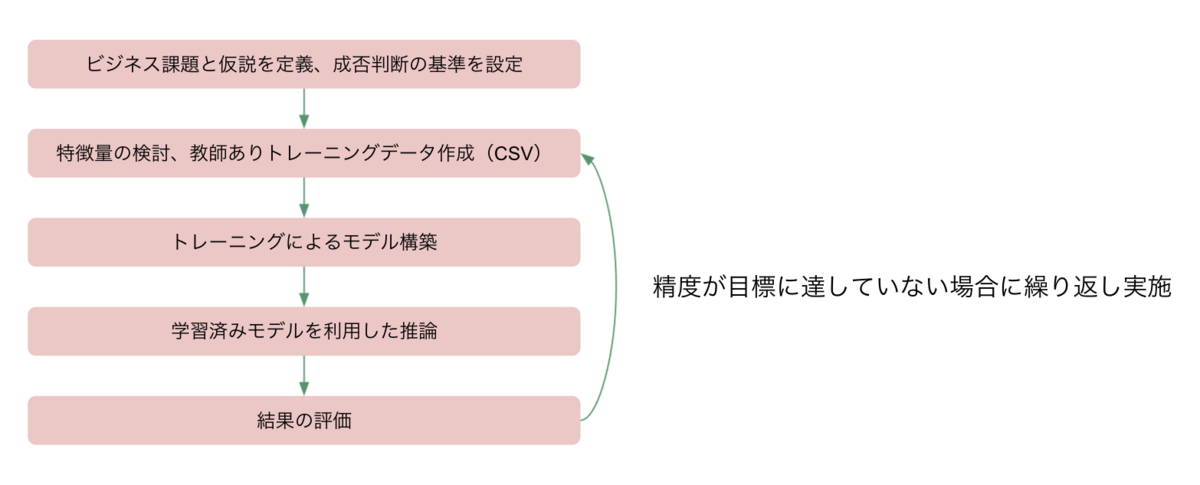
ここからは各ステップの詳細を説明していきます。
ビジネス課題と仮説を定義、成否判断の基準を設定
最初に機械学習を使って「なに」を解決したいかを定義し、それが機械学習で解決することが相応しいものかを判断します。
今回の課題は、運用型広告における各種設定やレポート情報(表データ)をから少し先の未来を回帰分析で予測することと定義しました。
成否を判断するための基準としては「概ね誤差が10%以内」であれば成功とし、判断する基準としてはデータと予測結果をBIツールで目視確認することに加えて「WMAPE *1」という精度評価指標を採用しました。
ただし、検証前はどの程度の精度がでるかも不明だったため暫定で設定し、検証サイクルを回す中で決定しています。
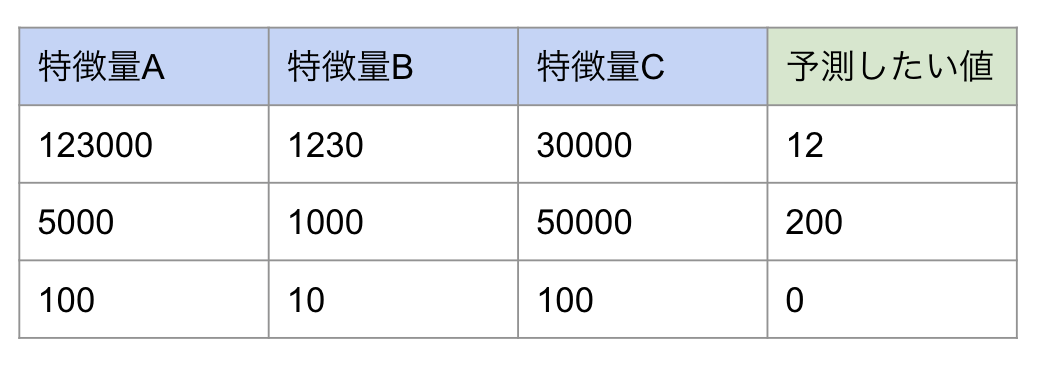
特徴量の検討、教師ありトレーニングデータ作成(CSV)
予測したい値(教師データ)とその要因と考えられる値を含むデータを作成します。
最初は少しでも結果に影響を与えそうなデータを集めてモデルを作成します。
望むような精度が得られなかったので、悪影響を与えているであろうデータの削除や新たな要因データを追加してモデルを再作成しました。
また、複数の要因で形成されている値は分解して最小粒度で持たせるようにしています。(ex. CTR → Click と Impression に分解)
このようにトレーニングを繰り返し、精度の高いモデルを得られるような特徴量を作成していきます。
トレーニングによるモデル構築
学習データが用意できたら TabularPredictor().fit() でトレーニングします。
前述の通り学習データに加え presets パラメータを設定しますが、今回は high_quality_fast_inference_only_refit を採用しました。採用理由は、「モデルサイズが適当」「推論精度が best_quality と遜色ない」ことです。これはモデルの特性によって変わる部分なので検証して最適な presets を選択されることをお勧めします。

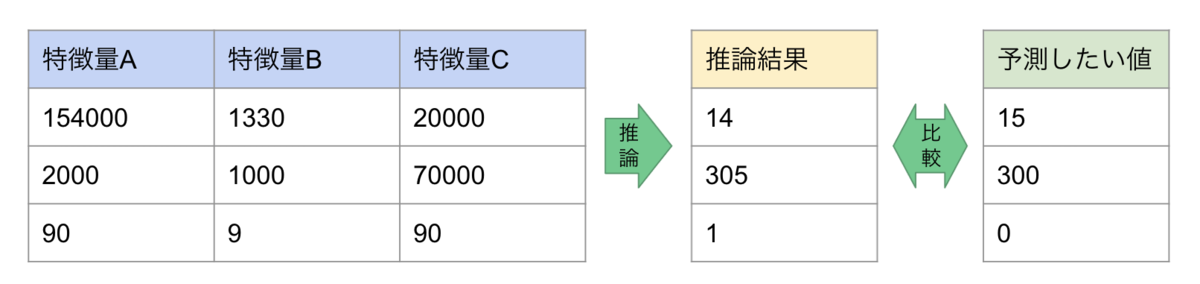
学習済みモデルを利用した推論
トレーニングが完了したらお待ちかねの推論です。
検証フェーズにおいてはモデルの精度を確認する必要があるため、学習データより未来のテストデータを用意します。(ex. 学習データ: 2021年6〜9月, テストデータ: 2021年10月)
精度評価指標やBIツールの目視確認をするため、テストデータも教師ありデータとして作成しています。
結果の評価
前述の通り、精度評価指標とBIツールからの目視確認で行います。
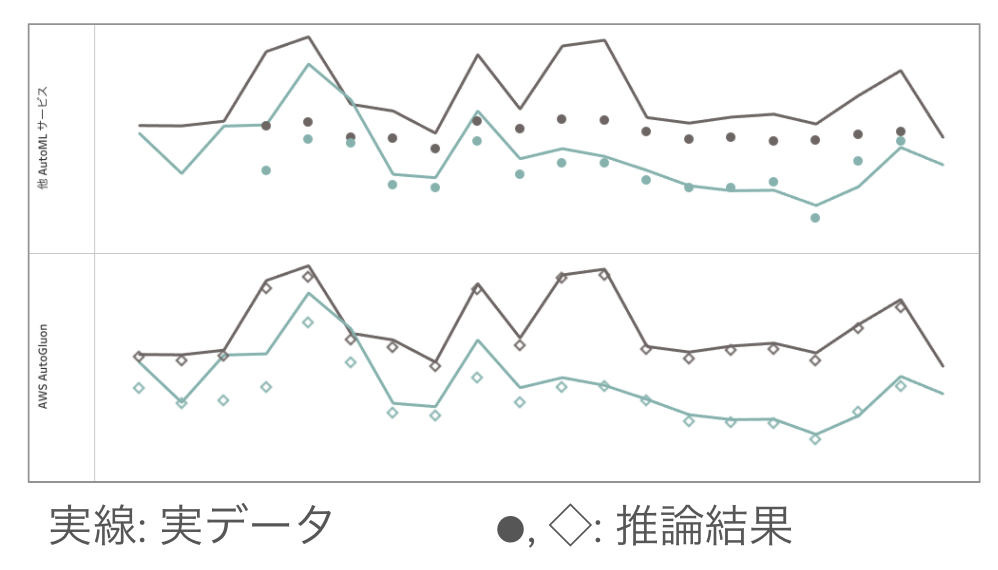
次の図は実際のデータを使い他のAutoMLサービスと比較した検証結果を一部抜粋したものです。
精度評価指標では他のAutoMLサービスと比較しても良い結果となりました。

BIツールから実際のユースケースを想定した目視確認でも許容できる誤差に収まっています。
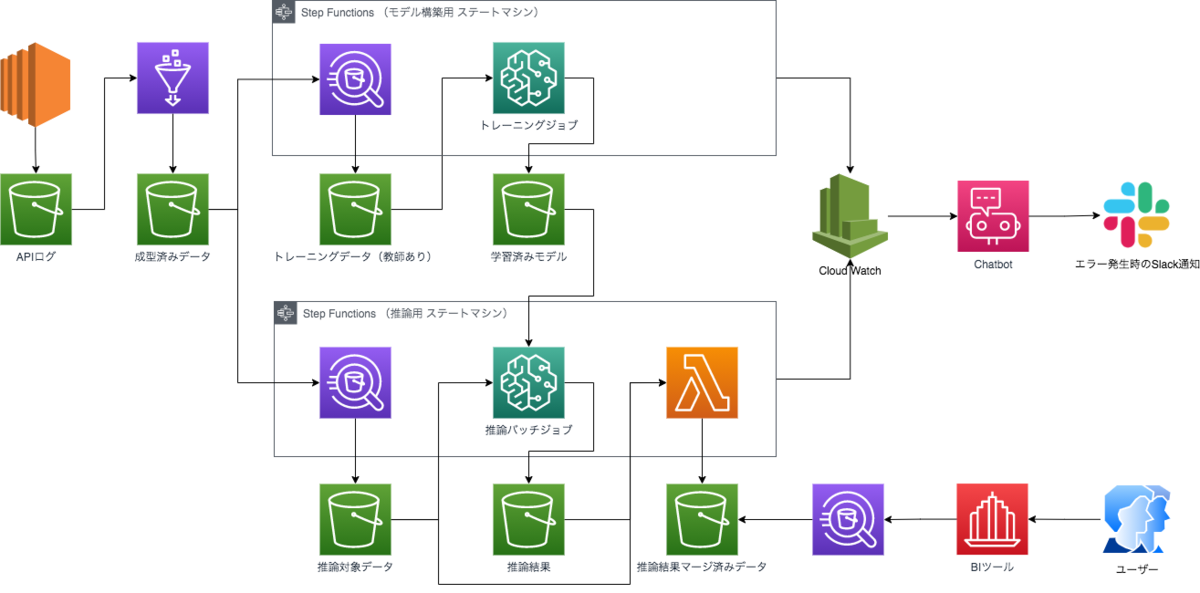
運用のアーキテクチャ
検証サイクルを回すことで精度の高いモデルを作成することができました。
このモデルを実際に運用するため AWS を利用したアーキテクチャ*2を参考までに記載します。
検証サイクルを回すだけであればローカル環境でも実現可能ですが、本番運用を見据えるのであればデータパイプラインを作ることで検証サイクルを回す手間が大幅に削減されるのでお勧めです。
まとめ
- AutoGluon 等の AutoML を利用すれば機械学習で必要な知識を部分的に吸収してくれる
- 仮説をもとにデータセットさえ作れれば誰でも簡単に予測することができる
- 初学者が取り組んでも成果が出しやすい!
- 一方で AutoML が吸収してくれないことも...
- ビジネス的な課題や仮説は明確にする必要がある
- 特徴量の作成は AutoML で吸収できない領域なので泥臭く素早く繰り返し検証いくことが重要
- 言い換えると AutoML を利用することで特徴量の作成に集中することができる!
今回は AutoGluon を利用した回帰分析で未来を予測した経験を紹介しました。 繰り返しになりますがデータセットさえあれば複雑なコードや深い知見がなくとも機械学習を体験することができます。以前の私も感じていましたが「難しそう」「なにから手をつけたらいいのかわからない」と悩んでいるようでしたら、このような AutoML ツールを利用してまずは体験してみるのも良いのではないでしょうか。
*1:WMAPE(荷重絶対値平均誤差率): 数値の大きいサンプルデータの誤差に重みを付けた指標。ビジネス観点で数値の大きいデータが重要になるために採用した。
*2:Amazon SageMaker 上で AutoGluon を動かすためのサンプル, オフィシャルコンテナ利用版