こんにちは! アドテクノロジーDivの安藤です。
以前はTerraformの記事を書かせて頂きました、2021年はロジックや機械学習を使って売り上げ最大化を目指し、チームで日々奮闘しております。
今回は機械学習の前処理で使われる数値データのスケーリングについて、触れたいと思います。
はじめに
モデルを作る上で外れ値の扱いをどうするかを決める必要があります。
外れ値を除外して学習する、外れ値を含めて別の値に変換を行い学習する、などがあると思います。
最近、業務で複数の数値スケーリングを試し、モデルの結果を比較しました。外れ値に限定するわけではないですが、値の範囲がどのように変化するか、それぞれの手法を比較しながら見ていこうと思います。
数値データのスケーリングとは
オリジナルの数値データはしばしば、外れ値があったり、特徴量同士で単位などが異なる場合があります、そのような場合にスケーリングを使って学習すると変換前のデータでの学習よりスコアがよくなったりします。例えば、0 ~ 10000の数値データを0.0 ~ 1.0の範囲に変換すると、学習結果が変わり、有効な特徴量となる場合があります。
なぜやろうと思ったか
業務でユーザーの履歴を元にクリックやアクションなどの特徴量を使い、案件の抽出を機械学習で試行錯誤しました。
その中で高単価案件もしくは低単価の案件に偏るなどの課題があり、数値データに対してスケーリングを行うことで比較的良質な案件を抽出できるのではないかと思い、検証しました。
今回は実務データは使いませんが、数値の範囲が変わることを分布図を見ながら説明していきます。
データセット
Inside Airbnbで公開されている、Airbnbのアムステルダムの宿泊施設のデータを使います。
今回は学習までしないため、以下のデータに絞ります。
- 宿泊費用
- 一月当たりのレビュー数(平均 or 中央値)
検証
変換前の素の状態を比較対象に、それぞれ値の範囲を比較します。
変換対象のカラムはprice(宿泊費用)とし、現状のデータの分布を出力しました。
スケーリングしない素の状態
縦軸は一月あたり月のレビュー数、横軸が宿泊費用となり、単位は$です。(object型で$表記だったため、float64に変換しています。)
宿泊費用0もありますが、今回は無視します。中央値も確認します。
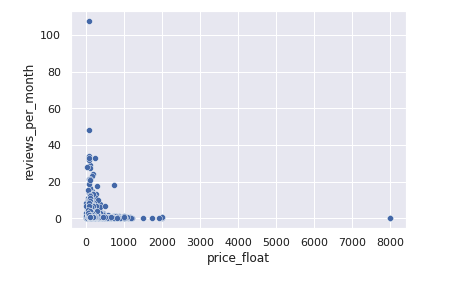
0~8000の範囲を取り、中央値は130.00。 中央値と最大値が大分離れていますね。
またreviews_per_monthとprice_floatが取る値の範囲は異なりますね、このカラムも一緒にスケールして値の範囲を揃えていきます。
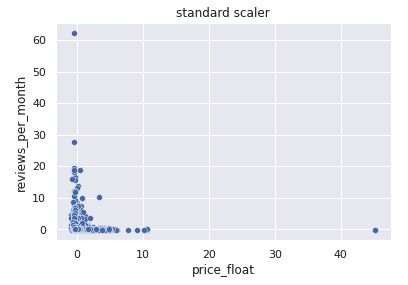
標準化
中央値: -0.155, 最大値: 45.22
平均を0、分散を1とするため、マイナスの範囲も取ります。 オリジナルの状態から取りうる値の範囲が変わったのが分かります。
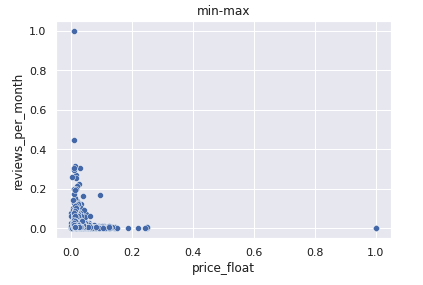
Min-Max
0~1の範囲をとり、最小値や中央値と最大値が離れているほど、数値の範囲が狭まってしまいます。
今回の場合だと、最小値: 0 ~ 最大値8000ですが、散布図を見ると0~0.2の範囲がほとんどになっているのが分かります。
仮に8000を除外した場合、0~0.2の数字がより広い範囲に散らばると想定されます。
これらの特徴から、Min-Maxは最小と最大が決まったものが良いと言われています。(ex: RGB)
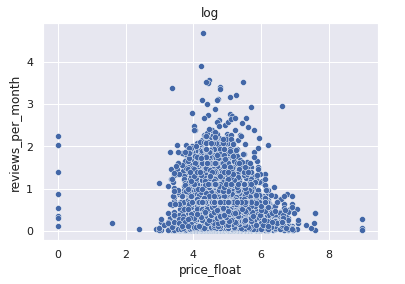
対数変換(log)
中央値: 4.87, 最大値: 8.98
素の状態の分布と大分変わりました。中央値と最大値の範囲が縮小されました。
スケールの差が大きいものは対数変換すると効果があるかもしれません、特に外れ値を学習に取り込みたい場合はやってみる価値はあるかと思います。
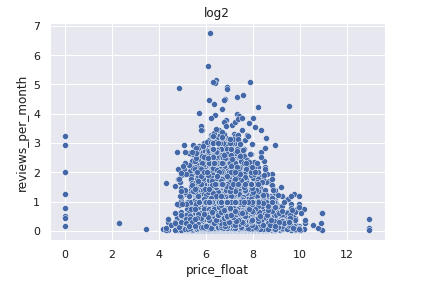
対数変換(log2)
中央値: 7.03, 最大値: 12.9
同じ対数変換ですが、底が2となり、logよりも広い範囲を取ります。
どちらを使えばいいかは、実際にやってみてオフラインスコアやシミュレーションが良い方を選択した方が良いかと思います。
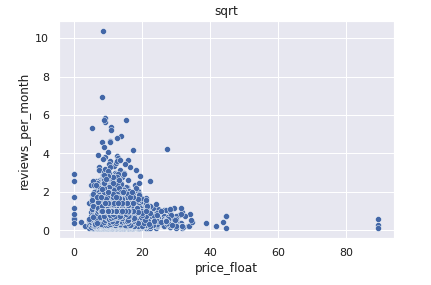
平方根
最後に平方根です。
中央値: 11.40, 最大値: 89.44
素の状態の分布図から値の範囲は狭まり、標準化よりも偏りが緩和されているように見えます。
やってみて
それぞれ、数値の範囲が変わったことは伝わったかと思います。
では、実際にスケーリングを前処理で行い、学習した結果を軽く共有します。
ユーザーの行動履歴からオススメの案件を抽出する回帰モデルを作り、いくつかスケーリングを試しました。
特徴量(一部)
- ユーザーごとの一定期間内の
- 案件詳細ページのインプレッション
- クリック
- コンバージョン
- 広告単価など
シミュレーションを行い、表示される案件を集計したところ、以下の結果が得られました。
- オリジナル(スケーリングなし): 単価の高い案件に偏る。
- log,log2: 単価の低い案件に偏る。
- 標準化: オリジナルと同様、高単価案件に偏る。
- 平方根: 高単価案件を抑えつつ、人気の案件を表示。
高単価案件の露出を抑えるためにlog,log2を試しましたが、おそらく低単価・高単価の差が縮まったことで、コンバージョンしやすい低単価の案件に偏ってしまったかなと思います。
平方根では、高単価の中でも比較的人気の案件が抽出でき、オリジナルの偏りを抑えることができました。
最後に
いかがでしたでしょうか、これらのサンプルコードは上げていませんがnumpyやscikit-learnに用意されていおり、手軽に試せます。
学習で試してみて、結果が変わることを確認してみて下さい。