 つぶやきを解析すれば自分の肉指数も一目瞭然...?
つぶやきを解析すれば自分の肉指数も一目瞭然...? こんにちは、インフラ担当の金谷です。
少し前の話になりますが、今年6月のInterop Tokyoで「Splunk」(スプランク)というログ解析ソフトウェアの存在を知りました。
製品紹介がまさかの英語プレゼンテーション(通訳無し)でしたので、かなり想像を効かせた意訳になりますが、「膨大なログを一元管理してググるように解析できる...らしい」という特徴に興味を持ち、フリートライアル版もあるという事で、個人的にちょっと試してみました。その内容を「概要からインストールまで」と、「基本的なログ分析」の2回に分けてお送りしたいと思います。
ちなみに、Splunkは本来テラバイト(TB)級のログ解析で真価を発揮するようですが、よくよく考えてみたら個人で解析にふさわしいようなデータなど全く持ち合わせていません。そこで今回は、少し体を張って(?)自分のTwitterアーカイブをインプットデータとして試してみました。(1万件未満の単一のログデータなので、果たしてSplunkの良さを実感できるのかかなり怪しいのですが...)
■Splunkの概要
- Splunkってなに?
データ分析のプラットフォームで、様々なサーバ・ネットワーク機器・アプリケーション等が出力するログを、横断的に1箇所(Splunkのマネージ画面)から解析することが出来ます。検索にはSPLというサーチ処理言語を使うのですが、初めてSPLに触れてみた印象としては「Webでググる」のと「SQLでデータベース検索」する操作の中間的な印象を持ちました。
余談ですが、「Splunk」という名前は「spelunk」(洞窟探検)をもじったものだそうで、ファミコン世代の人間には親しみやすい名前だったりします。
- おおまかな流れ
フェーズ1.データを収集する
フェーズ2.データを回答が得られる情報に整形する
フェーズ3.データをビジュアル化またはレビューして考察する
■インストール(MacOSの場合)
1. ja.splunk.com よりSplunk(tar)をダウンロードし、適当な場所で展開する。
2. ターミナルを開き、展開したsplunkのサブディレクトリ"bin"に移り、"./splunk start"する。
これだけです。あとは、インストール終了時に表示されるローカルのURL(8000番ポート)にアクセスすると管理画面が出てきます。
■セットアップ
- フェーズ1.データ収集
管理画面からデータを取り込みます。
また、ローカルファイル以外にも遠隔に保存されているファイルを読み取ったり、Splunkでポートリッスンしてログを待ち受ける形でリアルタイムにインプットすることも出来るようです。
- フェーズ2.データ整形
これも今回のTwitterアーカイブはCSVファイルで素直な形式でしたので、Splunkが自動的にタイムスタンプを読み取ってくれました。イベントの区切りが不明な場合(改行位置が読み取れない場合など)は、ここで手動で区切ってあげることになるようです。
なお、ファイル先頭のヘッダ行もデータとして取り込まれてしまったようで、タイムスタンプが無いという警告が出ていましたが、この辺りは回避策があるのか気にしなくても良いのか不明でしたので、今回はそのまま先へ進みました。ご存知の方いらっしゃいましたら教えてください。
- フェーズ3.データ分析
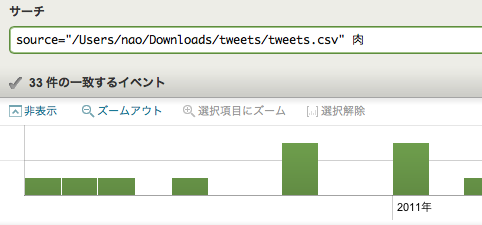
ここから先は次回になります。とは言え、きちんとインプットが完了しているのか不安なので、サーチ画面を覗いて適当に検索ワードを入れてみたのが記事先頭の画像になります。大丈夫なようですね。
次回は、SPLでどんな検索や分析が行えるのかを中心にまとめてみたいと思います。
それではまた!
それではまた!