エージェンシー事業でリードアプリケーションエンジニアを行なっている大窄 直樹 (おおさこ)です. AWSのログ, サーバーのログってたくさん種類があって難しいですよね... 同じようなログがたくさんあるので, 何を取れば良いのかとか どのくらいの期間保持すれば良いのかとか
またその後の, ログの実装や, 分析方法する方法も難しいですよね...
今回AWSに構築した商用アプリケーションのログを整備する機会があったので,
このことについて書こうかなと思います.
概要
このブログではログ設計/実装/分析を行なっていきます.
またここでいうログとは, AWS, OS, アプリケーションのログのことです.
法令に則って, 取得するログ, 保持期間などを設計し,
実装を行い, 分析できる状態にするところまでブログで書きます.
以下は今回の記事の要約です.
- ログの保管場所はS3
- サーバー内のログのS3転送には, fluentbitを採用
- ログの分析には, GuardDuty, Glue, Athenaを使用
- 保管するログ及び保持期間は下記
- CloudTrail (データイベント)は, S3のサーバーアクセスログで代替可能
| ログ名 | 保管期間 |
|---|---|
| AWS: CloudTrail (管理イベント) | 5年 |
| AWS: CloudTrail (データイベント) | 5年 |
| AWS: VPCフローログ | 1ヶ月 |
| AWS: ALBのアクセスログ | 1年 |
| AWS: NLBのアクセスログ | 1年 |
| OS: /var/log/messages | 5年 |
| OS: /var/log/secure | 5年 |
| APP: 監査ログ | 5年 |
| APP: アクセスログ | 5年 |
本題に入る前の準備
本題に入る前に, 前準備として今回ログを実装していくアーキテクチャの紹介や, ログに関する情報について記載していきます.
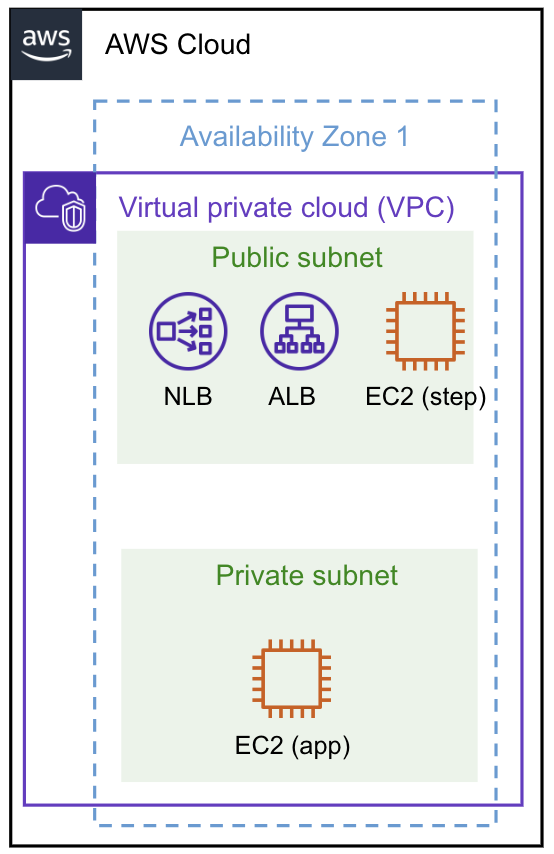
今回ログ実装するアーキテクチャ
今回, ログ実装していくアーキテクチャは下記に示します.
- 単一リージョン/単一AZ
- アクセス経路
- ALB
- NLB
- 踏み台サーバーからのssh
ログに関する法令
ログに関するは法令は多々あります. 下記はIPAが, 要約した資料を書き抜いたものです.
| 保存期間 | 法令・ガイドラインなど |
|---|---|
| 1ヶ月間 |
|
| 3ヶ月間 |
|
| 1年間 |
|
| 18ヶ月間 |
|
| 3年間 |
|
| 5年間 |
|
| 7年間 |
|
| 10年間 |
|
弊社では, 上記を参考に監査ログは最低5年, アクセスログは最低3ヶ月は取得することをルールづけています.
また, ここで言う監査ログとは, システムに対して実行した操作内容が時系列かつ連続的に記録されたものです.
監査ログを見ることで, いつ, 誰が, どのような操作をしたかを把握することができるようなログを指します.
アクセスログとは、システムに対してアクセスした内容が時系列かつ連続的に記録されたものです.
アクセスログを見ることで, いつ, 誰が, どこから, どのような接続元で, どのようにリクエストし, どのような処理になったかを把握するようなことができるようなログを指します.
ログの取得箇所
ログの取得は, 何らかの操作ができる箇所, アクセスを遮断する可能性がある箇所は取得する必要があります. 具体例を言うと下記のような箇所で取得を検討する必要があります.
- AWS (インフラ)
- WAF
- LB
- VPC (SG, ACL, etc.)
- RDS
- OS (※ここだけログ名)
- システムログ
- アクセスログ
- アプリケーション
- Apache, Nginx
- フレームワーク
- 商用アプリケーション
このように各箇所で取得する必要がある理由としては, 各層でログを取得しないとユーザーがどこまでアクセスして, どのような操作をしたのか追えないためです.
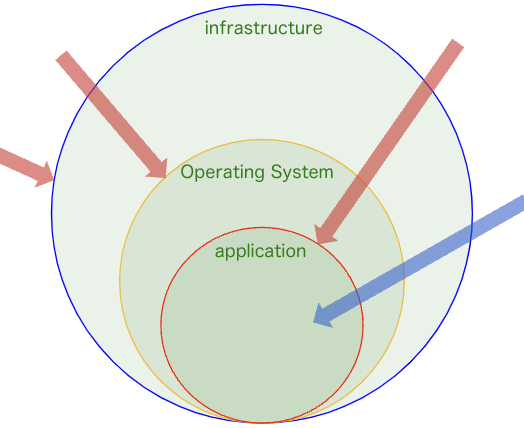
例えば, アプリケーションにアクセスしたいユーザーがいたとします.
下記図のように3層(インフラ, OS, アプリケーション)に大別したとすると, このユーザーのアクセスはインフラアクセス時, OSアクセス時, アプリケーションアクセス時の3箇所で失敗する可能性があります.
一つでもログが欠けていると, どこでこのユーザーがアクセスに失敗したか, どのような操作をしたかが不明瞭になります.
したがってログの取得は, 何らかの操作ができる箇所, アクセスを遮断する可能性がある箇所は取得する必要があります.
設計
ここからが本題です! この章では, AWS, OS, アプリケーションでどのようなログを取得するか, どのくらいの期間保管するかなどを設計していきます.
保管するログの決定
保管するログを決めていきます.
何らかの操作ができる箇所, アクセスを遮断する可能性がある箇所は取得する必要があります. まず初めに, 上記に則りアクセスを遮断する可能性がある箇所, 操作できる箇所を洗い出していきます.
今回もまた, インフラ, OS, アプリケーションの3層に大別して考えていきます.
インフラのログ
今回のケースでいうインフラとは, AWSサービスのことです.
AWSは操作ができる箇所なので, AWSの監査ログが必要です.
また, 多くのサービスでアクセス管理の仕組みがあるのでそこでもログが必要です.
今回の場合, アクセス管理の仕組みがあるサービスを下記に列挙します. (ログサービスを使う上でS3は必須のため追記してます.)
- AWS
- ALB
- NLB
- VPC
- S3
このそれぞれの箇所で, アクセスログが必要です.
上記に関連する, AWSのログサービス及び, 取得の有無を下記に列挙します.
AWSのログ
| ログ名 | 説明 | 取得の有無 |
|---|---|---|
| CloudTrail (管理イベント) | AWS アカウントのリソースで実行される管理オペレーションのログ (データ関連以外の監査ログ, AWSへのログイン失敗のようなログもある) | ○ |
| CloudTrail (データイベント) | AWS アカウントのリソースで実行されるデータオペレーションのログ (データ関連の監査ログ) | ○ |
| VPCフローログ | VPC のネットワークインターフェイスとの間で行き来する IP トラフィックに関するログ | ○ |
| ALBのアクセスログ | ALBに送信されるリクエストについての詳細情報をキャプチャしたアクセスログ | ○ |
| NLBのアクセスログ | NLBに送信されるリクエストについての詳細情報をキャプチャしたアクセスログ | ○ |
| S3のサーバーアクセスログ | バケットに対するリクエストの詳細が記録されたアクセスログ | × |
S3のサーバーアクセスログを取得しない理由は, CloudTrail (データイベント)で補えるためです.
ざっくりと下記のような違いがあります.
- 費用
- S3のサーバーアクセスログ < CloudTrail (データイベント)
- 情報量
- S3のサーバーアクセスログ > CloudTrail (データイベント)
一般的には, CloudTrail (データイベント) を取得せず, S3のサーバーアクセスログを取得します.
今回のログを整備するアプリケーションは, 社内用のアプリケーションでCloudTrail (データイベント)の費用が非常に安いことが想定できたため採用します.
非常に高価になりやすいサービスのため, 取得する際は費用に気をつけてください.
より詳細にデータの違いを知りたい場合は, 下記のClassmethodさんの記事を参考にしてください.
CloudTrail S3オブジェクトレベルログ、S3サーバーアクセスログ、どちらを使えば良いか?違いをまとめてみた
OSのログ
OSは, AmazonLinux2です.
先に, OSには1ファイルで完璧な監査ログ, アクセスログはないです.
したがって, 最低限このログは保管しようくらいで問題ないです.
今回はOSのログについて, 下記のシステムログを保管することにします.
| ログ名 | 説明 |
|---|---|
| /var/log/messages | システム全体の一般的な出力のログ (システムエラーメッセージ, 起動ログ, システム警告など) |
| /var/log/secure | 認証に関連するログ (sshログイン試行, sudoの使用など) |
(再度重要なことなので) /var/log/messages, /var/log/secureは重要なログですが, 完全な監査ログにはならないです.
完全な監査ログとするために, 他のログと組み合わせたり, 監査用のサービス(auditdなど)を用いてログを作成したりする必要があります.
アプリケーションのログ
今回のアプリケーションは, 商用のアプリケーションです.
したがって, 用意された監査ログ, アクセスログを保管します.
ログの保管
保管場所について
長期間のログを保管するおすすめの場所を, AWSのSAさんに相談して決めました.
SAさん曰く, おすすめは下記の2サービスです.
| サービス名 | 説明 | Pros. | Cons. |
|---|---|---|---|
| S3 |
|
|
|
| SIEM on Amazon OpenSearch Service |
|
|
|
ちなみにSIEM on Amazon OpenSearch Serviceは, 日本人が作ったサービスらしいです. 下記画像が, SIEM on Amazon OpenSearch Serviceを使ったCluoudTrailのログの可視化の例でとてもみやすくていいですね.
しかしながら, SIEMの サーバー費用がかかるのがあまり好みではなかったため, S3を採用しました.
保管期間について
弊社では, 法令に則り, 監査ログは最低5年, アクセスログは最低3ヶ月は取得することをルールづけています.
このルールに基づき, 保管期間を決めたのが下記です.
| ログ名 | 保管期間 |
|---|---|
| AWS: CloudTrail (管理イベント) | 5年 |
| AWS: CloudTrail (データイベント) | 5年 |
| AWS: VPCフローログ | 1ヶ月 |
| AWS: ALBのアクセスログ | 1年 |
| AWS: NLBのアクセスログ | 1年 |
| OS: /var/log/messages | 5年 |
| OS: /var/log/secure | 5年 |
| APP: 監査ログ | 5年 |
| APP: アクセスログ | 5年 |
ALB, NLBのアクセスログに関しては, 最低3ヶ月より長い, 1年取得することにしました.
"APP: アクセスログ"が5年の理由は, 商用アプリケーションのため何があるかわからないため5年と長めにしました.
VPCフローログは, アクセスログでも, 監査ログでもないので1ヶ月取得することにしました.
バケット構造
S3にデータを保管することに決定したので, バケットの構造パターンについて, またまたSAさんに相談しました.
しかし, ベスプラ的なものはなかったので助言だけいただきました.
- SAさんの助言
- ログの保持期間ごとには, 分けた方が良い (バケット単位でライフサイクル)
- ログごとにバケットを分けると管理しづらいのでおすすめしない
このような助言を受け, 下記のようなバケット構造にすることにしました.
- server-log (ライフサイクル5年)
- application
- 監査ログ
- アクセスログ
- os
- messages
- secure
- application
- cloudtrail-dataevent-log (5年)
- CloudTrail (データイベント)
- cloudtrail-kanri-event-log (5年)
- CloudTrail (管理イベント)
- vpc-log (ライフサイクル1ヶ月)
- VPCフローログ
- elb-log (ライフサイクル1年)
- ALBのアクセスログ
- NLBのアクセスログ
このような構成にした, 深い理由はないです.
AWSのSAさんの助言を満たしつつ, こんなもんかなーくらいで決定しました.
アプリケーション, OSのログの転送
サーバーからS3にログを送る方法がいくつかあります.
下記に今回転送する際に候補に上がった4パターンと考察を書いてます.
| 転送方法 | Pros. | Cons. |
|---|---|---|
| CW agentを用いて, CloudWatchに転送してからのS3転送 |
|
|
| aws cliを用いてのS3転送 |
|
|
| fluentdを用いてのS3転送 |
|
|
| fluentbitを用いてのS3転送 |
|
|
この結果から, fluentbitを用いて転送することに決めました.
実装
アプリケーション, OSのログをfluentbitを用いてS3にログ転送
fluentbitを用いてS3にログ転送していこうと思います.
1. fluentbitのインストール
Amazon Linuxへのインストールドキュメントはこちらです.
下記のようにパッケージの追加します.
- /etc/yum.repos.d/fluent-bit.repo
[fluent-bit] name = Fluent Bit baseurl = https://packages.fluentbit.io/amazonlinux/2/ gpgcheck=1 gpgkey=https://packages.fluentbit.io/fluentbit.key enabled=1
下記のコマンドでfluentbitをインストールします.
sudo yum install fluent-bit
2. fluentbitの設定
書き方は下記ドキュメントに記載があります.
下記のようにfluentbitの設定ファイルに追記します.
- /etc/fluent-bit/fluent-bit.conf
[INPUT]
name tail
tag os-messages
path /var/log/messages
[INPUT]
name tail
tag os-secure
path /var/log/secure
[INPUT]
name tail
tag application-{$アクセスログ}
path ---------
[INPUT]
name tail
tag application-{監査ログ}
path ---------
[OUTPUT]
Name s3
Match *
bucket server-log <- 変更してね
region ap-northeast-1
total_file_size 1M
compression gzip
s3_key_format /$TAG[0]/$TAG[1]/%Y/%m/%d/$UUID.gz
s3_key_format_tag_delimiters .-
log_key log
"s3_key_format /$TAG[0]/$TAG[1]/%Y/%m/%d/$UUID.gz" AWSの他サービスのログフォーマットと, 同じ形になるように設定してます. また, "log_key log" をして生データを送っている理由は, そう設定しないとAthenaのLinuxのgrokパターンのサポート外になるためです. ただ, これを行うとfluentbitの転送した時刻がとれなくなります. もし, fluentbitの転送時刻が必要な場合この行を削除してみてください.
- fluentbitを起動してS3転送
下記のコマンドでfluentbitを起動及び, ステータス確認ができます.
systemctl start fluent-bit.service systemctl status fluent-bit.service
数時間もすれば, それぞれのログが下記のようにS3に保管されているはずです.
- server-log/os/messages/2023/10/18/t1nwYVDR.gz
これで, サーバー内のログの転送設定は完了です!
ALBのアクセスログの設定
ALBのアクセスログの設定をしていきます.
公式のドキュメントはこちらです.
1. バケットにポリシー追加
下記のように対象バケットにポリシーを追加します.
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::582318560864:root"
},
"Action": "s3:PutObject",
"Resource": [
"arn:aws:s3:::elb-log", <- ここら辺かえてね
"arn:aws:s3:::elb-log/*"
]
}
582318560864 は東京リージョンで, ALBが置かれているアカウントです.
自分のアカウントではないので注意してください.
2. アクセスログの設定
ALBのロードバランサーの属性の編集をしてください.
下記のように設定することでログを保管できます.
数時間もすれば, それぞれのログが下記のようにS3に保管されているはずです.
- elb-log/alb/AWSLogs/($アカウントID)/elasticloadbalancing/ap-northeast-1/2023/10/18/($ログ名).log.gz
これで, ALBのログの転送設定は完了です!
NLBのアクセスログの設定
NLBのアクセスログの設定をしていきます.
公式のドキュメントはこちらです.
先に注意!!!
アクセスログが作成されるのは, ロードバランサーに TLS リスナーがあり, TLS リクエストに関する情報のみを含む場合のみです.
したがって, TCPリスナーの場合ログは出力されないので注意してください.
それでは実装に戻ります.
1. バケットにポリシー追加
下記のように対象バケットにポリシーを追加します.
{
"Version": "2012-10-17",
"Id": "AWSLogDeliveryWrite",
"Statement": [
{
"Sid": "AWSLogDeliveryAclCheck",
"Effect": "Allow",
"Principal": {
"Service": "delivery.logs.amazonaws.com"
},
"Action": "s3:GetBucketAcl",
"Resource": "arn:aws:s3:::elb-log", <- ここら辺かえてね
"Condition": {
"StringEquals": {
"aws:SourceAccount": "--------" <- ここら辺かえてね
},
"ArnLike": {
"aws:SourceArn": "arn:aws:logs:ap-northeast-1:-----:*" <- ここら辺かえてね
}
}
},
{
"Sid": "AWSLogDeliveryWrite",
"Effect": "Allow",
"Principal": {
"Service": "delivery.logs.amazonaws.com"
},
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::elb-log/*", <- ここら辺かえてね
"Condition": {
"StringEquals": {
"aws:SourceAccount": "---------", <- ここら辺かえてね
"s3:x-amz-acl": "bucket-owner-full-control"
},
"ArnLike": {
"aws:SourceArn": "arn:aws:logs:ap-northeast-1:-------:*" <- ここら辺かえてね
}
}
}
]
}
delivery.logs.amazonaws.comはAWSのログサービスです.
NLB含むいくつかのサービスのログを取り扱っています.
2. アクセスログの設定
NLBのロードバランサーの属性の編集をしてください.
下記のように設定することでログを保管できます.
数時間もすれば, それぞれのログが下記のようにS3に保管されているはずです.
- elb-log/nlb/AWSLogs/($アカウントID)/elasticloadbalancing/ap-northeast-1/2023/10/18/($ログ名).log.gz
これで, NLBのログの転送設定は完了です!
VPCのアクセスログの設定
VPCのアクセスログの設定をしていきます.
公式のドキュメントはこちらです.
1. バケットにポリシー追加
VPCフローログは自動でバケットにポリシーを追加してくれます.
そのため, 手動での追加は必要ないです.
VPCフローログもまた, delivery.logs.amazonaws.com を用いていたサービスなのでNLB時同様のポリシーが追加されているはずです.
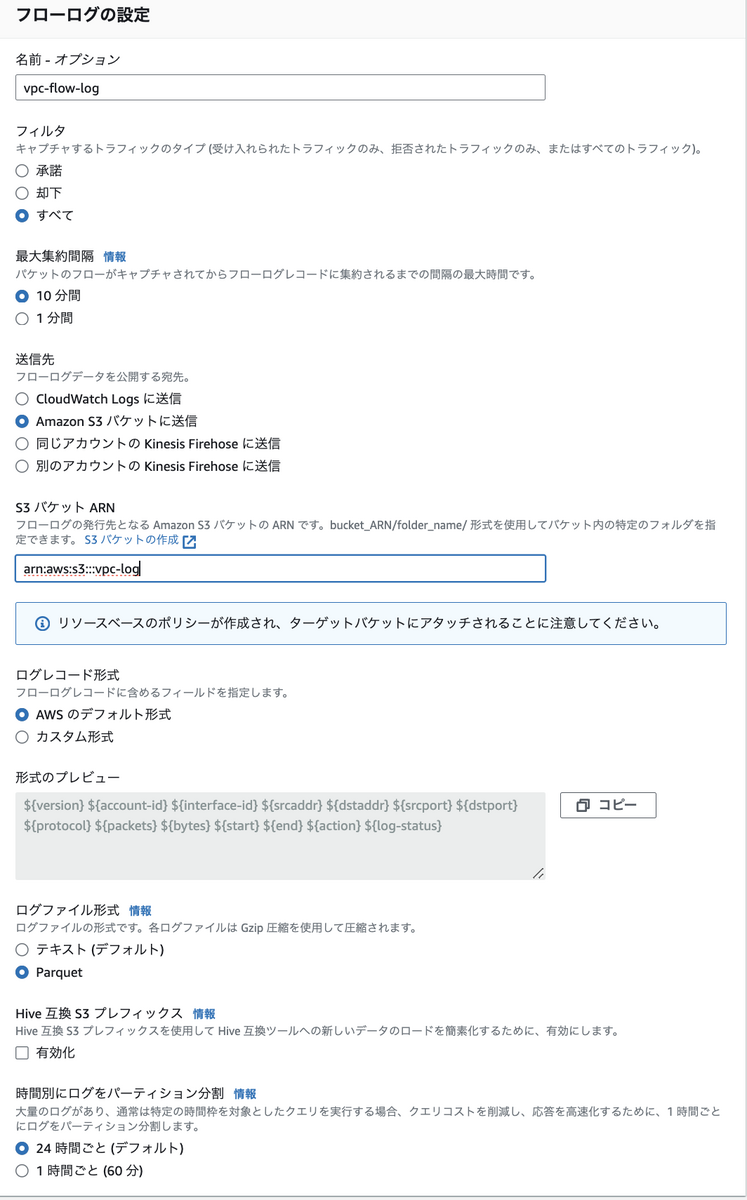
2. フローログの設定
VPCのフローログ作成を作成します.
例として, 下記のように設定することでログを保管できます.
VPCフローログの設定は, 好みが分かれる設定項目が多いのであくまで参考でお願いします.
数時間もすれば, それぞれのログが下記のようにS3に保管されているはずです.
- vpc-log/AWSLogs/($アカウントID)/vpcflowlogs/ap-northeast-1/2023/10/18/($ログ名).log.parquet
これで, VPCフローログの転送設定は完了です!
CloudTrailの設定
VPCのアクセスログの設定をしていきます.
公式のドキュメントはこちらです.
再度注意, CloudTrailのデータイベントはコストが高くなりがちです.
S3へのアクセスが頻繁な場合は管理イベントだけにしましょう.
S3へのアクセスログが見たいなら, S3のサーバーアクセスログがおすすめです.
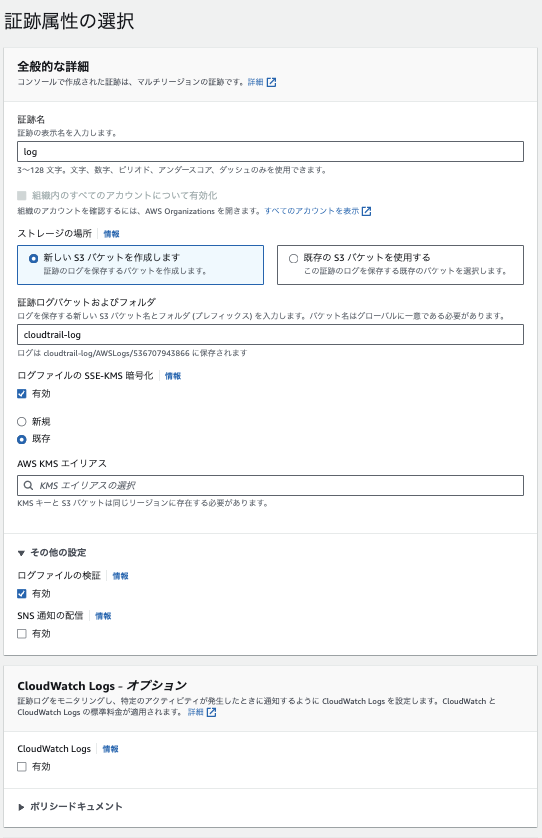
CloudTrailの証跡の作成をクリックして, 下記図のように設定します.
ログファイルの検証は良い機能なので有効にするのをお勧めします.
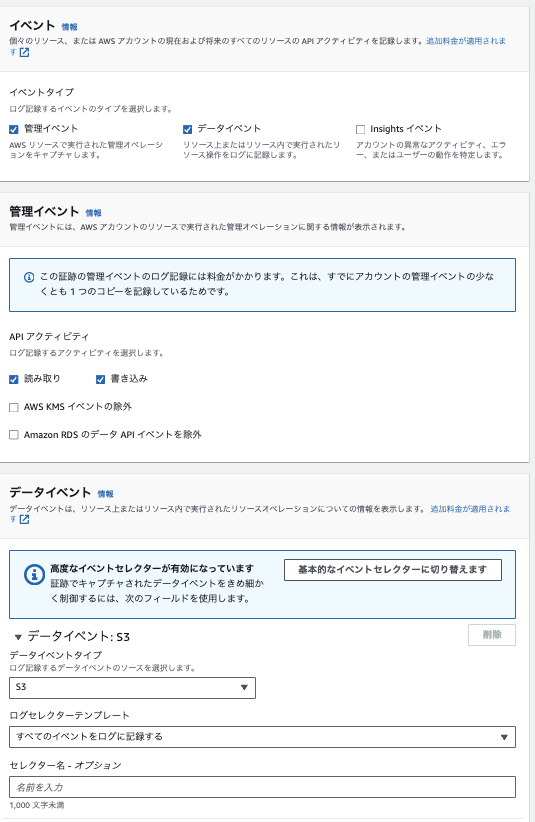
「次に」ボタンを押し下記図のように設定します.
これで設定完了です.
分析
この章では, GuardDutyを用いてのログ分析と, Athenaを用いてログを分析できる状態にすることを試みます.
GuardDutyを用いてのログ分析
GuardDutyの公式ドキュメントはコチラです.
GuardDutyとはフルマネージドな脅威検出サービスで, AWSのログを監視し,機械学習により検出します.
費用も安く, AWSを使うなら絶対に知っておくべきサービスです.
今回新たに取得したログの中では, 下記がサポート対象のログです.
- CloudTrail (管理イベント)
- CloudTrail (データイベント)
- VPCフローログ
また, 下記のログについては, 意図的に取得していなくても監視及び, 脅威検出を行ってくれます.
- DNSログ
- S3データイベント
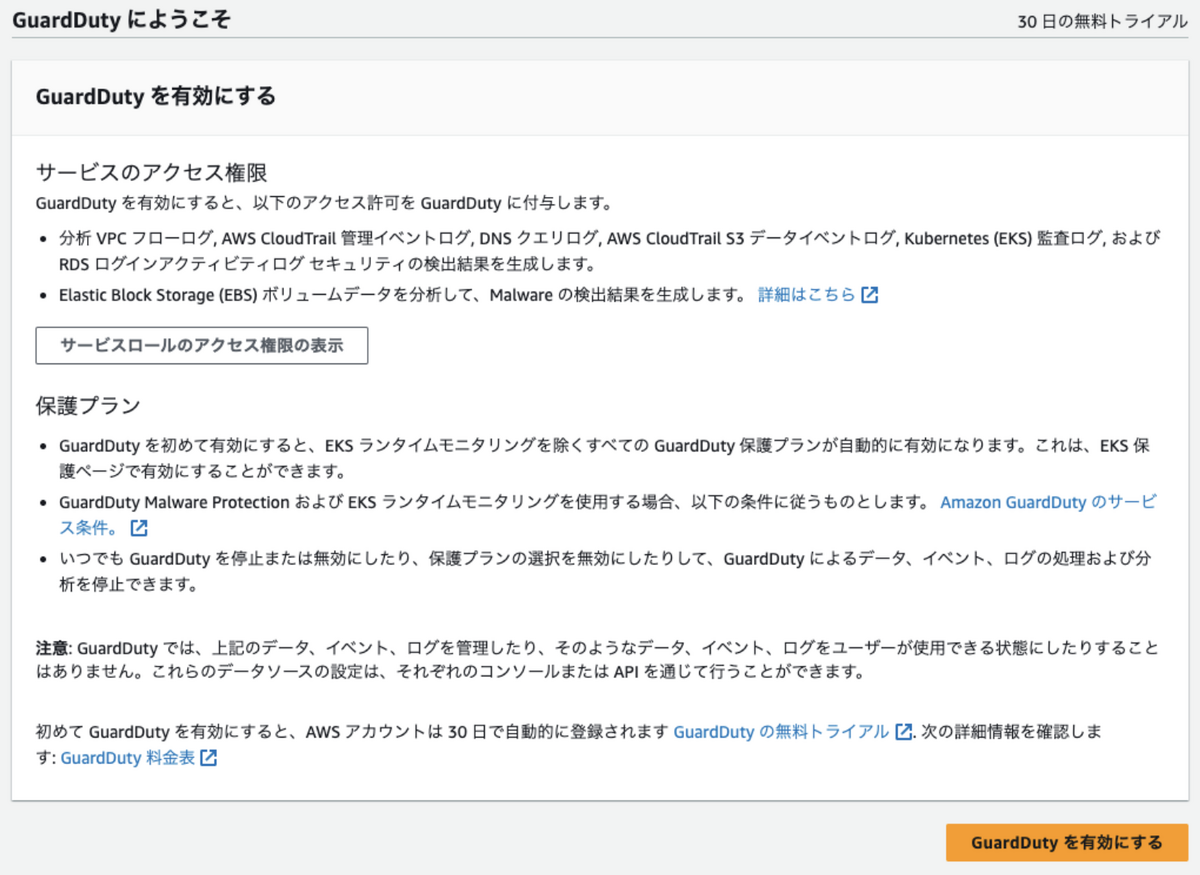
使い方はとても簡単で, GuardDutyにアクセスして有効化ボタンを押すだけです.
押すと自動で取得しているログを読みとってくれて, 脅威検出を行ってくれます.
日々自動でGuardDutyは脅威検出を行ってくれますが, 気付けないと意味がないので何かしらの通知する設定をするのをおすすめします. (毎日GuardDutyにアクセスするのは現実的ではないので)
Athenaを用いてログ分析できる状態に
Athenaの公式ドキュメントはコチラです.
Athenaは, S3のデータを参照してSQLを実行できるサービスです.
今回のAthenaの利用用途は, ログ分析できる状態にすることが目的のため
パーティション射影を使用したテーブルを作成しようと思います.
通常Athenaは, 新しいデータに対してSELECT文を実行するとき
パーティションの追加, 更新をしないと新規データを読み込ません.
この面倒な作業を, パーティション射影を行うと何もせずに新規データを読み込むことができます.
(デメリットとして, 他のサービスとAthenaを連携できなくなりますが)
アプリケーションのログのAthenaでの読み取りについては, 汎用的なことではないためここでは割愛させていただきます.
AWSのログのAthenaへの取り込み
AWSのログはAthenaで比較的分析しやすくするために, AWSがDDL及び, 分析方法を提示してくれています.
AWSが用意してくれているサービス一覧はコチラです.
その中の "Application Load Balancer" トピックに書かれている "パーティション射影を使用した Athena での ALB ログ用のテーブルの作成" のセクションが今回行うことです.
他のAWSサービスについても同様の手順でできるため割愛します.
1. データベースの作成
下記クエリでデータベースが作成できます.
CREATE DATABASE Logs;
2. テーブルの作成
下記クエリでテーブルが作成できます.
CREATE EXTERNAL TABLE `alb_logs`(
`type` string COMMENT '',
`time` string COMMENT '',
`elb` string COMMENT '',
`client_ip` string COMMENT '',
`client_port` int COMMENT '',
`target_ip` string COMMENT '',
`target_port` int COMMENT '',
`request_processing_time` double COMMENT '',
`target_processing_time` double COMMENT '',
`response_processing_time` double COMMENT '',
`elb_status_code` int COMMENT '',
`target_status_code` string COMMENT '',
`received_bytes` bigint COMMENT '',
`sent_bytes` bigint COMMENT '',
`request_verb` string COMMENT '',
`request_url` string COMMENT '',
`request_proto` string COMMENT '',
`user_agent` string COMMENT '',
`ssl_cipher` string COMMENT '',
`ssl_protocol` string COMMENT '',
`target_group_arn` string COMMENT '',
`trace_id` string COMMENT '',
`domain_name` string COMMENT '',
`chosen_cert_arn` string COMMENT '',
`matched_rule_priority` string COMMENT '',
`request_creation_time` string COMMENT '',
`actions_executed` string COMMENT '',
`redirect_url` string COMMENT '',
`lambda_error_reason` string COMMENT '',
`target_port_list` string COMMENT '',
`target_status_code_list` string COMMENT '',
`classification` string COMMENT '',
`classification_reason` string COMMENT '')
PARTITIONED BY (
`date` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'input.regex'='([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) (.*) (- |[^ ]*)\" \"([^\"]*)\" ([A-Z0-9-_]+) ([A-Za-z0-9.-]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" ([-.0-9]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^ ]*)\" \"([^s]+?)\" \"([^s]+)\" \"([^ ]*)\" \"([^ ]*)\"')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://elb-log/alb/AWSLogs/---------/elasticloadbalancing/ap-northeast-1' <----ここ変更してね
TBLPROPERTIES (
'projection.date.format'='yyyy/MM/dd',
'projection.date.interval'='1',
'projection.date.interval.unit'='DAYS',
'projection.date.range'='NOW-1MONTHS,NOW', <----ここで期間指定できるよ
'projection.date.type'='date',
'projection.enabled'='true',
'storage.location.template'='s3://elb-log/alb/AWSLogs/---------/elasticloadbalancing/ap-northeast-1/${date}', <----ここ変更してね
)
OSのログのAthenaへの取り込み
OSのログは, AWSのログのようにあらかじめ準備はされていないです.
そのため違う方法を検討する必要があります.
今回はGlueクローラの組み込み分類子にLinux カーネルログがあったので
これを利用してAthenaにテーブルを作成しようと思います.
Glueクローラにアクセスしてcreate crawlerをクリックします.
S3の設定は, 下記のようにsecureログを設定してます.
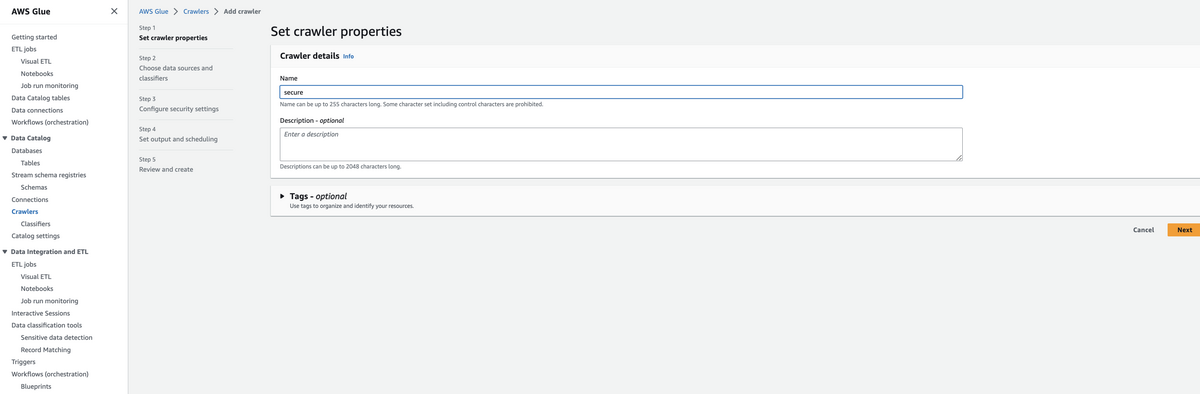
Add a datasourceをクリックして下記図のように設定して進んでいってください.
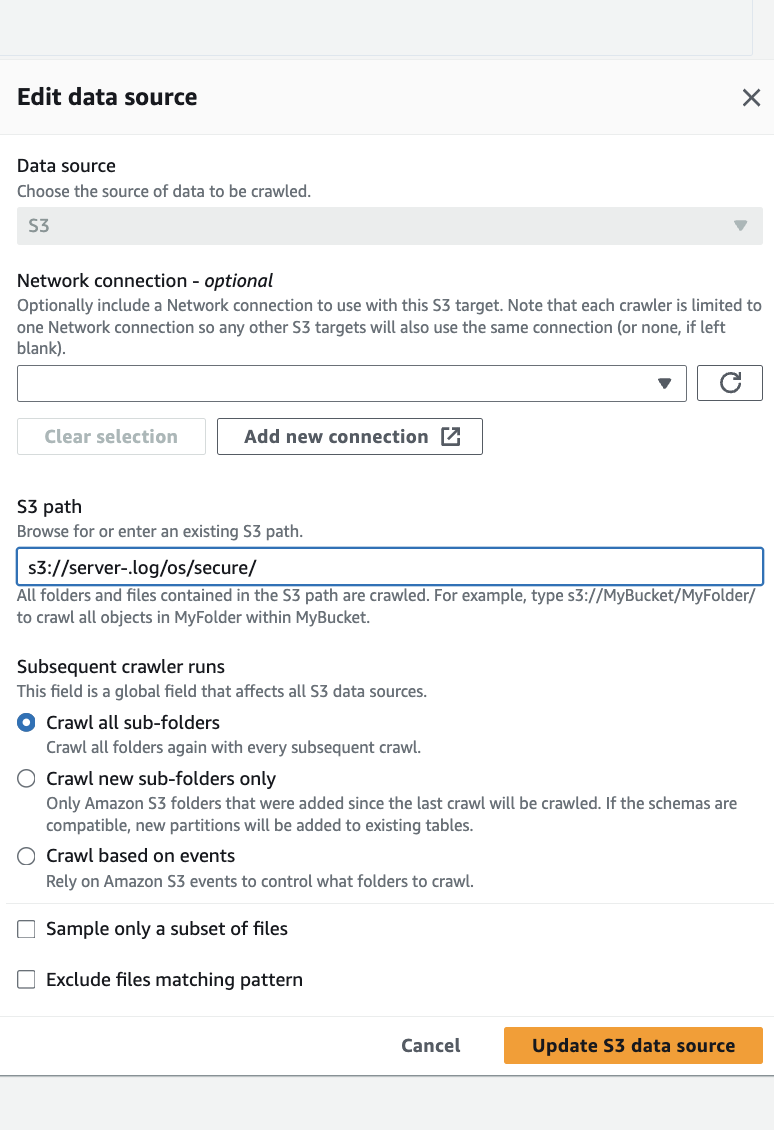
その後, IAMを設定して, Target databaseをlogsに変更するとGlueクローラの作成が完了です.
実行してみましょう.
すると,下記のようにAthenaにテーブルができているはずです.
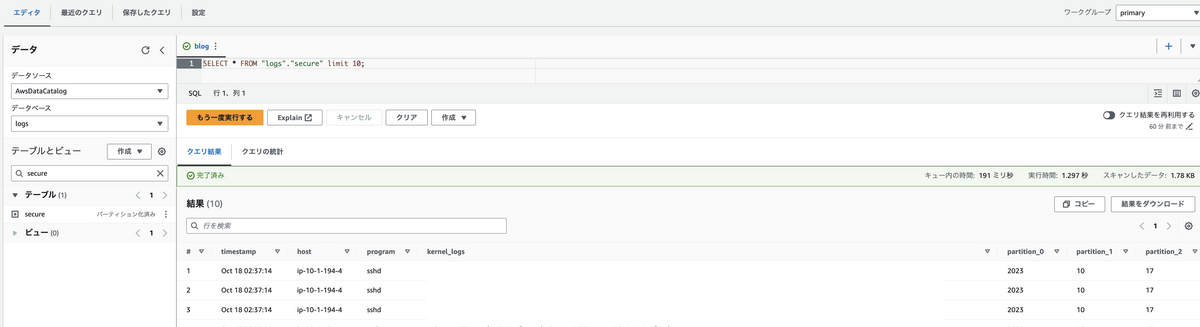
しかし現在のままでは, パーティションがpartition0, 1, 2であったり, 新規データの取り込みにはglueクローラを実行する必要があったりします.
カラム名を扱いやすく変更しつつ, パーティション射影を利用しましょう.
Data Catalog tablesに行くと先ほど作成されたテーブルがあります.
これを編集していきます.

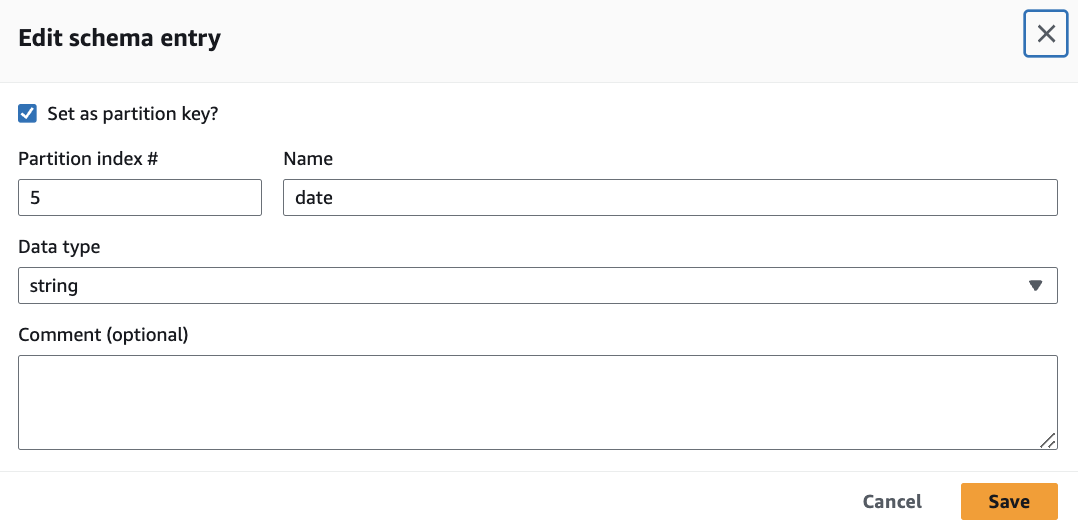
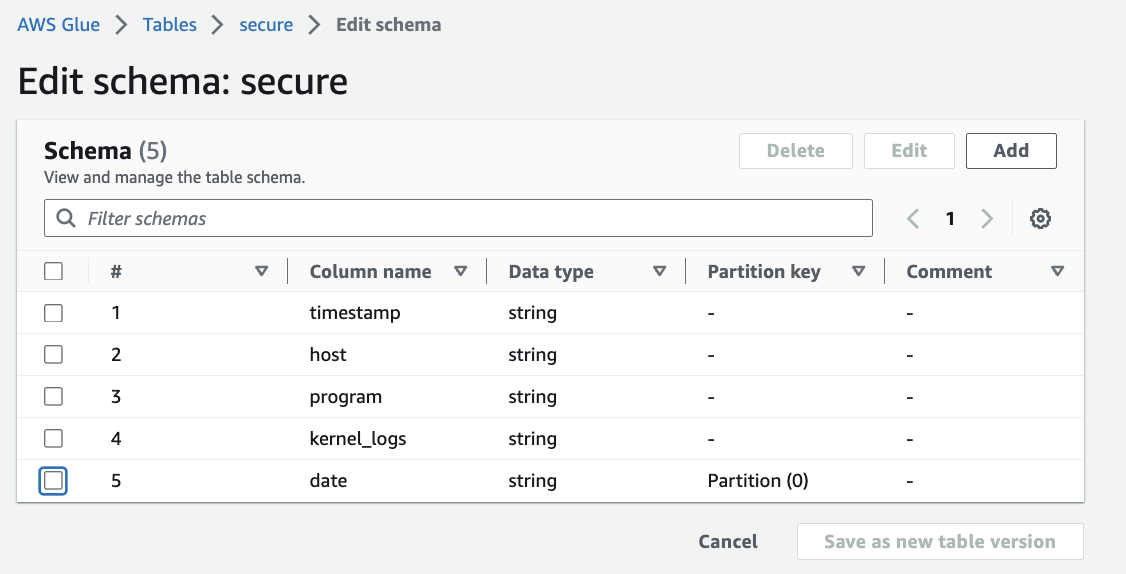
partition_0, partition_1, partition_2のパーティションの削除をします.

partition_0, partition_1, partition_2のカラムを削除して, 新しいパーティションカラム date 作成します.
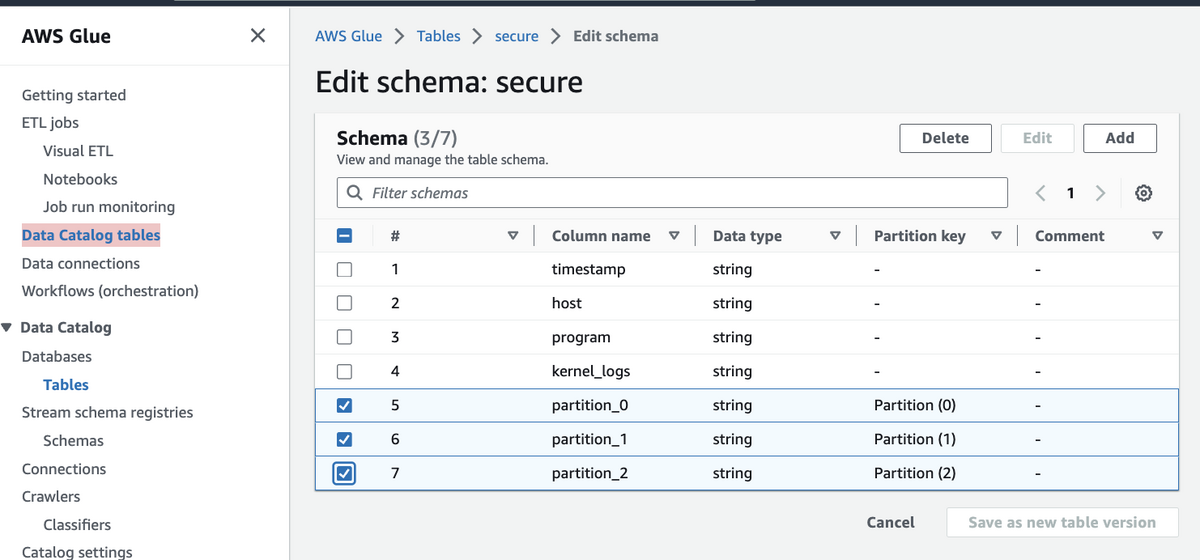
次に下記テーブルオプションの追記を行います.
- projection.enabled: true
- projection.date.type: date
- projection.date.range: NOW-1MONTHS,NOW
- projection.date.format: yyyy/MM/dd
- projection.date.interval: 1
- projection.date.interval.unit: DAY
- storage.location.template: s3://<S3-path>/${date}
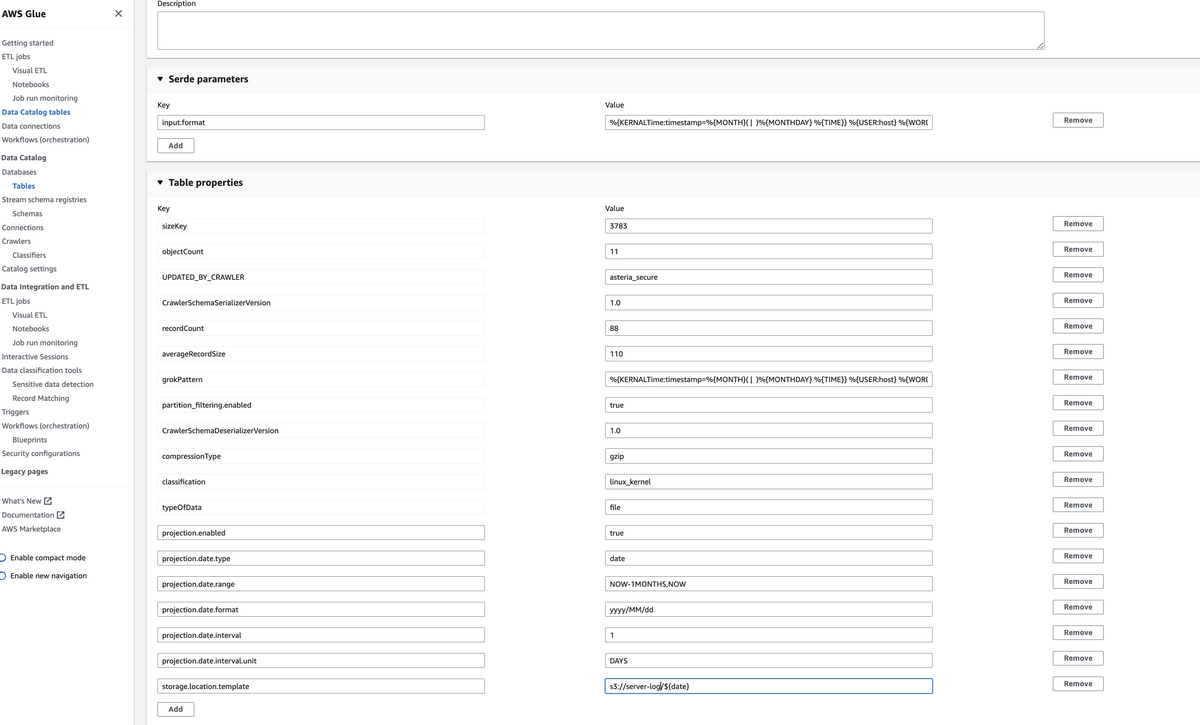
これで設定完了です!!
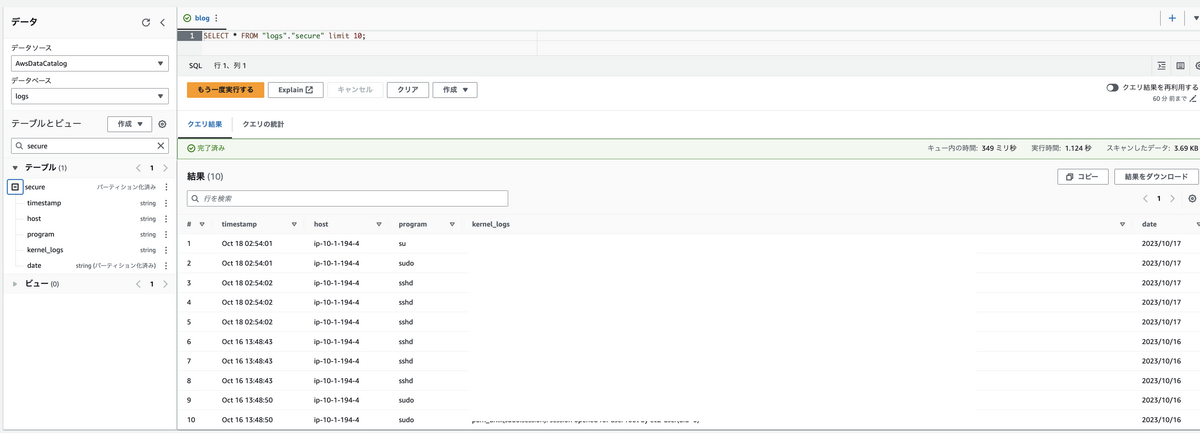
これで, dateでパーティションされているかつ, 射影パーティションを利用したテーブルになりました.
実際に見てみましょう.
正しく読み取れてますね.
以上で完了です!!!
まとめ
今回はAWSに構築したアプリケーションのログの設計から, 分析できる状態にすることまでのブログを書かせていただきました.
内容を振り返ると下記です.
- ログの保管場所はS3
- サーバー内のログのS3転送には, fluentbitを採用
- ログの分析には, GuardDuty, Glue, Athenaを使用
- 保管するログ及び保持期間は下記
- CloudTrail (データイベント)は, S3のサーバーアクセスログで代替可能
| ログ名 | 保管期間 |
|---|---|
| AWS: CloudTrail (管理イベント) | 5年 |
| AWS: CloudTrail (データイベント) | 5年 |
| AWS: VPCフローログ | 1ヶ月 |
| AWS: ALBのアクセスログ | 1年 |
| AWS: NLBのアクセスログ | 1年 |
| OS: /var/log/messages | 5年 |
| OS: /var/log/secure | 5年 |
| APP: 監査ログ | 5年 |
| APP: アクセスログ | 5年 |
GuradDuty, Athena, Glue, S3とAWSは便利なサービスが多いですね!!