はじめに
こんにちは。21卒エンジニアのなかむーです。二年目になりました。
この記事では、私が一年目の最後に行った集大成のタスクである、社内システムを1から全てクラウド移行した話について書いていこうと思います。タスクの遂行を通して学んだエンジニアとしてのスキルやマインドをお伝えできればなと思います。
特に今新卒エンジニアとして頑張っている人や、新卒エンジニアの教育に携わっている人たちに読んでいただけると嬉しいです。
約5ヶ月ほどのプロジェクトだったので、長文になりました。
背景
このタスクが渡される前(2021年9月頃)、私はチームのエンジニアとして所属しながら以下のような課題感を抱えていました。
- チームのスプリントゴールに関わるメインのタスクではなく、細かいタスクばかりをこなしていた
- メインのタスクは、期限が厳しかったり技術的に当時の自分ではサクッとこなすのが困難なものが多かった
- 加えて、チームのタスクの特性として、毎週のように扱う技術や範囲が変わるため、体系的に経験を積むことが困難だった
- 技術が身についている感じがしなかった
- 要するに、タスクを優先度順に上からとっていって消化していくという、メンバーの一員としての動きができていなかった
- 新卒エンジニアから一エンジニアになるには何が足りないのか?を模索していた
- 技術や調べ方といったスキル的な部分に加え、何かマインド的な部分でも変化が必要なのでは?と思っていた
これらの課題感をチームの振り返りで伝え、教育を兼ねた中規模のタスクが振られることとなりました。今回紹介する話はその中で二つ目に行ったものです。
やったこと(概要)
教育用タスクとして振られたのは、社内システムの一つであるLP管理システムのサーバーをAWSへ移行するというものでした。
LP管理システムとは、LP(ランディングページ)をデザイナーや営業の方が管理・配信するためのシステムです。 LPの登録・編集・削除・配信予約・LPデータのダウンロードなどを行うことができます。
当初は現状の仕様把握と設計の図面を書くところまででがゴールでしたが、やっているうちに最後までやり切りたいと思うようになったので、最後までやり切る道を選びました。
構築と手順・構成のコード化に加え、構築の最中に気づいた改善ポイントのアプリケーション改修まで行いました。
やったこと(詳細)
実際にかかった期間と、それについて苦労したことや学びを書いていきます。
現状の仕様把握 (2 weeks)
このシステムは所属している部署内でも詳しい人が数人しかおらず、ドキュメントも古いままだったため設計をする前に現状の仕様把握をする必要がありました。
具体的には、どんなプロセスやミドルウェアがサーバー内で動いているかを調べるため、実際にシステムを触ってみたりサーバー内でコマンドを叩いたりしました。ps, grep, find, netstat, lsofといったよく調査に使うコマンドやそのオプションはこの段階で手に馴染みました。
調べて分かったことは、最終的にmiroで図面にしてまとめました。リクエストやデータの流れを、どのポートを経由しているかなど含めて詳細に書き起こしました。
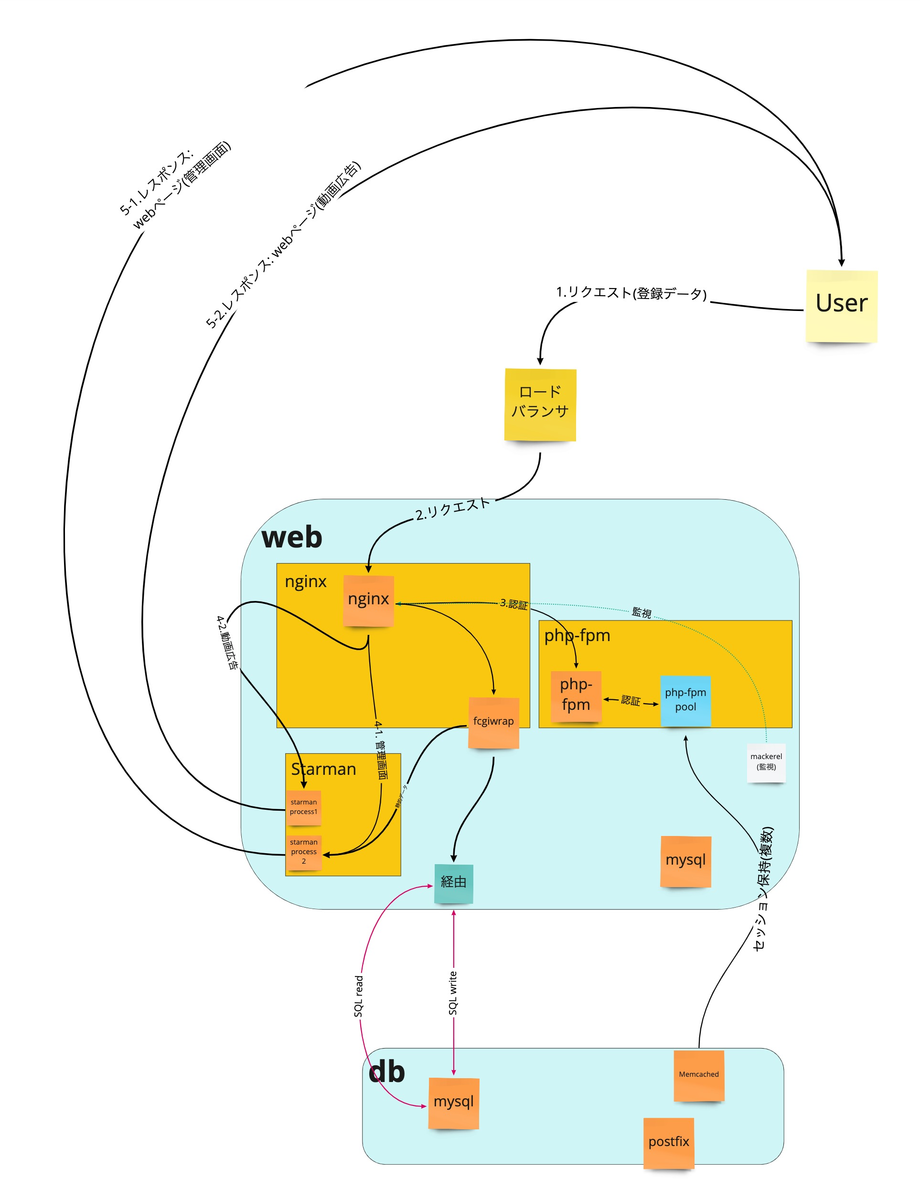
仕様把握の段階で書いた構成図です。 矢印がデータ・リクエストの流れ、濃いオレンジの付箋がそれぞれのポートごとにうごいているミドルウェアです。まとめるのが一苦労でした。
ここで学んだスキルは、図を書くことです。
図を書くことは自分の頭の整理になると同時に、その理解を他人に伝える手段にもなります。仕様把握や設計のみならず、この後の構築の途中で詰まった時も図を書くようになりました。
設計 (2 weeks)
現状からAWSに移行するにあたって、どのような構成で移行すると「良い」か?を考えました。
ここでいう「良い」とは様々な意味を含みますが、主に意識したのは以下のような点です。
- 運用コストは減らしたい
- 一つのサーバに複数の役割が割り当てられている部分があるため、分離したい
- メリットのわかっているAWSのマネージドサービスは積極的に取り入れていきたい
- 移行コストは減らしたい
- アプリケーションコードの改修はなるべくしたくない
- 構成の再設計も避けたい
- 上記を二つを満たすものの中で、料金はなるべく抑えたい
上記の点は最初からすぐ意識できたわけではなく、調査する中で移行案を何個か作ってみてブラッシュアップしたものです。また一度目のレビューで指摘された観点も取り入れつつまとめました。
一度目のレビューでは、「うーん、まだ詰め切れてないね。。。」と言われたのを覚えています。
ここで学んだマインドとしては、最終的にどこかの部分で妥協することになっても、気を配った・意識を向けた上でその設計を自分で(あるいはチームで)選んだというのが重要だということです。
純粋な技術的な部分ではベストプラクティス(あるいはアンチパターン)というのは存在するものの、実際に立ち向かう問題はどこか少しずつそれとは異なった事情や背景を抱えていることが多いです。そういう時に、自分なりに考えた上で選んだ(選ばなかった)理由を言えるようになっておくのが重要だと思いました。
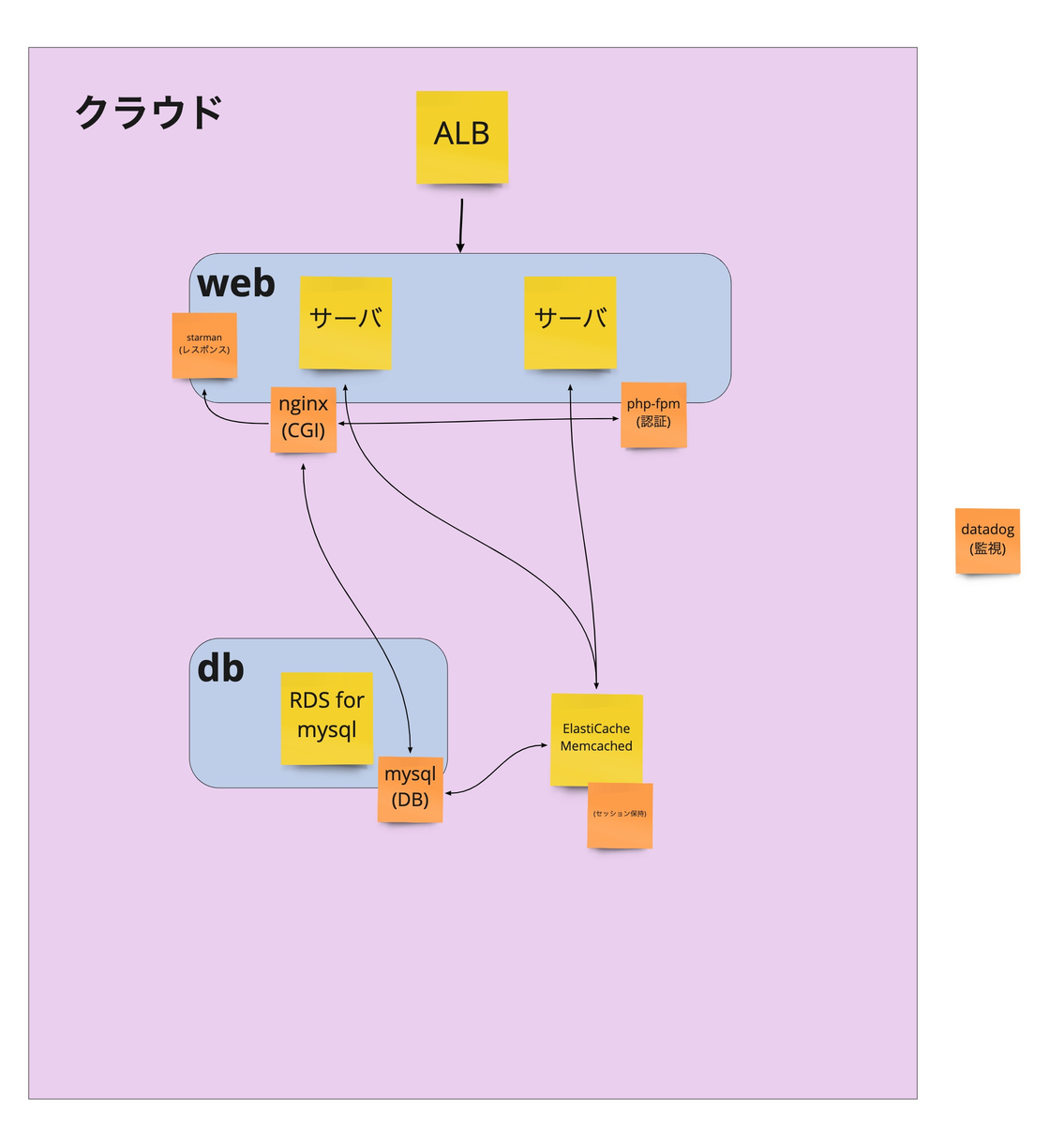
移行後の設計の構成図です。 ロールごとにサーバが分けられ、シンプルな構成になりました。
手動構築→Ansible (1.5 months)
作るものが決まったので、構築に入りました。手動構築に一ヶ月ほど、その構築手順をAnsibleコード化するのに2週間ほどかかりました。
Perlのモジュールを入れたり、Nginxのバージョンを少し上げたら設定ファイルがエラーを吐くようになっていたのでそれを修正したりするのにとても苦労しました。エラーを検索すれば解決するようなものもあれば、https://metacpan.org/ のような公式ドキュメントにまで当たって読み込まないと分からなかったりするようなものもありました。
Ansibleの経験はあったため、一度手動構築ができてしまえば大きく苦労することはありませんでした。ただ、今までと違いLP管理システム独自のミドルウェアのインストールの手順があり、初めてちゃんとroleを書く機会になりました。それにより、今まで既存のコードを参考になんとなく書いていてちゃんとは理解していなかった部分や概念(ex. host_vars, group_vars)の理解が進んだのはとても良かったと思います。
参考:Ansible インベントリーの構築方法
https://docs.ansible.com/ansible/2.9_ja/user_guide/intro_inventory.html
ここで学んだスキルとしては、公式ドキュメントなどの一次情報にきちんと当たるということです。
公式ドキュメントは求めているhowが書いていないことが多く、現在抱えている課題に対して即解決するようなものではないのですが、その分whatを根本から抑えることができる(+よくある使い方くらいなら書いてある)ので、どうもピンときてないなと思ったらまず必ず抑えるようになりました。
これをやっておかないと、似たようなエラーに出会った時に根本の現象・原因を理解していないためまた時間がかかってしまうようになります。
全体レビュー後修正 (1 month)
この辺りで年が明けました。
構築手順のコード化を終え、全体レビューを行ってもらいました。移行漏れがあった部分の追加の作業をしていました。具体的には、Datadog監視の追加、バックアップスクリプトのcrontabの移行、データを移したはずなのになぜか配信されていないLPの原因調査などをしました。
自分でLP配信が既存環境と同じか確かめるテストを書いたり、調査のためのNginxログ解析用のshellを書いたりしていました。ここまでの経験で、小さなツールを作ったりするのは自分は結構好きだということに気づいたので、手間を省略するために手を動かすのは積極的に行っていこうと思いました。
ここで学んだマインドとしては、「これ楽にできないかな?」と立ち止まって考える癖ができたことです。
ここまでで一通りメインの構築手順は終わっているため、このフェーズで出会う現象は調査からじっくり必要なものが多かったです。使える道具を増やしつつ試行錯誤する期間が長かったので、副反応として時間は当初の予定よりかかってしまいました。しかし、焦らず一つ一つ問題に向き合って潰していく経験ができました。
リリース (2 weeks)
ようやく残りの移行が終わり、デザイナーの人にリリースの時間帯に使わないよう調整してもらいました。
しかし、リリースの前々日の夕方くらいにセッションがすぐ切れるエラーが見つかり、延期するようになりました。オンプレの時代にはMemcachedで行っていたセッション管理をElastiCache(Memcached)に移行しており、その部分に詳しくなかったのでまた調査から行いました。
なので2週間もかかっています。
リリース後にバグが見つかる方が面倒なので、リリースが遅れるかすり傷で済んだとチームの人に慰められたのを覚えています。
構成のコード化:Terraform (2 weeks)
リリースも無事終わったので、構成をコード化しました。今回は構築後の構成のコード化にあたるため、単純にコード化するだけなら terraform import するだけで終わるものでした。
ですが、私のチームが主に管理しているTerraformのリポジトリでは、必要なところのmodule化が少しずつ進んでいました。そのため、勉強も兼ねてLP管理システム関連のリソースをmoduleに閉じるリファクタリングをしました。
参考: Terraform Creating Modules
https://www.terraform.io/language/modules/develop
書き方がわからない時は、チームの人に聞いたり公式が出しているTerraform AWS modulesのコードを読んで参考にしました。
参考: Terraform AWS modules
https://github.com/terraform-aws-modules
ここで学んだスキルとしては、小さなサブディレクトリを掘って試行錯誤はその中で試すということです。インフラは特に作ってみるまでわからないことが多いので、小さく作って試す過程が重要になります。また、実際に書こうとして困ってみて、初めて体得できる概念があるなということに気づきました。
その後: アプリケーション改修 (2 weeks)
クラウド移行としてはリリースで終了しているのですが、構築してきた中で見つけた改善ポイントを自分で改修しました。具体的には、LPのダウンロード機能の中で作られるzipファイルが各サーバに依存する状態(ステートフル)になっていたため、Amazon S3にあげてステートレスにするようにしました。
この頃には、LP管理システムに対してオーナーシップが生まれていました。(マインド)
デザイナーの人から問い合わせが来た時なども、自分が移行したものなのでいち早く反応するように自然になっていました。
まとめ
今回の約5ヶ月にわたる一大プロジェクトにより、仕事の質が上がり、スキル・マインド両面において多くの学びを得ることができました。以下にまとめます。
- スキル面
- 図を書く
- 公式ドキュメントなどの一次情報にきちんと当たる
- 小さく作って試す
- マインド面
- 様々な部分に気を配った・意識を向けた上で設計を選ぶ
- 「これ楽にできないかな?」と立ち止まって考える
- システムに対するオーナーシップ
特に、最後に述べたシステムに対するオーナーシップは、与えられた通常業務をただこなしているだけではなかなか得にくい大きなマインド面での変化だったと思います。
また、様々なツール・ミドルウェアでの試行錯誤を通して、焦らず落ち着いて目の前の現象と向き合い、もっと効率よくできないか?と立ち止まって考える姿勢ができました。他にも、そもそもAmazon ElastiCacheとはなにか?という大雑把な問題から実際に構築している時に当たる細かい問題まで、様々な粒度の調査・対応の経験を積むことができたことで大きく成長することができたと思います。
最後に、この記事が新卒エンジニアからエンジニアになるためのステップの参考になれば嬉しいです。